Google Analyticsのイベントトラッキングを利用した簡易アンケート
昨年のBlogaraで最もアクセスがあったテーマは、 世間的にも色々と話題になったAKB48。
所属メンバーの所有するブログが多く、さらにブログの更新頻度も高いという事で、 アイドルグループはBlogaraにはうってつけのテーマと言えます。
以前のテーマ:AKB48では、SDN48も一緒に扱っていましたが、 SDN48のメジャーデビューに向けた各人の公式ブログ開始に伴い、さすがに1テーマで扱うにはブログが増えすぎた為、SDN48を独立したテーマとして分離しました。
よって現在のテーマ:AKB48では、AKB48とSKE48の全正規メンバーの(携帯向けのIP制限が掛かっておらず誰でも読む事が出来る)全ブログが登録されています。
が、現状でも既に150近いブログとなっており、しかも今後AKB48の正規メンバー増員とSKE48 チームEメンバーの個人ブログ開始による登録ブログ数増加が見込まれ、 さらに今年始動したNMB48の扱いも考えなければならない為、この機会にテーマ:AKB48の構成を見直そうと考えました。
そこで利用者の方々の意見も参考にすべきという訳で、テーマページにアンケートフォームを設置してみる事にします。
テーマの構成についての利用者へのアンケート
Webページにアンケートを設置する場合には、サーバー側のスクリプトでの処理と集計が一般的ですが、 処理内容と集計結果の確認はアクセス解析と同様のものとなる為に、単純なものであれば開発と設置にはそれほどのコストは掛かりません。 ただ、ある程度複雑なデータ解析を行おうとする場合にはそれなりのコストが掛かり、あまりお手軽とは言えません。
高機能の解析の定番と言えばGoogleAnalytics(以下GA)。 そこで、GAを利用しアンケートを行う事が出来ないかと考えたのが今回の発端。
既にBlogaraでは、ブログの人気ランキングの参考資料として利用する為に、 GAのイベントトラッキングを利用したブログリンクのクリック数カウントを行っていますので、 今回のアンケートにもその手法を流用し、設置の手間も少なく尚且つ多様な機能を駆使して集計結果を確認出来るGAでアンケート計測を行ってみます。
今回のポイントとしては、
- ボタン1クリックによる決定
-
今回は単一項目のアンケートとなる為に、アンケートフォームの定番であるチェックボックスやラジオボタンと送信ボタンを組み合わせた形では無く、
選択肢が表示されたボタンの1クリックで送信を行えるようにする。
これにより、ユーザーの操作行動が一段階省略出来、その分アンケート回答までのハードルを多少下げる事が見込まれ、 尚且つアンケートフォームのUI設置面積も削減可能となる。 - 1ユーザーは1度の回答
-
通常のアンケート同様に、各利用者には1度だけ回答を行ってもらう事が望ましいので、
回答したか否かを(localStorageでは無く)Cookieに保存し、回答済みであるならアンケートフォーム自体を表示しないようにする。
アンケートの期間中に常時表示されるようなケースでは、目立つ場所に表示させると非常に目障りとなるが、 一度回答したユーザーにはアンケートが表示されない為、比較的目立つ場所にアンケートフォームを置いたとしても弊害は少なく、回答率上昇が期待出来る。 - イベントトラッキングの値の設定
- 既にBlogaraではいくつかの用途でイベントトラッキングを利用しているので、それらと区別出来るカテゴリ/アクション/ラベルを設定する。
GAでのイベントトラッキング
GAのイベントトラッキングでは公式ガイドにもある通り、 カテゴリ/アクション/ラベル/値という分類にそれぞれ任意の値を設定出来ます。
例えば、Blogaraで既に利用している各ブログへのリンクがクリックされた回数を記録するイベントトラッキングでは、
- カテゴリ
- イベントの種類を表し、ここではブログリンククリックを意味するlinkが設定されている。
- アクション
- 誰のどのブログがクリックされたかを記録する用途で利用。メンバーID_ブログIDの組み合わせで指定され、581_1060のような値が記録される。
- ラベル
- 補足情報としてどのテーマで表示されていたのかを記録。akb48やakb_sel2のようなテーマIDが格納される。
- 数値
- 未使用
カテゴリ/アクション/ラベルはそれぞれ大分類/中分類/小分類として利用する感覚で問題無いと思われます。
また、数値に整数値が必要とされる以外、他の3項目は文字列として扱われるので自由に値を設定出来ます。
