gnuplot のテキスト端末出力と、Emacs 連携
ソフトウェアの性能や安定性の懸賞のために、なんらかのテストを行い、結果をグラフ化することがあります。昔からソフトウェア屋に限らず幅広く利用されている gnuplot というグラフの出力ツールがあります。グラフ書く以外にも色々と機能があるみたいなのですが、先日ふと知ったテキスト端末出力が便利だったので、メモがわりのエントリを。
グラフをテキスト端末にアスキーアートで出力すると、チャットやチケットにコピペでき、テスト結果の共有が簡単にできました。最終的には綺麗なグラフを書く必要がある場合も多いでしょうが、速報や要約の目的でケースバイケースで使いわけると便利です。
参考
- gnuplot のホームページ gnuplot homepage
- 日本語マニュアルもある http://www.gnuplot.info/documentation.html
- Emacs gnuplot-mode http://xafs.org/BruceRavel/GnuplotMode
- Emacs gnuplot-mode の日本語での簡易説明 http://homepage1.nifty.com/fin/soft/emacs/gnuplot-mode.html
gnuplot のインストール
私は MacPorts を使っているので port コマンドでインストールしました。
たいていのプラットフォームではパッケージがあることでしょう。
$ sudo port isntall gnuplot
MacPorts では依存で AquaTerm (http://sourceforge.net/projects/aquaterm/) もインストールされます。
後に説明する端末設定で MacOSX では AquaTerm も利用可能です。
gnuplot の実行と、テキスト端末出力
インストールはすぐ終わりましたが、このエントリの主目的であるテキスト端末出力も3行で終わります。
コマンドラインで gnuplot を実行して、2つの gnuplot コマンドを実行しましょう。
$ gnuplot
gnuplot> set terminal dumb gnuplot> plot sin(x)
はい、終わり。これでお使いの端末にこんなかんじのグラフが出力されたはずです。
1 ++---------------***---------------+---**-----------+--------**-----++
+ * * + * ** + sin(x) ****** +
0.8 ++ * * * * * * ++
| * * * * * * |
0.6 *+ * * * * * * ++
|* * * * * * * |
0.4 +* * * * * * * ++
|* * * * * * * |
0.2 +* * * * * * *++
0 ++* * * * * * *++
| * * * * * * *|
-0.2 ++ * * * * * * *+
| * * * * * * *|
-0.4 ++ * * * * * * *+
| * * * * * * *
-0.6 ++ * * * * * * +*
| * * * * * * |
-0.8 ++ * * * * * * ++
+ * * + ** * + * * +
-1 ++-----**--------+-----------**----+--------------***---------------++
-10 -5 0 5 10見事なサインカーブ!
説明するまでもないですが、 set terminal コマンドを使って、出力先を dumb に設定しています。この出力先はアスキーアートで出力を表示します。詳しくは日本語の PDF マニュアルを見ると良いでしょう。
最初からテキスト端末を出力先に指定するには、~/.gnuplot を作って、コマンドを実行させます。
set terminal dumb
大きさの設定
set terminal コマンドのオプションで、出力する大きさの設定ができます。
例えば、次のようなコマンドで、チャットに貼りやすそうな、ちょっと小さめに出ます。
set xrange [0:2*pi] set yrange [-1.4:1.4] set terminal dumb 50 20 # small plot sin(x)
表示の際は、軸の刻み(tick)がグラフと重なると見にくいので、ちょっと range を広めに取るのが良さそうです。
結果は次の通り。
+-----+------+-----+-----+------+-----+-+
+ + + + +sin(x)+****** |
1 ++ ***** ++
| ** *** |
| ** ** |
0.5 ++ ** * ++
|** ** |
0 ** ** +*
| ** **
| ** **|
-0.5 ++ * ** ++
| ** ** |
| *** ** |
-1 ++ ***** ++
+ + + + + + + |
+-----+------+-----+-----+------+-----+-+
0 1 2 3 4 5 6
Emacs gnuplot-mode.html
メモついでに Emacs の gnuplot インターフェースを。
Emacs のメジャーモードとして gnuplot-mode があり、とても便利です。MacPorts で入れた場合、 /opt/local/share/emacs/site-lisp/gnuplot.el[c] に入ってました。CarbonEmacs の場合は、最初から入ってます。
簡単には、gnuplot のコマンドをファイルに書いておいて、行や範囲指定で実行する、というだけです。それだけでも、 gnuplot はパラメータをちょこちょこ変えながら実行するので、地味に効きます。
ファイルの拡張子は、 *.gp にすると初期設定で有効になるようです。
コマンドは予め定義されている2つと、自分定義の1つ(しか使ってない)。
- C-c C-l
- ポイントのある行のコマンドを実行する
- C-c C-r
- 選択された範囲のコマンドを実行する
- C-c C-p
- 再描画 (replot)
個人的には同じプロットコマンドで再描画をよく使うので、次のように定義しています。
(defun gnuplot-send-replot-to-gnuplot () "Sends replot to gnuplot" (interactive) (gnuplot-send-string-to-gnuplot "replot\n" 'line) ) (define-key gnuplot-mode-map "\C-c\C-p" 'gnuplot-send-replot-to-gnuplot)
これで、Emacs の中で gnuplot のコマンドを編集して、実行でき、さらにテキスト端末出力の場合は、gnuplot 出力のバッファへグラフも出力されるため、Emacs の中で結果確認までできます。
basho_bench のインストールと準備の手順紹介
Riak の開発、サポートを行なっている Basho Technologies, Inc. が basho_bench というベンチマークツールを公開しています。
Basho Bench is a benchmarking tool created to conduct accurate and repeatable performance tests and stress tests, and produce performance graphs.
