Windows-31J と JIS X 0213 の共用
文字コードに関する昨日のつぶやき
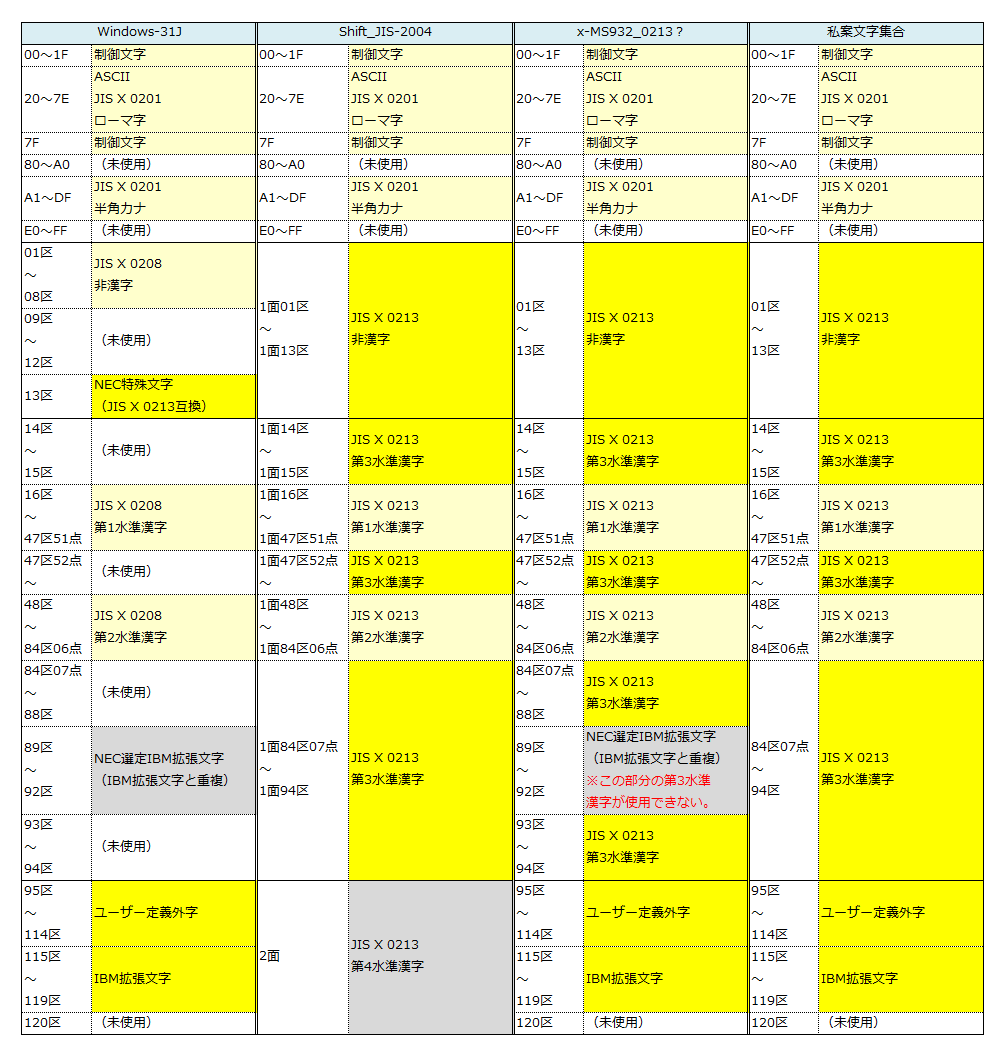
文字コードの話。NEC選定IBM拡張漢字を捨てれば、Windows-31J と JIS X 0213 の第3水準漢字が両立できるなと思ったけれど、Java で x-MS932_0213 を試してみたら、89区をNEC選定IBM拡張漢字にマッピングしていて、使えねぇなと思った。
— GLAD!! (@glad2121) 2016, 2月 16
JIS X 0213 の非漢字、第1〜第3水準漢字、Windows-31J の NEC特殊文字、IBM拡張文字、ユーザー定義外字を文字集合とした、エンコーディングがあると、互換性を保ちつつ標準化の方向性にも沿った拡張ができると思うんだけど。
— GLAD!! (@glad2121) 2016, 2月 16
これを図で表してみました。
x-MS932_0213 は第3水準漢字に使える文字と使えない文字があり中途半端。「NEC選定IBM拡張漢字」は「IBM拡張漢字」と重複しているから、領域を丸ごと第3水準漢字に明け渡して、いちばん右の文字セットを使うというのが、個人的にはいい案だと思うんですけどね。
2面は、第4水準漢字を使うより「IBM拡張漢字」と「ユーザー定義外字」を残した方が、互換性と拡張性の点でベターな気がします。JIS X 0213 推進者の人からは怒られそうですが…。
[Tech] ローカルファイルのタイムスタンプを SVN のコミット時刻にする
お客様先で SVN を導入したんだけど、既存ファイルのタイムスタンプを保持したいという要望が多かったので、ローカルファイルのタイムスタンプをコミット日時にするスクリプトを書いてみた。
実行前に、リポジトリの pre-revprop-change を変更して、リビジョンプロパティの変更を許可する必要があります。
あと、TortoiseSVN の「ファイルの更新日時を『最終コミット日時』に設定する」にチェックを入れておくと、チェックアウトしたときにファイルのタイムスタンプがコミット日時になります。
[Java][文字コード] Unicode 正規化と、文字列の正規表現と関数を用いた置換
Java の標準ライブラリに java.text.Normalizer という Unicode 正規化を行うクラスがあります。
濁点・半濁点を合成・分解したりするのに便利なのですが、JIS X 0208 の「Å(U+212B)」を「上リング付きA(U+00C5)」に変換したり、JIS X 0213 のギリシャ文字のαやεにアクセントが付いた U+1F71、U+1F73 を U+03AC、U+03AD に変換するなど、余計な変換を行うため、JIS のコードに戻せなくなってしまいます。
そこで、ひらがな・カタカナだけを正規化することができないか考えてみました。
正規表現でひらがな・カタカナを検索し、マッチした文字列だけ正規化します。
最初、合成と分解をそれぞれ実装したのですが、同じようなロジックになったので、Java8 の関数を用いて共通化してみました。
まず、文字列を正規表現で検索し、マッチした文字列を変換するメソッドを作成します。
/** * 文字列に含まれるパターンを関数を使って置換します。 * * @param s 文字列 * @param p パターン * @param f 関数 * @return 変換後の文字列 */ static String replaceAll( CharSequence s, Pattern p, Function<String, String> f) { Matcher m = p.matcher(s); int length = s.length(); StringBuilder sb = new StringBuilder(length); int index = 0; while (m.find()) { // マッチしなかった部分をそのまま追加。 sb.append(s.subSequence(index, m.start())); // マッチした部分を変換して追加。 sb.append(f.apply(m.group())); index = m.end(); } // 残りをそのまま追加。 sb.append(s.subSequence(index, length)); return sb.toString(); }