# 恐らく文字列はUTF-8として扱っていると思われるので、UTF-8なら日本語もOKな気もしますが、
# 未確認なので詳細は不明
そこで、今回のアンケートも上記の利用法に準拠し各項目を設定します。
- カテゴリ
- イベントの種類を表すカテゴリには、アンケートを意味するenqを設定。
- アクション
- akbtpc_01のようなアンケートの回答が格納される。
- ラベル
- 何のアンケートかの識別値が格納。akb48。今回はアクションにもアンケートの種類を表す文字列(akbtpc_)が含まれる為、実質利用していない単なるオマケ。
- 数値
- 未使用
テーマページへの実装
という訳で早速テーマ:AKB48ページへのアンケートフォームの設置を行います。設置場所は各テーマの補足情報を表示する為に用意されているブログ一覧タブの上部になります。
// アンケートフォームを表示するエリアを設定 <div id="dvEnqArea" class="mbtnArea"></div> <script type="text/javascript"> (function(){ // checkEnqStateは、Cookieを参照し既に回答したか否かをチェックする処理。 // 回答済みならアンケートを表示しない。 if ( !Blogara.checkEnqState('akbtpc','akb48') ) { var elem = $('dvEnqArea'); // アンケートフォームとして表示される説明文とボタンの作成 elem.set( 'html', '<button id="btEnq01">1. 今後NMB48を追加し...' ); // 略 // EventDelegationを利用し、個々のボタンにでは無くアンケートエリアにイベントを設定 elem.addEvent( 'click', function(ev){ var ma = ev.target.id.match(/^btEnq(\d+)/); // クリック対象が指定のIDを割り当てられたアンケート回答ボタンの場合にだけ処理を行う if ( ma ) { // setEnqDataでは、Cookieに回答済みフラグをセットし、GAのイベントを発行 Blogara.setEnqData( 'akbtpc', 'akb48', ma[1], {path:'/t/akb48'} ); elem.set( 'html', '<hr />アンケートへのご協力ありがとうございます' ); } }); } })(); </script>
実際にGAにイベントトラッキングを記録する処理は、
Blogara = {
// アンケートの回答記録をCookieに保存と同時にAnalyticのイベントトラッキングにも記録
setEnqData: function( idEnq, label, value, opt ) {
if ( !label ) label = '';
// enqNameはアンケートを意味する'enq'
var action = idEnq+'_'+value, key = Blogara.enqName+'_'+idEnq+'_'+label;
if ( !opt ) opt = {};
// enqExipreには30日を設定
if ( !opt['duration'] ) opt['duration'] = Blogara.enqExpire;
// Cookieにアンケート回答済みフラグを設定
Du.CookieCtrl.set( key, value, opt );
Blogara.sendEventTracking( Blogara.enqName, action, label );
},
// GoogleAnalyticsのイベントトラッキングに記録
sendEventTracking: function( category, action, label ) {
if ( _gaq )
{
// 非同期GAの初期化が終る前は単なる配列、
// 初期化終了後はGAの非同期管理オブジェクトとなる_gaqにイベントを渡す
_gaq.push( ['_trackEvent', category, action, label] );
}
return true;
}
}
簡単に言うと、アンケートボタンには回答番号が含まれたIDが設定され、 そのクリックイベントからどの回答が選択されたかを取得し、カテゴリ/アクション/ラベルを組み立てGAのイベントトラッキングを発行する。という処理になります。
GAの非同期版では、 _gaq.push( ['_trackEvent', category, action, label] ); のように_gaqオブジェクト(又は配列)のpushメソッドに'_trackEvent'とカテゴリ/アクション/ラベルを引数として渡す事で、イベントとして記録されます。