Basho: Benchmarking with Basho Bench
github.com のリポジトリ: https://github.com/basho/basho_bench
Riak 自体のベンチマークに加えて、ドライバを自作すれば簡単にベンチマークを取得することが可能です。
例えば、Hibari のドライバが basho_bench のソースツリーに含まれていますが 300 行程度で書かれています。
利点、特徴をパラパラと。
- ベンチマーク結果として、スループットとレイテンシのグラフを生成できる
- 複数の操作を、混在させたベンチマークが取れる
- 例: READ を 80% + WRITE を 20 %
- ランダムな値を生成してくれる
- ランダムなキーと値で WRITE 操作、というのが簡単にかける
- 1回の試行ごとに、設定ファイルと実行結果を個別ディレクトリに保存してくれる
- 並列度を指定できる
以下、インストールから、サンプル実行、結果のグラフ生成までの手順メモです。
basho_bench 自体のインストール、ビルド
$ git clone https://github.com/basho/basho_bench.git $ cd basho_bench $ make all
この段階で、ベンチマークは実行可能です。basho_bench のサンプル設定を元に、あまり時間がかからない設定にしてみます。
$ cp example/null_test.config . $ vi null_test.config
{mode, max}. {duration, 1}. {concurrent, 1}. {driver, basho_bench_driver_null}. {code_paths, ["deps/stats"]}. {key_generator, {uniform_int, 1024}}. {value_generator, {fixed_bin, 1024}}. {operations, [{put, 1}]}.
ベンチマーク自体の実行は、./basho_bench を実行します。
$ ./basho_bench null_test.config $ ls tests/current # テスト結果が格納されるディレクトリ
結果グラフを生成してみようとすると...
$ make results priv/summary.r -i tests/current env: Rscript: No such file or directory make: *** [results] Error 127
エラーが発生します。R のインストールと設定を行いましょう。
R のインストール、設定
Mac OS X ではバイナリパッケージがある。楽なのでパッケージを使います。
R for Mac OS X
http://cran.r-project.org/bin/macosx/R-2.12.1.pkg をダウンロード、インストール。
$ make results priv/summary.r -i tests/current Warning: unable to access index for repository http://lib.stat.cmu.edu/R/CRAN/bin/macosx/leopard/contrib/2.12 Warning: unable to access index for repository http://lib.stat.cmu.edu/R/CRAN/bin/macosx/leopard/contrib/2.12 Warning messages: 1: In library(Name, character.only = TRUE, logical.return = TRUE) : there is no package called 'getopt' 2: In getDependencies(pkgs, dependencies, available, lib) : package ‘getopt’ is not available 3: In library(Name, character.only = TRUE, logical.return = TRUE) : there is no package called 'ggplot2' 4: In getDependencies(pkgs, dependencies, available, lib) : package ‘ggplot2’ is not available Error: could not find function "getopt" Execution halted make: *** [results] Error 1
ライブラリが足りないとのエラーです。R のパッケージをインストールします。
R.app を起動して、[パッケージとデータ] メニューから、パッケージインストーラを選択。
このへん、コマンドラインでどうにかならんのかな。sudo で make results を実行するといけるっぽいけど、調べてない。
一覧を取得から、Japan(Tsukuba)を選択。
getopt, ggplot2, reshape, plyr, proto, digest をインストール。
R.app は終了させてかまいません。
$ make results $ open tests/current/summary.png
{kind=link}
以上、basho_bench のインストールと準備の手順紹介でした。
-
-
-
-
-
-
-
-
-
-
-
- -
-
-
-
-
-
-
-
-
-
-
追記
@kenji_rikitake にコマンドラインでもできると教えていただいたので、試してみたメモを追記。
いったんインストールしているパッケージを削除する。念のため、結果グラフ生成でエラーが発生することを確認。
$ R CMD REMOVE getopt ggplot2 reshape plyr proto digest $ make results % エラーになる
$ R CMD INSTALL getopt ggplot2 reshape plyr proto digest % エラーになる
R CMD INSTALL は tar.gz からのインストールらしい。CRAN からのダウンロードは別途必要。
参考: R Installation and Administration http://cran.r-project.org/doc/manuals/R-admin.html
R のシェルからのインストールでは、CRAN からのダウンロードもやってくれるため、そちらでやってみる。
まず、CRAN ミラーの設定。ホームの下に .Rprofile を作って、ミラーを設定する。
参考: CRAN国内ミラーの使い方 - RjpWiki http://www.okada.jp.org/RWiki/?CRAN%B9%F1%C6%E2%A5%DF%A5%E9%A1%BC%A4%CE%BB%C8%A4%A4%CA%FD
$ cat ~/.Rprofile options(repos="http://essrc.hyogo-u.ac.jp/cran/")
R を起動して、パッケージをインストールする。
$ R > install.packages(c("getopt", "ggplot2", "reshape", "plyr", "proto", "digest")) > q() % R シェルを終了させる
QuickCheck 最初の一歩 リストの逆順を写経
まずは写経。
準備としては、Quviq のサイトから eqc mini を落としてきて適当な場所に解凍するだけです。
http://www.quviq.com/news100621.html
最初の題材は、 Hughes さんのトーク
Functional Programming: A Secret Weapon for Software Testing.
John Hughes gives an invited talk at ICFP 2007 in Freiburg, Germany, showing from his company's experience how QuickCheck has found many obscure bugs in commercial software. *Even when the software under test is not written in a functional language.*
hughes_testing
のなかにある、リストの逆順操作。
単純すぎる例かもしれないけれど、連結操作との交換(といっていいのかな?)で逆順を定義する、というのはとてもシンプル。ちゃんと考えていないけど、これだけで帰納的に操作が定まっているのではないかと思う。
-module(first_samples). -include_lib("eqc/include/eqc.hrl"). -export([start/0]). %% 写経 %% http://video.google.com/videoplay?docid=4655369445141008672# start() -> eqc:quickcheck(prop_reverse_combination_mistake()), ok. %% こっちは失敗する。失敗入力がシュリンクされる prop_reverse_combination_mistake() -> ?FORALL({Xs, Ys}, {list(int()), list(int())}, lists:reverse(Xs ++ Ys) =:= lists:reverse(Xs) ++ lists:reverse(Ys)).
erlc -I ../eqc-1.0.1/include -pa ../eqc-1.0.1/ebin first_samples.erl
実行
$ erl -pa ../eqc-1.0.1/ebin -pa . -s first_samples -s init stop -noshell
Starting eqc mini version 1.0.1 (compiled at {{2010,6,13},{11,15,30}})
.................Failed! After 18 tests.