これを使えば、濁点・半濁点の合成・分解のコードは簡単に実装できました。
/** * 全角カナの正規表現。 */ static final Pattern FULLWIDTH_KANA = Pattern.compile("[\u3041-\u309A\u30A1-\u30FA]+"); /** * 文字列に含まれる基底文字と結合文字を合成します。 * * @param s 文字列 * @return 合成された文字列 */ static String composeFullwidthKana(CharSequence s) { return replaceAll(s, FULLWIDTH_KANA, (g) -> Normalizer.normalize(g, Normalizer.Form.NFC)); } /** * 文字列に含まれる合成済み文字を基底文字と結合文字に分解します。 * * @param s 文字列 * @return 分解された文字列 */ static String decomposeFullwidthKana(CharSequence s) { return replaceAll(s, FULLWIDTH_KANA, (g) -> Normalizer.normalize(g, Normalizer.Form.NFD)); }
[Java][文字コード] Java8 の非互換な文字コード変換
文字コード関連でちょっと調べていたら、未定義文字を変換したときの挙動が Java8 と Java7 までで異なることを発見したのでメモ。
Java7 まではネイティブコードの1文字が概ね U+FFFD 1つに変換される。
# 半角の未定義文字 1B284920 -> FF60 (ISO-2022-JP) 8EA0 -> FFFD (EUC-JP) A0 -> FFFD (Shift_JIS) A0 -> FFFD (windows-31j) A0 -> FFFD (x-SJIS_0213) # 半角の定義文字(参考) 1B284921 -> FF61 (ISO-2022-JP) 8EA1 -> FF61 (EUC-JP) A1 -> FF61 (Shift_JIS) A1 -> FF61 (windows-31j) A1 -> FF61 (x-SJIS_0213) # 全角の範囲外領域 1B24422120 -> FFFD (ISO-2022-JP) A1A0 -> FFFD (EUC-JP) 813F -> FFFD (Shift_JIS) 813F -> FFFD (windows-31j) 813F -> FFFD003F (x-SJIS_0213) # 全角の定義文字(参考) 1B24422121 -> 3000 (ISO-2022-JP) A1A1 -> 3000 (EUC-JP) 8140 -> 3000 (Shift_JIS) 8140 -> 3000 (windows-31j) 8140 -> 3000 (x-SJIS_0213) # 全角の未定義文字 1B24422271 -> FFFD (ISO-2022-JP) A2F1 -> FFFD (EUC-JP) 81EF -> FFFD (Shift_JIS) 81EF -> FFFD (windows-31j) 81EF -> 2194 (x-SJIS_0213) # 全角の未定義文字 