実際にページで表示されるアンケートフォームとしては、

のようになり、
ボタンとして実装されたアンケート回答をクリックすると、

と表示され、
次回このページを訪れた場合には、

このようにアンケートの形跡も無いスッキリした表示となります。
アンケート集計
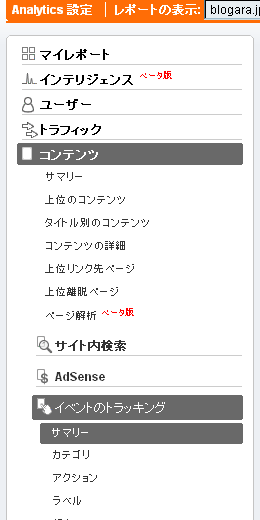 このアンケートを設置したのは先月19日となり既に半月が経過していますので、現時点でのアンケートの集計結果が確認出来ます。
このアンケートを設置したのは先月19日となり既に半月が経過していますので、現時点でのアンケートの集計結果が確認出来ます。
イベントトラッキングのデータは、GAの メニュー / コンテンツ / イベントのトラッキングから確認出来ます。
イベントのトラッキングをクリックした後に右側のメイン画面に表示されるのがサマリーとなります。
サマリー画面では以下のようにイベントの概要を確認出来ます。
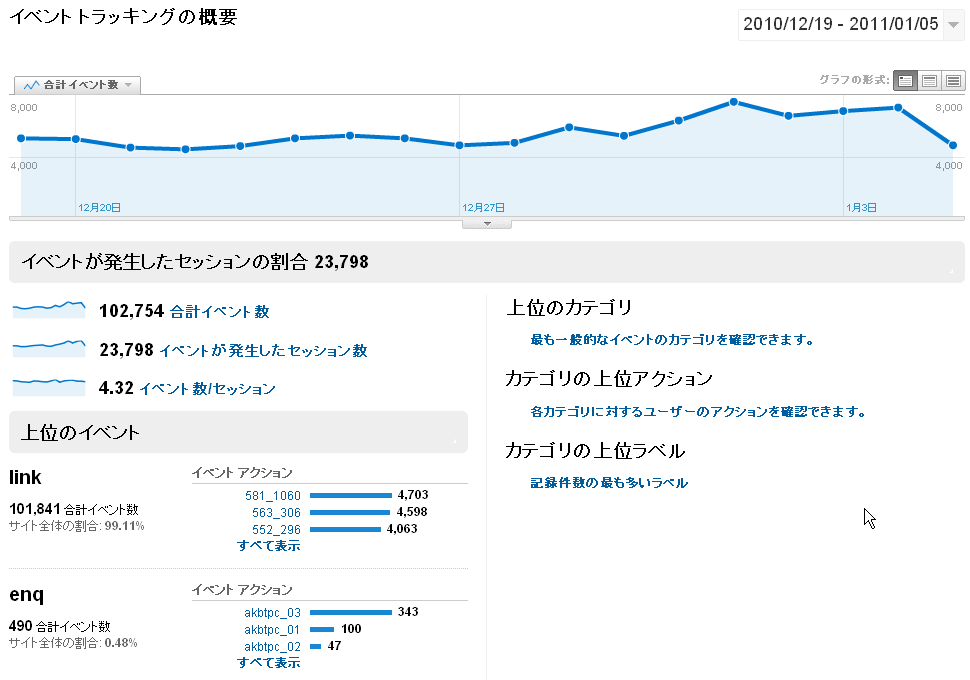
後は通常のGAの各種操作が可能になり、例えばアクションakbtpc_03をクリックし、そこからそのアクションを行ったユーザーの参照元やキーワードを確認出来ます。
二重回答のチェック
このようなWeb上でのユーザー登録を伴わないアンケートでは、回答済みか否かのチェックは大抵Cookieを利用しています。 よって、多少そのあたりの事情を知るユーザーがCookieを削除し複数回の回答を行う事も十分考えられます。
今回は単なる意見募集としてのアンケートなのでそこまで工作するほどのものではありませんが、 例えば人気投票のような、ランキングとして発表されるケースでは注意する必要があります。
残念ながらGAの集計情報の元となるのはクライアントからの自称情報なので、手の込んだ工作に対応する事は正直難しいと言えます。
このような場合、同一人物かの判定を行う参考材料としてIPアドレス帯が利用されますが、 GAではユーザーのIPアドレスが把握出来ずそれが出来ません。
その為、とりあえず今回のアンケートでは、サービスプロバイダと都市の組み合わせを確認し、 それほどメジャーでは無いプロバイダと都市の組み合わせでの回答が多い場合には、 さらにその詳細を分析し、不自然な点が見受けられる場合にはその大半を無効票として判断しています。
結果
このように簡単なアンケートであるなら、設置の容易さと共に集計結果の確認の際に使い慣れた機能を使えるGoogle Analyticsのイベントトラッキング利用は非常に有効であり、 強くお勧め出来る手法となります。
ただ、イベントトラッキングに関しては"誰が"よりも"何を"したかに重点がおかれていますので、 "誰が"(というかどのようなユーザーが)アンケートに回答し、そのユーザーがどのようにサイトを利用しているかを知りたい場合には、 イベントトラッキングと共にユーザー定義を利用するのが良いかと思われます。
PHP5.2以前の環境でのjson_encode
WebアプリとAjaxとJSON
一昔前のWebアプリの動作環境といえば、PC上のIEかFirefoxだけをサポートすれば問題無かった。 その為、画面出力としてサーバー側で生成するHTMLもそれらに合わせれば良いだけなので、それほど問題にはならなかった。
が、現在の高機能スマートフォンに加えダブレット型PCなども普及し始めている状況では、 それらを含め複数の環境に対応する為に、サーバー側で一々それぞれに合わせたHTMLを吐くのではコストが掛かる。
その解法の一つとして、MVCのVC部分をクライアント側に移譲する事を可能にするJavaScriptが活用されている。
クライアントはそれぞれのページ表示に必要なデータをサーバーにリクエストし、 サーバーではそれがどのような形式で表示されるのかは関知せず、要求されたデータだけを返す。 そこで利用されるのが、所謂Ajaxと呼ばれる機能であり、サーバーからクライアントに渡されるデータの形式として広く利用されているのがJSONとなる。
この一連のJavaScriptによるページ更新では基本的にページ遷移を伴わない為に、サーバー/クライアント側の負荷軽減と、
ネットワークトラフィックの削減、レスポンス速度向上によるユーザビリティ向上が望める。
# 中途半端なJavaScript利用の失敗例として、逆に負荷が増し機能性も落ちるなどのようなケースもあり、
# 実際にそのような残念サイトも存在するが。
一般ユーザー向けサイトでのJavaScript