{[2,-2],[-5]}
Shrinking....(4 times)
{[0],[1]}アウチ。こけました。まぁコメントに書いてますね。
前回書いた、QuickCheck の手順を再掲。
- 入力をたくさん勝手に生成して、
- 何か処理したあとに、
- 不変性などのチェックを行う。
- そしてチェックが失敗したら、
- 入力をなるべく簡略化して失敗する入力を教えてくれる。
まず、実行結果2行目の Failed! までで、勝手に入力を生成してテストをしています。
「何か処理」と「チェック」はコードの prop_reverse_combination_mistake の中にあります。?FORALL マクロの第3引数がそこ。ただし簡単なので「何か処理」ってのは無く、すぐに性質(プロパティ)のチェックを行っています。
そして、18 テストをしたあとに失敗しました、と報告してくれています。その時の入力が
{[2,-2],[-5]}の部分です。
この後に、入力を簡略化して、なにがおかしいのかを人間に分かりやすくしてくれるプロセスが走ります。 Srinking.. とあるところです。結果として、入力のリストは1要素だけのリストであれば良い、という結果を出力しています。
このケースではそもそも結果が複雑ではありませんが、実際には重要なステップとなるところでしょう。このシュリンクするロジックも気になりますね。どうなってるんだろう。
本来であれば、ここで実装側のバグなのか、性質の定義がおかしいのかを判断するところです。今回は性質の定義が間違っているため、修正して正しい性質にします。
%% こっちは正しい性質 prop_reverse_combination() -> ?FORALL({Xs, Ys}, {list(int()), list(int())}, lists:reverse(Xs ++ Ys) =:= lists:reverse(Ys) ++ lists:reverse(Xs)).
比較の右辺で、入力のリストが逆になっているところがミソですね。
erl -pa ../eqc-1.0.1/ebin -pa . -s first_samples -s init stop -noshell
Starting eqc mini version 1.0.1 (compiled at {{2010,6,13},{11,15,30}})
....................................................................................................
OK, passed 100 testsテストが通りました。
日本語で書くと、ここで検証した「逆順(L)」という操作の性質(プロパティ)は、次のようなかんじでしょうか。
任意のリスト L に対して、それを任意に分割したサブリスト L = L1 + L2 が
逆順(L) = 逆順(L2) + 逆順(L1)
を満たす。
入力を L1, L2 (Xs, Ys) ではなく、L 自体にしてプロパティを書きなおしてみます。ちょっと煩雑になりますが、このように FORALL マクロを繋げたり、ステートメントをブロック化して、性質の検証前にちょっとした「何か処理」をすることが出来ます。
prop_reverse_combination2() -> ?FORALL(L, list(int()), ?FORALL(I, choose(0, length(L)), begin {L1, L2} = lists:split(I, L), lists:reverse(L) =:= lists:reverse(L2) ++ lists:reverse(L1) end)).
list() とか choose() あたりを調べるには、Quviq のトレーニングを受けるのが正当なんでしょうけど、ひとまず次のような調べ方があります。
- eqc.hrl の define とか import を見て推測する。
- triq ( https://github.com/krestenkrab/triq )の README を読む。
- 本家 Haskell の QuickCheck のドキュメントを読んで、Erlang に翻訳する。
まぁどれもいきあたりばったりですね。eqc mini にはドキュメントはほぼありません。
続く、かもしれない。
QuickCheck 勉強してみよう 最初の一歩の前段階
プログラムを書く際には、ユニットテストも書くでしょう。まぁどっちを先に書くか、という話は置いといて。テストの自動化は品質面でもコスト面でもプラスになるため、できるだけ網羅的にやりたい。しかし網羅は無理なので適当なところで切り上げます。
そこで、前から名前だけは知ってて気になっていた QuickCheck を調べてみようという気になりました。なんと ja.Wikipedia に項目がない、en でもなんかさっぱり短い説明です。Further Reading と External Links が有用そう。まぁ読んでませんが。
QuickCheck - Wikipedia, the free encyclopedia
ざっとまとめるとこんなかんじ。
めっちゃ噛み砕くと、
- 入力をたくさん勝手に生成して、
- 何か処理したあとに、
- 不変性などのチェックを行う。
- そしてチェックが失敗したら、
- 入力をなるべく簡略化して失敗する入力を教えてくれる。
このビデオはモチベーションと基本的なところから入っていてよさげ。PDF 落ちてないのかな。
Functional Programming: A Secret Weapon for Software Testing.
hughes_testing
John Hughes gives an invited talk at ICFP 2007 in Freiburg, Germany, showing from his company's experience how QuickCheck has found many obscure bugs in commercial software.
自分として知りたいこと
自分としては簡略化のところにロジック的な興味をかんじつつも、そこは押さえて実用性の面から調査したいと思います。
で、調査の目的を(すぐ忘れちゃうので)先に書いておく。
- テストが可能な範囲
- 具体的には、いわゆる xUnit 系のユニットテストに対して、どのあたりを QC に任せることができて、どう住み分けるのか。
- 「論理的性質」のテストってなんなのか
- ぱらっと見てて例としてあがるのは、互いに逆の操作があって(逆関数というべき?)、その合成はアイデンティティ( x -> x )である、というもの。この「逆関数パターン」みたいに、他に QC の適用方法のパターン化みたいなのがあるとすごくうれしい。
- 逆関数パターンの実践
- 自分が関わっているコードベースで、実際使ってみて有用さを実感できるのか。それともほぼ自明な感覚しか持てないのか。これは対象となる個別の関数の複雑さや実装コードによるので、結論があるものではないけど。
- 対象
- Erlang のプログラム、かつ gen_* のビヘイビアでないような単純なパターンに限る。複雑な FSM への適用にも興味はあるが、手を広げすぎると頭がついていかないので切っとく。
Erlang で使える QuickCheck の実装
ぱらっと探した範囲では、次のような有償、タダ、自由などいくつかの実装がありました。
まずはなんといっても QuickCheck の生みの親、John Hughes さんが作った会社 Quviq の製品。研究とビジネスを両立させているのって偉いな。
QuviQ homepage
名前は QuichCheck そのままみたい。Erlang のモジュール名としては eqc なので、"Erlang QuickCheck" くらいが呼び名かな。
製品と合わせ、Quviq ではトレーニング、コンサルティングも行っている。
Erlang Factory なんかでもプレゼンテーション、トレーニングなどをやっているみたい。例えばこれ。
Erlang Factory 2009 London - John Hughes - QuickCheck en Yahoo! Video
ところで、Quviq はなんと読むのだろうか、キュービック?