1B24422321 -> FFFD (ISO-2022-JP) A3A1 -> FFFD (EUC-JP) 8240 -> FFFD (Shift_JIS) 8240 -> FFFD (windows-31j) 8240 -> 25B7 (x-SJIS_0213) # 全角の未定義文字 1B2442247E -> FFFD (ISO-2022-JP) A4FE -> FFFD (EUC-JP) 82FC -> FFFD (Shift_JIS) 82FC -> FFFD (windows-31j) 82FC -> FFFD (x-SJIS_0213)
# ISO-2022-JP の最初の変換はバグっぽいですが。
ところが、Java8 だと U+FFFD が1つだったり2つだったり、2バイト目が有効な文字だったら変換されたりと安定しない。
# 半角の未定義文字 1B284920 -> FF60 (ISO-2022-JP) 8EA0 -> FFFD (EUC-JP) A0 -> FFFD (Shift_JIS) A0 -> FFFD (windows-31j) A0 -> FFFD (x-SJIS_0213) # 半角の定義文字(参考) 1B284921 -> FF61 (ISO-2022-JP) 8EA1 -> FF61 (EUC-JP) A1 -> FF61 (Shift_JIS) A1 -> FF61 (windows-31j) A1 -> FF61 (x-SJIS_0213) # 全角の範囲外領域 1B24422120 -> FFFD (ISO-2022-JP) A1A0 -> FFFD (EUC-JP) 813F -> FFFD003F (Shift_JIS) 813F -> FFFD003F (windows-31j) 813F -> FFFD003F (x-SJIS_0213) # 全角の定義文字(参考) 1B24422121 -> 3000 (ISO-2022-JP) A1A1 -> 3000 (EUC-JP) 8140 -> 3000 (Shift_JIS) 8140 -> 3000 (windows-31j) 8140 -> 3000 (x-SJIS_0213) # 全角の未定義文字 1B24422271 -> FFFD (ISO-2022-JP) A2F1 -> FFFD (EUC-JP) 81EF -> FFFD (Shift_JIS) 81EF -> FFFD (windows-31j) 81EF -> 2194 (x-SJIS_0213) # 全角の未定義文字 1B24422321 -> FFFD (ISO-2022-JP) A3A1 -> FFFD (EUC-JP) 8240 -> FFFD0040 (Shift_JIS) 8240 -> FFFD0040 (windows-31j) 8240 -> 25B7 (x-SJIS_0213) # 全角の未定義文字 1B2442247E -> FFFD (ISO-2022-JP) A4FE -> FFFD (EUC-JP) 82FC -> FFFD (Shift_JIS) 82FC -> FFFDFFFD (windows-31j) 82FC -> FFFD (x-SJIS_0213)
未定義文字なので大きな問題にはならないかもしれないけれど、こういう非互換は勘弁してほしいなぁ…。
参考までに、チェックに使った環境とソースコードは以下の通り。
続きを読む[DDD] 酔っぱらいの戯れ言
Eric Evans の Domain-Driven Design

- 作者: Eric Evans
- 出版社/メーカー: 翔泳社
- 発売日: 2013/11/20
- メディア: Kindle版
- この商品を含むブログ (8件) を見る
は、アーキテクチャの本であって、ドメイン分析の本じゃない。
本当に DDD やりたいなら、以下の本も読むべし。
- Fowler「アナリシスパターン」