ここで問題となるのが一般ユーザーのJavaScript利用率であるが、JavaScriptが利用出来ない/意図的にOffにしているユーザーは既に2%ほどだとい調査もある。 How many users have JavaScript disabled?
JavaScript(に加え色々と)利用不可な所謂ケータイが現在も大きなシェアを持っているであろう日本の状況は多少異なると思われるが、
それでもJavaScriptが動作する環境は広く普及し、尚且つJavaScriptが有効である事を前提とした大手サイトが多い事もJavaScriptの援護となっている。
# と言いつつ個人的にはFirefoxのNoScriptを常用しているので、
# 殆どのサイトのdefaultではJavaScriptOFFの状態ではあるけれども。;)
特定ユーザー向けサイトでのJavaScript
このような状況ではあるが、実際には一般ユーザー向けサイトでは、フルJavaScript動作のWebアプリとするのは残念ながら時期尚早。 が、利用環境をある程度限定出来るBtoBサイトやWebアプリの管理機能や社内向けなどでは既に広くJavaScript化が進んでいる。
という訳で、現在行っているECサイト案件でも管理画面では全面的にJavaScriptを利用しており、 サーバーからクライアントへのデータ形式にはPHPスクリプトで生成したJSONを使っている。
バージョン間の差異
現在の開発環境はPHP5.3.xを使っているが、まだPHP5.2系の環境も多い為に基本的には5.2.xでの動作を前提としている。 が、そのECサイトのPHPのバージョンは5.1.x。
現在のバージョンが5.1.xなのは最初から判っていた事ではあるが、 4.xから5.xのようなメジャーバージョンが上がるようなアップデートを躊躇するのは判るけれども、 今時5.1.xのような中途半端に古いバージョンを使い続ける理由も無いだろう。 というような甘い見通しを立てて、実装時についでにPHPのバージョンアップも行おうと目論んでいたが、 色々と理由を提示されてどうもそれが難しい模様。
過去に遭遇したらしい環境移行でのトラブルがトラウマ?となっている様子も伺え、
現在正常に動いている物をわざわざ変更する必要は無いと考えるのも無理は無いと受け取り、
とりあえず5.1.x上での動作確認を行う事にする。
# 自分に都合の良い環境を前提とするのでは無く、開発環境を実動環境に合わせるのが常識なのだけれど、
# 動作環境の選択で比較的融通が利くWeb系故の甘さという感は否めなく、今回の反省点でもある。
json_encode
ここで問題となったのが、クライアントに渡すJSONデータを生成するjson_encodeが5.1.xで利用不可な点。
前述のように、管理機能でのサーバーからクライアントへのAjaxのレスポンスとしてのデータ送信ではJSONを利用しているので、 json_encodeは非常に重要で必須なコア機能となっている。
が、無い物は仕方無く、無ければ自分で書けば良いのはプログラマ的な常識なので、その方向で対応を行う事にする。
という訳で、PECLを使うのもアレだと思いつつ、json_encodeの動作や上記ページのコメントやServices_JSONのソースを読み、 簡易版のjson_encodeを書いて見た。
MITライセンスの元での公開なので利用はご自由に。
if ( !function_exists('json_encode') )
{
function json_encode( $array )
{
if( !is_array($array) )
return _js_encValue( $array );
$assoc = FALSE;
if ( array_diff(array_keys($array),range(0,count($array)-1)) )
$assoc = TRUE;
$data = array();
foreach( $array as $key=>$value )
{
if ( $assoc )
{
if ( !is_numeric($key) )
$key = preg_replace('/(["\\\])/u','\\\\$1',$key );
$key = '"'.$key.'"';
}
$value = _js_encValue( $value );
$data[] = ($assoc ? "$key:$value" : $value);
}
if ( $assoc )
return "{".implode(',',$data)."}";
else