次に、同じく、 Quviq の無償版の QuickCheck mini。
2010 年 6 月にリリースしたとのこと []。
a free version of Quviq's product with a selection of features comparable to other free versions such as Haskell QuickCheck. QuickCheck Mini makes Quviq's technology for simplifying failing test cases available to a wide audience, and it can be freely used for testing personal, open source, or commercial software.
http://www.quviq.com/news100621.html
Full バージョンとの違いはここ
Quviq QuickCheck Feature Compari
FSM, PULSE, サポートあたりが違いますね。
Quviq の QC のオープンソースライセンスのクローンを github に 2 つ見つけた。他にもあるのかな。
最初に見つけたのは Triq、「トリック」と呼ぶみたい。ライセンスは Apache License v2 で公開されています。
Triq (pronounced "Trick Check") is a free alternative to QuviQ
krestenkrab/triq - GitHub
eqc. Triq's API is modelled closely after
eqc, so I recommend their tutorials and slides for an introduction
to QuickCheck.
もうひとつは PropEr というプロジェクト。ライセンスは GPLv3 (or lator) で、自由なソフトウェア。
PropEr (PROPerty-based testing tool for ERlang) is a QuickCheck-inspired
manopapad/proper - GitHub
open-source property-based testing tool for Erlang
ドキュメントがきちんと書いてあって素晴らしい。ソースも Triq よりすんなり読めそう。
続きは未定。
[ruby][java] JRuby の並列実行でメソッドの追加の実装方法
某所にて、 JRuby のスレッドは本当に並列で走る(global interpreter lock は使っていない)という話を聞きました。Ruby (大文字で始まるので言語のほうね) では、define_method とか動的な仕組みがいろいろとあるので、実装は大変なんじゃなかろうか、と思い、 JRuby のソースを久し振りに眺めてみることにしました。
メソッドの追加と、それと対になるメソッド呼び出し(探索)だけに注目しているので、ほんの一部しか目を通していません。注目するところは、以下の 2 点のみです。
- メソッド追加時に取得するロックはなにか
- メソッド呼び出し(探索)時にロックを取得するのか、するなら頻度とロックの種類
This is a community wiki dedicated to JRuby, an implementation of the Ruby programming language atop the Java Virtual Machine (JVM).
JRuby: Wiki: Home ― Project Kenai
対象バージョン: 1.4.0
追い掛けやすそうなメソッド追加側
Emacs で rgrep define_method 。RubyModule#define_method が出てきたので、これで間違いなさそう。おおざっぱにまとめると、
- module 単位で token をもって型を世代管理している (型の名前と token の組で識別)
- メソッド追加時には、module 単位のロックを取得
- そのロックを持った中で、
- メソッドの Map を更新して
- メソッド探索用のキャッシュを更新する
- この時は、グローバルなキャッシュを取って
- 更新で影響を受ける型オブジェクトに対する token を更新している
以下、コード読んだときの走り書き。
RubyModule.java
L. 1348
@JRubyMethod(name = "define_method", frame = true, visibility = PRIVATE,
reads = VISIBILITY)
public IRubyObject define_method(ThreadContext context, IRubyObject arg0,
Block block) {
Ruby runtime = context.getRuntime();
...
RuntimeHelpers.addInstanceMethod(this, name, newMethod,
context.getPreviousVisibility(), context, runtime);
L. 885 addMethod
L. 895 addMethodInternal
synchronized(getMethods()) {
addMethodAtBootTimeOnly(name, method);
// -> methods#put している
invalidateCacheDescendants();
// ->
// 1. generation の更新 (token を new Object() で上書き)
// 2. getRuntime().getHierarchyLock() のロック(グローバル)を持って
// includingHierarchy.invalidateCacheDescendants();
}
L. 369 getMethods
methods の getter
L. 199 private final Map<String, DynamicMethod> methods =
new ConcurrentHashMap<String, DynamicMethod>(4, 0.9f, 1);
RuntimeHelpers (org.jruby.javasupport.util)
L. 1398 addInstanceMethod
L. 1403 call addModuleMethod
L. 1409 addModuleMethod
L. 1410
containingClass.getSingletonClass().addMethod(name, new WrapperMethod(
containingClass.getSingletonClass(), method, Visibility.PUBLIC));
// containingClass: RubyModule
メソッド呼び出し(探索)側
org.jruby.runtime.Callsite からの型ツリーが呼び出し側っぽい。
ザッとまとめ。
- 基本はロックを取らない。
- ときどき(0xFF + 1 = 256)、synchronized をかけてスレッドワーキングメモリを追い出す。
- token を調べて、古かったら真面目にメソッドを探索する(親なども追い掛ける)。
走り書き。
CashingCallsite.java
L. 63 call
L. 64 callAndGetClass
ThreadContext#callThreadPoll (L.502) // 0xFF 回ごとには synchronized する
L. 66 CacheEntry#typeOK
// キャッシュの有効性確認
L. 69 cacheAndCall
L. 274 selfType.searchWithCache // selfType: RubyClass
L. 277 callMethodmissing
L. 280 method.call // method: DynamicMethod
RubyModule
L. 962 searchWithCache
L. 963 cacheHit // メソッドキャッシュから名前で引いて token を当てる
取れたらそれを return
L. 969 取れないときは、階層を上に探索して、キャッシュして返す
L. 967 - 968 この処理へのコメント
// we grab serial number first; the worst that will happen is we cache a later
// update with an earlier serial number, which would just flush anyway
// 訳: 先にシリアルナンバー(token)を取る。最悪でも、キャッシュされたメソッドに
// 対する token が古くなるが、それはあとで捨てられるだけである。
実際に動かしてみる
- ロック競合がほとんで無いであろう fibonacchi を one thread, two threads で計算
- 同じクラスの同じメソッドを define/undefine
- 同じクラスの違うメソッドを define/undefine
- 違うクラスのメソッドを define/undefine
コードは gist
difine_method_bench.rb
gist: 235787 - GitHub
環境
% sw_vers
ProductName: Mac OS X
ProductVersion: 10.6.2
BuildVersion: 10C540
% system_profiler SPHardwareDataType | grep Processor
Processor Name: Intel Core 2 Duo
