Digger で複数の AWS アカウント(たとえば stg 環境と prd 環境)にデプロイする仕組みを作ってみたので簡単にまとめておこうと思う.基本的にはドキュメントに載っている通りに設定すれば OK だった👌
動作イメージ
まず,適当に Terraform コードを変更してプルリクエストを出す.すると自動的に stg 環境と prd 環境に対して terraform plan が実行される💡

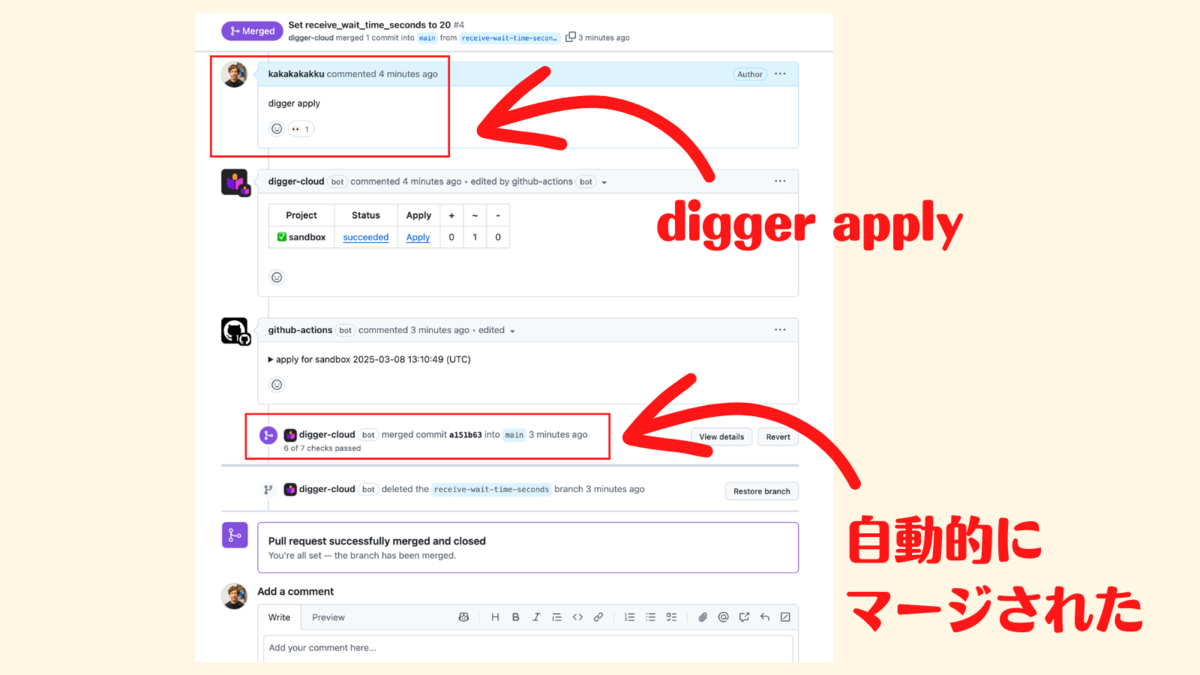
そして -p オプションでプロジェクトを指定して digger apply -p stg コマンドを実行すると,stg 環境に対して terraform apply が実行される❗️

同じように digger apply -p prd コマンドを実行すると,prd 環境に対して terraform apply が実行される❗️

問題がないことを確認できたらプルリクエストをマージすれば OK👌
ちなみに -p オプションでプロジェクトを指定しないと,同時に stg 環境と prd 環境に対して terraform apply が実行された.正直同時にデプロイする機会は少なそうだし,むしろ誤って実行しないように抑止できると良さそうだけど...😅
コード紹介
ディレクトリ構成
├── .github
│ └── workflows
│ ├── digger-run-prd.yml
│ └── digger-run-stg.yml
├── digger.yml
├── prd
│ ├── provider.tf
│ └── main.tf
└── stg
├── provider.tf
└── main.tf
👾 digger.yml
プロジェクトとして stg 環境と prd 環境を作って,ディレクトリ名と GitHub Actions ワークフローファイル名を設定した👌
projects: - name: stg dir: stg workflow_file: digger-run-stg.yml - name: prd dir: prd workflow_file: digger-run-prd.yml
👾 .github/workflows/digger-run-stg.yml
基本的にドキュメントに載っているワークフロー設定を参考にしてるけど,AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY は設定したくなく,aws-role-to-assume で OIDC (OpenID Connect) で IAM Role を引き受けられるようにしている👌
name: Digger Workflow (stg) on: workflow_dispatch: inputs: spec: required: true run_name: required: false run-name: '${{inputs.run_name}}' jobs: digger-job: runs-on: ubuntu-latest environment: stg permissions: contents: write # required to merge PRs actions: write # required for plan persistence id-token: write # required for workload-identity-federation pull-requests: write # required to post PR comments issues: read # required to check if PR number is an issue or not statuses: write # required to validate combined PR status steps: - uses: actions/checkout@v4 - name: ${{ fromJSON(github.event.inputs.spec).job_id }} run: echo "job id ${{ fromJSON(github.event.inputs.spec).job_id }}" - uses: diggerhq/digger@v0.6.91 with: digger-spec: ${{ inputs.spec }} setup-terraform: true terraform-version: v1.11.0 setup-aws: true aws-role-to-assume: ${{ secrets.AWS_ROLE_TO_ASSUME }} aws-region: ap-northeast-1 cache-dependencies: true env: GITHUB_CONTEXT: ${{ toJson(github) }} GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
👾 .github/workflows/digger-run-prd.yml
name と jobs.digger-job.environment 以外は同じ.
name: Digger Workflow (prd) on: workflow_dispatch: inputs: spec: required: true run_name: required: false run-name: '${{inputs.run_name}}' jobs: digger-job: runs-on: ubuntu-latest environment: prd permissions: contents: write # required to merge PRs actions: write # required for plan persistence id-token: write # required for workload-identity-federation pull-requests: write # required to post PR comments issues: read # required to check if PR number is an issue or not statuses: write # required to validate combined PR status steps: - uses: actions/checkout@v4 - name: ${{ fromJSON(github.event.inputs.spec).job_id }} run: echo "job id ${{ fromJSON(github.event.inputs.spec).job_id }}" - uses: diggerhq/digger@v0.6.91 with: digger-spec: ${{ inputs.spec }} setup-terraform: true terraform-version: v1.11.0 setup-aws: true aws-role-to-assume: ${{ secrets.AWS_ROLE_TO_ASSUME }} aws-region: ap-northeast-1 cache-dependencies: true env: GITHUB_CONTEXT: ${{ toJson(github) }} GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
GitHub Environments
あとは GitHub Environments に stg と prd を作って,シークレット AWS_ROLE_TO_ASSUME に IAM Role の ARN を設定すれば OK👌

まとめ
Digger を使えば比較的簡単に Terraform のブランチデプロイと IssueOps を実現できてイイ感じ \( 'ω')/