return "[".implode(',',$data)."]";
}
function _js_encValue( $value )
{
if ( is_array($value) )
return json_encode( $value );
else if ( is_bool($value) )
return ($value ? 'true' : 'false');
else if ( $value === NULL )
return 'null';
else if ( is_string($value) )
return '"'._js_toU16Entities($value).'"';
else if ( is_numeric($value) )
return $value;
return '"'.$value.'"';
}
function _js_toU16Entities( $string )
{
$len = mb_strlen( $string, 'UTF-8' );
$str = '';
$strAry = preg_split( '//u', $string );
for ( $idx=0, $len=count($strAry); $idx < $len; $idx++ )
{
$code = $strAry[$idx];
if ( $code === '' ) continue;
if ( strlen($code) > 1 )
{
$hex = bin2hex( mb_convert_encoding($code,'UTF-16','UTF-8') );
if ( strlen($hex) == 8 ) // surrogate pair
$str .= vsprintf( '\u%04s\u%04s', str_split($hex,4) );
else
$str .= sprintf( '\u%04s', $hex );
} else {
switch ( $code )
{
case '"':
case '/':
case '\\':
$code = '\\'.$code;
}
$str .= $code;
}
}
$str = str_replace( array("\r\n","\r","\n"), array('\r\n','\r','\n'), $str );
return $str;
}
}
変更点: 2011/02/16
改行コードがエンコードされておらず、IEでのデコードに失敗する場合があった為、
改行コードもエンコードするように修正。
また、画像データなどサイズの大きいデータをエンコードする場合には非常に遅かったのを多少改善。
JavaScriptとPHPでの特殊アルファベット文字の扱い
これは元々2010/03/05にAmebloに投稿した記事です。
Wikipedia: ダイアクリティカルマーク
F1 2010年シーズン開幕
数年続いた強豪2,3チームによる独占安定(故にそれほど面白く無い)シーズンから一変し、
新興チームの興隆や上位チームの実力拮抗により、非常に面白い展開となったF1 2009シーズン。
その2009年シーズを経て迎えた2010年シーズンは、
有力ドライバーの移籍などもあり否が応にもさらに注目されます。
そこで、今年度も面白い展開となるのではという期待を込めて、BlogaraでもF1選手権 2010のテーマを追加しました。
多くのチームやドライバーはNewsフィード配信や、Twitter、
あるいはブログでは有りませんがFacebookを利用した情報発信を盛んに行っていますので、
Blogaraで取り上げる意義があるテーマとも言えます。
特殊アルファベット文字
F1には欧州や南米を中心とし数多くの非英語圏ドライバーが参戦していますので、
# というより英語圏ドライバーの方が少数ですが
a-Zの基本的なアルファベットで表記出来ない名前もそれなりに存在します。
そこでこの機会に、ドイツ語のウムラウトなど、
各種言語で一般に使われる特殊アルファベット(ダイアクリティカルマーク付きなど)
もアルファベット表記の名前として許可するような変更を行います。
3種類の名前表記
Blogaraでのメンバー(個人/団体/グループ)名表記では、
任意の名前(name)、カタカナ表記のフリガナ(fname)、アルファベット表記の名称(aname)
の3パターンが存在します。
任意の名前は、実際にクライアント側で(フォントが用意されて)表示出来るか否かに関係無く、
Unicodeで定義される数多くの文字を許容しますが、
Blogaraは現在日本語を主とするサービスですので、非日本語の名称ならば基本的にカタカナで表記を行っています。