Processor Speed: 2.2 GHz
Number Of Processors: 1
%  ̄/local/jruby-1.4.0/bin/jruby --version
jruby 1.4.0 (ruby 1.8.7 patchlevel 174) (2009-11-02 69fbfa3)
(Java HotSpot(TM) 64-Bit Server VM 1.6.0_15) [x86_64-java]結果
2 -> 3 -> 4 の順で実行時間が短くなっていることが分かる。上のソース読みと整合性は取れている。ただし、完全には説明できているわけではない。
%  ̄/local/jruby-1.4.0/bin/jruby define_method_bench.rb 38 2000000
Almost no lock contention (calculate Fibonacchi sequence)
user system total real
1 thread (0) 12.088000 0.000000 12.088000 ( 12.038000)
2 threads (0) 14.528000 0.000000 14.528000 ( 14.528000)
1 thread (1) 12.234000 0.000000 12.234000 ( 12.235000)
2 threads (1) 17.308000 0.000000 17.308000 ( 17.308000)
1 thread (2) 12.030000 0.000000 12.030000 ( 12.031000)
2 threads (2) 15.870000 0.000000 15.870000 ( 15.870000)
1 thread (3) 12.298000 0.000000 12.298000 ( 12.298000)
2 threads (3) 15.762000 0.000000 15.762000 ( 15.762000)
Add/remove the SAME method for the SAME class object
user system total real
1 thread (0) 4.203000 0.000000 4.203000 ( 4.202000)
2 threads (0) 7.575000 0.000000 7.575000 ( 7.575000)
1 thread (1) 3.629000 0.000000 3.629000 ( 3.629000)
2 threads (1) 7.204000 0.000000 7.204000 ( 7.205000)
1 thread (2) 3.545000 0.000000 3.545000 ( 3.545000)
2 threads (2) 7.292000 0.000000 7.292000 ( 7.291000)
1 thread (3) 3.684000 0.000000 3.684000 ( 3.684000)
2 threads (3) 7.060000 0.000000 7.060000 ( 7.060000)
Add/remove different methods for the SAME class object
user system total real
1 thread (0) 3.758000 0.000000 3.758000 ( 3.758000)
2 threads (0) 5.774000 0.000000 5.774000 ( 5.774000)
1 thread (1) 3.840000 0.000000 3.840000 ( 3.840000)
2 threads (1) 5.938000 0.000000 5.938000 ( 5.938000)
1 thread (2) 3.709000 0.000000 3.709000 ( 3.709000)
2 threads (2) 5.482000 0.000000 5.482000 ( 5.483000)
1 thread (3) 3.749000 0.000000 3.749000 ( 3.749000)
2 threads (3) 5.614000 0.000000 5.614000 ( 5.613000)
Add/remove different methods for different class objects
user system total real
1 thread (0) 3.805000 0.000000 3.805000 ( 3.805000)
2 threads (0) 5.156000 0.000000 5.156000 ( 5.156000)
1 thread (1) 3.662000 0.000000 3.662000 ( 3.662000)
2 threads (1) 4.900000 0.000000 4.900000 ( 4.900000)
1 thread (2) 3.656000 0.000000 3.656000 ( 3.656000)
2 threads (2) 4.611000 0.000000 4.611000 ( 4.611000)
1 thread (3) 3.735000 0.000000 3.735000 ( 3.735000)
2 threads (3) 4.800000 0.000000 4.800000 ( 4.800000)
補足
Java 仮想マシンの仕様で、 synchronized (修飾子 or ブロック)による、スレッドのワーキングメモリとメインメモリの同期要求に関しては、結城さんの本にに説明があって、すごく分かりやすい(本文じゃなくてコラムかアペンディックスだったかも)。
Amazon.co.jp: 増補改訂版 Java言語で学ぶデザインパターン入門 マルチスレッド編: 結城 浩: 本
ダグ・リー先生のページにしっかりとした説明がある。
In essence, releasing a lock forces a flush of all writes from
Synchronization and the Java Memory Model
working memory employed by the thread, and acquiring a lock
forces a (re)load of the values of accessible fields. While lock
actions provide exclusion only for the operations performed
within a synchronized method or block, these memory effects are
defined to cover all fields used by the thread performing the
action.
Note the double meaning of synchronized: it deals with locks that
permit higher-level synchronization protocols, while at the same
time dealing with the memory system (sometimes via low-level
memory barrier machine instructions) to keep value
representations in synch across threads. This reflects one way in
which concurrent programming bears more similarity to distributed
programming than to sequential programming. The latter sense of
synchronized may be viewed as a mechanism by which a method
running in one thread indicates that it is willing to send and/or
receive changes to variables to and from methods running in other
threads. From this point of view, using locks and passing
messages might be seen merely as syntactic variants of each
other.
[database] トランザクション分離レベルのメモ
RDBMS/SQL の話のなかで、基礎的な知識として必ずでてくる(であろう) 4 種類のトランザクション分離レベル (transaction isolation levels) ですが、腑に落ちたことがなく気持ち悪い印象をもっていました。そこで、差異を正しく理解すべく、 Bernstein さん、 Jim Gray さんたちの論文を読んでみました。個人的に興味のある点は、 Phantom Read とは何か? と Snapshot Isolation はどの程度の隔離レベルか? という 2 点です。
PostgreSQL のトランザクション分離
PostgreSQL は read committed と serializable のトランザクション分離レベルを実装しています。
In PostgreSQL, you can request any of the four standard transaction isolation levels. But internally, there are only two distinct isolation levels, which correspond to the levels Read Committed and Serializable.