")
アナリシスパターン―再利用可能なオブジェクトモデル (Object Technology Series)
- 作者: マーチンファウラー,Martin Fowler,堀内一,友野晶夫,児玉公信,大脇文雄
- 出版社/メーカー: ピアソンエデュケーション
- 発売日: 2002/04
- メディア: 単行本
- 購入: 7人 クリック: 89回
- この商品を含むブログ (70件) を見る
- Coad「カラーUML」

Javaエンタープライズ・コンポーネント―カラーUMLによるJavaモデリング
- 作者: ピーターコード,ジェフデ・ルーカ,エリックレイフェイブル,Peter Coad,Jeff De Luca,Eric Lefebvre,依田光江,依田智夫,今野睦
- 出版社/メーカー: ピアソンエデュケーション
- 発売日: 2000/09
- メディア: 大型本
- クリック: 1回
- この商品を含むブログ (10件) を見る
- Hruby「ビジネスパターンによるモデル駆動設計」

- 作者: Pavel Hruby,依田智夫,溝口真理子,依田光江
- 出版社/メーカー: 日経BP社
- 発売日: 2007/08/09
- メディア: 単行本
- クリック: 7回
- この商品を含むブログ (15件) を見る
- 佐藤正美「T字型ER」

- 作者: 佐藤正美
- 出版社/メーカー: ソフトリサーチセンター
- 発売日: 1999/01
- メディア: 単行本
- 購入: 2人 クリック: 36回
- この商品を含むブログ (10件) を見る
- ドメイン分析で重要なのは、Entity と Value の識別じゃなくて、Entity の深掘り。
- Fowler の Service Layer は重要な概念だったのに、Evans がその他オブジェクトに Service って名前をつけたのは犯罪的。
- 同じく、Evans の Value は Fowler の言う Value じゃなく、単なるデータクラス。
- ピュアなオブジェクト指向の「もの(マスター系)」偏重、「こと(イベント系)」は関連で表すはダメ。「こと」があってこそ「もの」の要件が決まる。どちらもオブジェクトにすべき。
- とは言え、ドメインによっては、Value が Entity になったり、「もの」が「こと」になることも。
- 「知識レベル」「操作レベル」と「もの」「こと」は直交する。「ものの知識レベル」も「ことの知識レベル」もある。
そんなわけで、DDD は必要だと思うけど、Evans の DDD はどうも好きになれない。
(by Fowler まんせーおじさん)
なんか昔も同じような話書いてた。(^^;)
http://d.hatena.ne.jp/aufheben/20090501
[Tech] MacBook Air 設定メモ
昨年末、初めて Mac を購入しました。
備忘録として、設定のメモと参考にしたサイトを残しておきます。
基本設定
Homebrew & Scala
- Subversion
- Git
- Scala
- Play2
その他
- eclipse-jee-juno-SR1-macosx-cocoa-x86_64
- Subversive、EGit
- Maven Integration
- eclipse-jee-indigo-SR2-macosx-cocoa-x86_64
… Scala IDE が Juno に未対応のため。- Subversive、EGit
- Maven Integration
- Scala IDE
- MuleStudio-CE-for-macosx-64bit-1.3.2-201212121943
- netbeans-7.2.1-ml-javaee-macosx
- Haskell Platform 2012.4.0.0 64bit
- VirtualBox-4.2.6-82870-OSX