フリガナは、ヰヵなど利用頻度が少ない文字も含め、全角(fullwidth)カタカナでの表記となります。
そしてアルファベット表記の名称は、
所謂7bit ASCIIコード帯に存在するa-Zの基本的なアルファベット文字(それとハイフン)だけを許可していました。
Blogaraは、サーバー/クライアント側双方でUnicode(UTF-8)ベースのシステムですので、
(非サロゲートペア帯の)Unicodeで定義される文字なら特に何のひねりも無く利用出来ます。
その為、その殆どがUnicodeで定義されると思われる特殊アルファベット文字への対応も簡単です。
# 逆に言うとUnicodeで定義されていない特殊アルファベット文字には対応しません。
勝手に定義した特殊アルファベット文字のような言葉で一括りに表現していますが、
実際には各言語でユニークな文字、あるいは各言語間で微妙に異なる数多くの文字が存在します。
そこで今回は、Unicode 5.2 Character Code ChartsのLatin-1 Supplementの一部からLatin Extended-Bの範囲まで、
U+00C0からU+024Fまでを(こちらの独断と偏見により)特殊アルファベット文字として扱う事にします。
クライアント側(JavaScript)での対応
FormControlへの追加変更
Blogara管理画面でのメンバー登録は、通常のWebアプリと同様にHTMLの入力フォームで行う形となりますが、
JavaScriptによりWebフォームに機能追加するFormControlを利用していますので、
その機能を利用した入力値の検証と変換が可能となります。
アルファベット名称を記入する項目には、
1. 全角文字を半角(halfwidth)に変換
2. a-Zのアルファベットと数値と半角スペース以外を削除
という強制変換が設定されていますので、
この2.に、特殊アルファベット文字も非削除文字として扱う条件を加えます。
正規表現による制限
この指定文字種別以外の文字を削除する処理は、正規表現を利用した一括変換を行います。
実際の正規表現指定は下記のようなidとパターンの組み合わせで記述していますが、
ここにU+00C0からU+024Fまでの特殊アルファベット文字帯をlatinExとして追加します。
Du.Type = new Hash({
CodePattern: {
alpha: 'a-zA-Z',
number: '\\d',
alnum: 'a-zA-Z\\d',
latinEx: '\\u00c0-\\u024f',
spaceH: '\\u0020',
アルファベット表記の名称(aname)のFormControlでの指定では、
'aname':{require:true, force:Du.Force.Ja.setForces(['df_ftoh',
{id:'df_purge',opt:{code:['alnum','latinEx','spaceH'],except:'\-'}},'df_space']),
type:Du.Type.setTypes([{id:'dt_limit',opt:{'max':80}}])},
のようになっていますので、
この指定文字種以外を削除する設定(dt_purge)で指定されるalnum,latinEx,spaceHの正規表現パターンを
初期化処理時にRegExpオブジェクトとして生成します。
new RegExp( '[^'+regStr+']', 'g' );
後は、各入力値チェック処理時に上記のRegExpを使ったreplace(変換後文字列に空文字を指定)を適用します。
サーバー側(PHP)での対応
一般のWebアプリでは、
入力値の検証や加工はクライアント側だけでは無くサーバー側にも実装されている必要が有ります。
しかし、今回のように社内(あるいは許可を得た限られた人間)だけで利用するシステムでは、
クライアント側でのJavaScriptの実行を必須と規定していれば、
サーバー側のPHPに文字種別による削除の実装が絶対に必要という訳ではありません。
が、一種のフールプルーフ目的や、今後WebAPI経由などのでのデータ取得時にも適応可能とする為に、
サーバー側スクリプトにも強制変換や指定文字種以外の削除コードを実装しています。
TextControlへの追加変更
サーバー側スクリプトでの非許可文字種以外の削除は、PHPでのカタカナ/ひらがなのローマ字変換でも言及した、
文字列操作クラスであるTextControlに追加実装を行います。
サーバー側PHPによる文字種別による削除においても、