PostgreSQL: Documentation: Manuals: PostgreSQL 8.4: Transaction Isolation
しかしながら、 数学的な(= mathematical) serializable ではない、と記述されています。
13.2.2.1. Serializable Isolation versus True Serializability The intuitive meaning (and mathematical definition) of "serializable" execution is that any two successfully committed concurrent transactions will appear to have executed strictly serially, one after the other ― although which one appeared to occur first might not be predictable in advance. It is important to realize that forbidding the undesirable behaviors listed in Table 13-1 is not sufficient to guarantee true serializability, and in fact PostgreSQL's Serializable mode does not guarantee serializable execution in this sense. As an example, consider a table mytab, initially containing:
PostgreSQL: Documentation: Manuals: PostgreSQL 8.4: Transaction Isolation
論文「ANSI SQL 分離レベルの批評」
みつけたのが、この論文。ぼくはあまり歴史とか知りませんが、きっと古典的な論文っぽいかんじが漂っています。
authors:
Hal Berenson, Phil Bernstein, Jim Gray, Jim Melton, Elizabeth O'Neil, and Patrick O'Neilabstract:
ANSI SQL-92 [MS, ANSI] defines Isolation Levels in terms of phenomena: Dirty Reads, Non-Repeatable Reads, and Phantoms. This paper shows that these phenomena and the ANSI SQL definitions fail to characterize several popular isolation levels, including the standard locking implementations of the levels. Investigating the ambiguities of the phenomena leads to clearer definitions; in addition new phenomena that better characterize isolation types are introduced. An important multiversion isolation type, Snapshot Isolation, is defined.アブストラクト(訳):
A Critique of ANSI SQL Isolation Levels - Microsoft Research
ANSI SQL-92 では、現象、 Dirty Reads, Non-Repeatable Reads, そして Phantoms の観点から分離レベルを定義している。この論文では、これらの現象と ANSI SQL 定義がいくつかの良く使われている分離レベル、標準的なロックによるレベルの実装を特徴づけることに失敗していることを示す。曖昧さを調べることにより、より明確な定義を導き、また、分離タイプを特徴づける新しい現象を導入する。重要な、 multiversion 分離タイプである、 Snapshot 分離を定義する。
ANSI の分離レベル (section 2.2)
3 つの「現象」
によって定義される 4 つのレベル
- リードアンコミッティド
- リードコミッティド
- リピータブルリード
- シリアライザブル
ここだけ片仮名に変わるとコピペが見えみえですが、まぁここはまじめに書くつもりがないので、下のページにゆずります。よくみる表が載っています。
4つの分離レベルと3つの現象の関係は以下の通りです。
ThinkIT 第3回:トランザクションの比較 (1/4)
Locking (section 2.3)
ロックのための言葉を導入します。
- Read locks
- Shared
- Write locks
- Exclusive
- Read/Write predicate lock
-
について、それを満たす全てのデータに対するロック。未来のデータも含むので、無限集合のこともある。
さらに定義が続きます。
- well-fromed reads/writes
- reads/writes の*前*に、対象のデータ、または predicate のロックを要求する場合、 well-formed と言う。
- long duration
- あるトランザクションによって取得されたロックが、commits か aborts まで保持される場合、 long duration と言う。
- short duration
- long duration ではないもの。ex. ロック取得して更新操作後にすぐ開放されるロック。
これらのロックの種類の組み合わせでもって、 "Locking Isolation Levels" というものを定義します。 (Table. 2)
表のなかから、 ロック版 (in terms of locks) の READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ について抜粋してみます。
- Degree 1 = Locking READ UNCOMMITTED
- Read Locks
- (none required)
- Write Locks
- Well-formed Writes
- Long duration Write locks
- Read Locks
- Degree 2 = Locking READ COMMITTED
- Read Locks
- Well-formed Reads
- Short duration Read Locks (both data-item and predicate)
- Write Locks
- Well-formed Writes
- Long duration Write locks
- Read Locks
- Locking REPEATABLE READ
- Read Locks
- Well-formed Reads
- Long duration data-item Read Locks
- Short duration Read Predicate Read Locks
- Write Locks
- Well-formed Writes
- Long duration Write locks
- Read Locks
- Degree 3 = Locking SERIALIZABLE
- Read Locks
- Well-formed Reads
- Long duration Read Locks (both data-item and predicate)
- Write Locks
- Well-formed Writes
- Long duration Write locks
- Read Locks
ゴチャゴチャして分かりにくいですが、 Write 側では、全てのレベルで、 well-formed かつ Long duration locks が入っています。つまり READ UNCOMMITTED であってもアトミックであるためには、書き込みにはそれらが必要ということですね。
それに対して、 Read 側がレベルを分けるようになっています。例えば、Locking REPEATABLE READ では、一度読んだデータに対して、 long duration locks を要求しています。スッと腑に落ちますね。
この後、分離レベルに半順序の定義をしています。
- stronger (<<) : L1 << L2 <=> L1 で許される non-serializable な履歴が L2 では禁止される、かつ、 L2 で許される non-serializable な履歴が L1 で許される
- equivalent (==) : 許される non-serializable な履歴の集合が一致する
- no stronger (<<= :論文では << の下に横棒) : << OR ==
- incomparable (>><<) : お互いに、相手では許されるが、自分では禁止される non-serializable な履歴が存在する
Analyzing ANSI SQL Levels (section 3)
ANSI の現象で定義したレベル (section 2.2) と ロックで定義したレベル (section 2.3) の関連付けを行っています。あまり面白みが無いので省略。
Cursor Stability (section 4.1)
Section 4 では "Other Isolation Types" として、いくつかの分離レベルを説明しています。
まずは section 4.1 から "Cursor Stability"。この分離レベルは「 lost update を防ぐように設計されている」と書かれています。現象 "lost update" の定義は次のとおりです。
P4: r1[x] ... w2[x] ... w1[x] ... c1 / Phenomena: Lost Update
これはトランザクションの履歴を表しています。(正確には「現象」を表していると書いてあり、その心は ... のところは任意のオペレーションが入るからだと思われます)。
凡例は以下のとおりです。
- r1[x]
- T1(トランザクション1) がデータ x を read
- w2[x]
- T2(トランザクション2) がデータ x を write
- r1[P]
- T1 が predicate P で read
- w1[P]
- T1 が predicate P で write
- c1
- T1 が commit
- a1
- T1 が abort
具体的な履歴として、ひとつ例が書いてあります。
H4: r1[x=100] r2[x=100] w2[x=120] c2 w1[x=130] c1
ここで、 w1[130] は r1[x=100] に対して、 x = x(=100) + 30 と更新した気持ちです。
Lost update を防ぐために、 Cursor Stability では、 READ COMMITTED のロックに加えて、新しい read action "FETCH" を導入します。ここで cursor からの FETCH は現在のデータアイテムにロックがあり、cursor が(通常は commit により)閉じられるまで続くことを要求します。カーソルから FETCH した後に、カーソルはそのままで x に更新を入れると、short duration の read lock をもった状態で write lock が取得されることになります。
そこで、2 つの操作を定義して、
- rc (read cursor)
- FETCH
- wc (write cursor)
- FETCH した *現在の* レコードに対する write
P4: rc1[x] ... w2[x] ... wc1[x] ... c1 / Phenomena: Lost Update
という現象を見ると、rc1 -> wc1 に挟まれた w2 はロックが取得できないことが分かります。具体的には、rc1[x] の read lock と衝突します。
このセクションの結論としては、以下の順序関係が書いてあります。
READ COMMITTED << Cursor Stability << REPEATABLE READ
Snapshot Isolation (section 4.2)
真打登場です(ぼくにとっての)。
Snapshot Isolation (SI) は multi-version (MV) の方法であるため、履歴の記述方法を拡張しなくてはなりません。具体的には、データアイテムに対してバージョン番号を付与することで可能になります。 Section 3 で出てきた履歴 H1 (これは良く見る、口座間のお金の受け渡しをモデル化しています。途中で T2 が 100 となるべき合計を 10 + 50 = 60 と見てしまっています)
H1: r1[x=50] w1[x=10] r2[x=10] r2[y=50] c2 r1[y=50] w1[y=90] c1
を SI で書き換えてみると次のようになります。
H1.SI: r1[x0=50] w1[x1=10] r2[x0=10] r2[y0=50] c2 r1[y0=50] w1[y1=90] c1
H1.SI が serializable execution のデータフローを持っています。MV の履歴は single value (SV) の履歴に常にマップすることが出来るそうです(c.f. [BHG] chapter 5)。
まずは、 Snapshot Isolation が Serializable ではないこと。
H5: r1[x=50] r1[y=50] r2[x=50] r2[y=50] w1[=-40] w2[y=-40] c1 c2
直列にすると、1 と 2 のどちらを先にもってきても、 x, y どちらかが -40 になり、 50 という値は読めないので、 Serializable ではない履歴になります。一方で、書き込みは被っていないので、バージョンは自明で Snapshot Isolation の場合は可能な履歴です。この履歴では、データベース全体に渡る制約(Constraint)を模倣しています。具体的には、
x + y > 0
という制約があると考えると、各トランザクションでは満たされているものの、T1, T2 が終わった段階で破れてしまっています。
論文では、この履歴から、 Read Skew / Write Skew という 2 つのアノマリー(anomaly)を抽出して、順序を導きます。
A5A: r1[x] ... w2[x] ... w2[y] ... c2 ... r1[y] ... (c1 or a1) / Anomaly: Read Skew A5B: r1[x] ... r2[y] ... w1[y] ... w2[x] ... (c1 or c1) / Anomaly: Write Skew
2 つのデータ x, y に関連した制約があると心で思って見ると、Read Skew では、T1 は別のトランザクションが書き換える前後で関連データを読んでしまっている、と読めます。 Write Skew は、2 つのトランザクホンで読むデータアイテムと書くデータアイテムが互い違いになっています。
Read Skew に注目すると、 READ COMMITTED では許可されます。Snapshot Isolation では、 r1[y] が multi-version で w2[y] の前の情報を見るため、禁止される(single value に変換したときに、 A5A に落ちるものは無い、と解釈する)ことが分かります。
READ COMMITTED << Snapshot Isolation
次に、REPEATBE READ と Snapshot Isolation の順序を考えてみます。
REPEATABLE READ における Write Skew の可能性を考えてみると、 x は T1 に読まれた後、 T2 が書かれるので、 "data-item" の read lock に long duration を要求する REPEATABLE READ では禁止されることが分かります。注目している Snapshot Isolation では、 write が被っていないので許可されています。
ところが、次の 3つのアノマリー(P は predicate)
A1: w1[x] ... r2[x] ... ((c1 or a1) and (c2 or a2)) / Anomaly: Dirty Read A2: r1[x] ... w2[x] ... c2 ... r1[x] ... c1 / Anomaly: Fuzzy Read A3: r1[P] ... w2[y in P] ... c2 ... r1[P] ... c1 / Anomaly: Phantom
のうち、 A3 は、 "predicate" の read lock に short duration しか要求しない REPEATABLE READ では許可され、 Snapshot Isolation では禁止されます。よって 2 つの間の順序は incomparable となります。
REPEATABLE READ >><< Snapshot Isolation
「A1 - A3 のアノマリーを禁止する」という隔離レベルを ANOMALY SERIALIZABLE と定義すると、それは anomaly の観点から定義した "ANSI の SERIALIZABLE" 相当のレベルとなります(当然ですが、 mathematically SERIALIZABLE ではありません)。
ANOMALY SERIALIZABLE << SNAPSHOT ISOLATION
Other Multi-Version Systems (section 4.3)
Oracle の Consistent Read (SQL ステートメントが開始された時点から見て、直近のデータを読む)が紹介されています。
READ COMMITTED << Oracle Consistent Read << REPEATABLE READ
Summary and Conclusions (section 5)
論文中で紹介された分離レベルが、ひとつの図にきっちりとまとめられています。
まとめ(section 5 summary) にある分離レベルとその関係図。
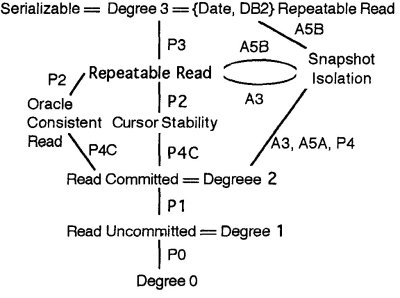
Read Committed より上で、 Serializable までは行かないというあたりで、機能と性能がぶつかりあうのかなぁ、と感じられます。具体的には、 "long duration な read predicate lock" が重たいはずなので、そこを回避しつつかなり高い隔離レベルを実現する Snapshot Isolation は興味深いものです。
以上、(ぼくの興味である) Snapshot Isolation を中心に、論文を読んでみたメモでした。
補足
Multiversion concurrency control (MVCC) については、次の論文に詳しく(まとめ的に)記述してあります。
Concurrency control algorithms for multiversion database systems
Concurrency control algorithms for multiversion database systems
authors:
Philip A. Bernstein, Nathan Goodman
オリジナルなアイデアはこちらの論文です。
author: D.P. Reed
Naming and Synchronization in a Decentralized Computer System
"Naming and Synchronization in a Decentralized Computer System". MIT dissertation. http://www.lcs.mit.edu/publications/specpub.php?id=773. Retrieved September 21 1978.