基本的には、クライアント側と同様に正規表現による一括変換となります。
ここでも特殊アルファベット文字指定としてCNV_MD_LATINEXのような正規表現パターンを追加し、
preg_replaceにて指定文字帯以外を削除します。
# ソースコードもUTF-8なので、À-ɏのような全ての環境で表示される訳では無い文字を利用していますが、
# 問題になるようなら(というより気持ち悪いのであれば)文字参照指定から文字に変換しての指定で。
# html_entity_decode('À',ENT_NOQUOTES,'UTF-8').'-'.html_entity_decode('ɏ',ENT_NOQUOTES,'UTF-8');
if ( $mode&CNV_MD_ALPHA ) $reg .= 'a-zA-Z'; if ( $mode&CNV_MD_NUM ) $reg .= '\d'; if ( $mode&CNV_MD_LATINEX ) $reg .= 'À-ɏ'; return preg_replace( '/[^'.$reg.']/u', '', $str );
結果
今回行った、特殊アルファベット文字をアルファベット表記の名称として利用出来るようにする変更により、
Nico HÜLKENBERGや、
Sébastien BUEMIのような名前も登録可能となり、これにてひとまず完了となります。
参考資料
Unicode 5.2 Character Code ChartsWikipedia: ダイアクリティカルマーク
ブログページからのブログ関連情報取得
これは元々2009/11/09にAmebloに投稿した記事です。
RFC2616: Hypertext Transfer Protocol -- HTTP/1.1
PHP DOM XML extension encoding processing []
入力補助機能
今回は名前のフリガナのカナからローマ字への変換に引き続き、登録/入力作業の補助機能を実装します。
WebAPIの利用やカナのローマ字変換により、個人データの登録はかなり楽になったものの、
テーマ:AKB48やテーマ:東京ガールズコレクション09AWのような、大量のブログがあるテーマの登録作業では、
余にもブログ情報の登録が単純作業過ぎる為にうんざりしましたので、それを改善すべく機能を追加します。
# Blogara的には、映画やTVドラマのように数件しかブログが無いテーマに比べると非常に有り難い存在ですが。
ここではブログのURLをフォームに入力し、
URLで指定されたHTMLからタイトルとFeedURLを取得するという単純な機能の実装を行います。
フォームの入力とAjaxリクエスト
登録作業と処理の流れとしては、
ブログURL入力フォームに追加したブログ情報を取得ボタンのクリックにより
フォームに入力されたブログURLをサーバーにAjaxで送信。
サーバー側スクリプトではその指定URLをリクエストしHTMLを取得、
そのHTMLからタイトルとFeedURLを抽出し、Ajaxリクエストのレスポンスとしてクライアントに返す。
クライアントでは、レスポンスからタイトル/FeedURLを取得し該当フォームに値を設定。
タイトルが長すぎる場合にはpowered by なんちゃらなどの部分を適宜(手動で)削除し登録。
と、なります。
Ajaxは、Blogaraの管理フォームで使われるFormCtrlに搭載される機能を使い、
ボタンクリックによる反応や、レスポンスを受け取った後の処理もJavaScriptで行いますが、
今回の記事では、PHPによるサーバー側の処理をメインに記述します。
PHPでの実装
HTTPとHTML
PHPでのHTTPリクエストとHTMLデータの解析という事で、
基本的には共有Feedの管理の回と同様のものとなり、かなりの部分を流用出来ますので、
既にBlogaraに実装されている各種クラスを利用します。
今回はXMLでは無くHTMLデータですが、このようなケースを想定?して、
XMLとHTMLを同様に扱えるDOMDocumentの利用を選択した事は、どうやら正解だった模様です。
DOMDocumentのencoding
DOMDocument(PHP 5.2.10)では、各種メソッドを使ったノード値や属性値の取得を行った場合には、
自動的に文字エンコードがUTF-8に変換された文字列となります。
ただしそれが保証されるのは、文字エンコードが明示的に指定されている場合だけになります。
XMLでは、先頭のXML宣言(<?xml version...)でencoding属性を使い指定されている文章が殆どですが、