HT-03A を買いました
周りに iPhone をもっているひとが増えはじめて、うらやましかったので
android ケータイ HT-03A (HTC Magic)を買いました
保護シート
OverLay Plus for HT-03A
Google 携帯を買った - レジデント初期研修用資料
OverLay Brilliant for HT-03A
を参考にして、 Plus (非光沢なほう)を買うことに決めました。だけれども、まちがって Brilliant (光沢があって透明な綺麗なほう)をポチってしまったもので、一週間ほど使ってみました。すごく透明度が高く、見易い。でも、フリックがひっかかるのは否めず。気をとりなおして Plus を購入。貼ったときには、ザラついたかんじになるし、あまり見たかんじは良くないなぁ、と思いましたが、フリックなどの操作をするととっても快適になります。
これは、晴れた屋外で見にくいとか、ザラつくとか脇に置いといて素晴しいです。最初まちがったけど、 Plus のほうを買いなおして & 比較できて良かったです。
twidroid を使用。タイムラインを表示して、一番下まで行ったときに自動でその次をロード *しない* ので、時間がむだに潰れなくて良いです。
とおもってたら、最近のバージョンアップで機能追加されたみたい。"Share with” のオプションがあるといいのになぁ。
Gmail
組み込みのやつですぐに見れます。
買ったタイミングが、GMail/マーケットが度々コケる、という障害のまっただなかでした。
HT-03Aで「接続がありません」と表示されて、メールの送受信ができません - モバイルヘルプ
という状況だったのですが、それほど激しいメール使いでもないし、最後はウェブブラウザでみれるからいいや、ってことで。今は復旧しているみたいで、安心。メールのプッシュもあまり遅延なく来てるかんじです。
この障害は、もしかして Gears 絡みで長びくかも、と覚悟してたけど、(公式発表によると)通信路の問題だったとのこと。
HT-03Aをご利用のお客様へお知らせ | ニュース | ドコモスマートフォンサイト | NTTドコモ
GTD はじめた
Astrid というアプリで remember the milk と同期しつつタスク管理ができます。
締切とかアラームとか、なかなか設定しやすい作りになっていてモノグサなぼくでもつづいています (まだ 4 日)。ものすごく鳥頭なので、ふと思いついたことが 30 秒ほどで記憶のかなたに行ってしまうのですが、ホームから 1 タップでタスク登録に入れるので安心感があります。
まだ、GTD までいってなくて、単なるタスク管理な使い方ですが、まずは継続できる手軽さが素晴しいです。ホーム画面でタスクがチラ見できるウィジェット(2x2)も有用度高いです。
Layar
AR アプリ。iPhone 版もある(はず)。近くにあるなにかを探して、カメラのビューに重ねて表示をしてくれます。探す情報自体はアドオンというか、API が公開されていて、データがあればいけるらしい。
Layar
クライアント(android/iPhone)、サーバ、データプロバイダのアーキテクチャはこちらで見れます。
layar / Architecture
立ち上がったところで、すぐに検索キーワードを入れることができ、そこに cafe とか movie とか入れると、近くにある情報をとってきて、 AR で見せてくれます。そして、場所をタップして "Take me there" とやると地図アプリが起動して、現在地からの経路検索とかできます。このへん、 android っぽく、 Intent 経由で動的にアプリ間連携するのは心地良いと感じます。
今のぼくの環境では、 "Take me there" で地図にとんで、戻ろうとするとエラーが発生するので、開発者に報告中。1.6(Donut) に更新してもダメでした。はやく直らないかなぁ。開発者向けってのもあるから試して見ようかな。
データとしては、日本向けなものもあって、コンビニ、銀行、飲食店、その他いろいろ。
Layar - コンテンツ
これは、ユーザ作成コンテンツなレイヤ。情報を登録するフローが少々遠いように思います。
みんなのLayar
今は、 3D のテクスチャを貼りつけて表示できるように開発中とのこと。楽しみです。
3D « Layar
その他アプリケーション試行
iNap : GPS を使って、目的地に近くなったらアラームを鳴らしてくれるアプリ。何度か通勤電車で使ってみたのですが、電車内では精度があまり出ないことがあり挫折。室内での位置情報利用はこれからの技術に期待。
Buddy Runner: ジョギングのお供に。屋外では GPS は問題無く動作しています。ウェブ上にデータを入れると、距離、高低差、履歴などが見れます。
サンプルはこれ
forrest.gump's Dashboard