HTMLでは、相変わらずmetaタグのhttp-equiv="Content-Type"のcontentで、
charsetが指定されていない残念なページが多数存在し、また現在も生産され続けています。
文字エンコードが指定されていない文章をloadXMLやloadHTMLで読み込んだ場合には、
DOMDocumentのencodingデータメンバにはNULLが設定され、エンコード不明扱いとなります。
XMLの場合には、元がUTF-8以外の文字コードのデータでは非ascii文字?が出現した時点で
UTF-8では無い文字が含まれているというWarningを吐きloadXMLも失敗しますが、
元の文字コードがUTF-8ならそのまま通常通りUTF-8でのデータの取得が出来ます。
一方HTMLの場合には、元が非UTF-8かつ非asciiな文字コードでは勿論、
元がUTF-8のデータであっても、変換後はUTF-8でも無い文字化けした文字列となります。
さらにHTMLのヘッダでcharsetが指定されている場合でも、
そのmetaの前にtitleなどで日本語などが使われている場合には、
encoding不明と同様に文字化けが発生しますので、loadHTMLを使う時には注意が必要です。
またXHTMLの場合には、metaでのcharset指定では無く、xml宣言でencoding指定が行われていればokのようです。
Blogaraではencodingが不明なHTMLデータに対しては、
HTTPヘッダのContent-Typeでcharsetが指定されている場合にはその設定を使い、
それも指定されていない場合には、mb_detect_encodingで文字コードを検出し、
元のデータの<head>を
<head><meta http-equiv="Content-Type" content="text/html; charset='.$encode.'" />
で置き換えるという($encodeには文字エンコード文字列が指定)、
あまり深く考え無い強引な手法で変換し、もう一度loadHTMLでデータを読み込ませるようにしています。
追記: (2009/11/10)
その後DOMDocumentとencodingについて、
PHP DOMDocument encoding loadHTMLあたりでググってみますと、
ZendFrameworkのチームメンバーの方が書かれたDOMDocumentと文字コードの関係についての記事が見付かり、
要するに文字エンコードが未指定のHTMLの場合には、元の文字コードをISO-8859-1だと判断して、
それをUTF-8に変換している為奇妙な事になっていた模様です。
一方loadXMLの場合にはdefaultでUTF-8として扱っていたために、UTF-8のデータならokという事です。
ブログタイトル
ブログURLで指定されたHTMLをDOMDocumentに読み込んだ後は、そこから目的のデータを取り出します。
ブログのタイトルは、Feedのtitleでは無くこのHTMLのtitleから取得します。
$blogInfo = array(); $title = $this->doc->getElementsByTagName( 'title' ); if ( $title && $title->length ) $blogInfo['title'] = $title->item(0)->nodeValue;
FeedURL
FeedのURLは、linkタグのtype属性を見て判断し、そこのhref属性で指定されたURIをFeedURLとして取得します。
またRSSのバージョンなどはtitle属性で指定されているケースが多いですので、title属性も利用します。
ブログサイトによってはFeedが複数タイプ(RSS1.0/2.0 Atom0.3/1.0など)配信されている場合がありますので、
HTMLのヘッダに記述されている全ての候補をXPathで取得した後、
BlogaraでのFeedの優先順位(RSS2.0 > RSS1.0 > Atom1.0)に従いFeedURLを1つ決定します。
$nodeList = $this->xpath->query( "//link[@type='application/rss+xml'] | //link[@type='application/atom+xml']" );
if ( $nodeList && $nodeList->length )
{
$feed = array();
foreach ( $nodeList as $item )
{
$cur = array();
$node = $item->attributes->getNamedItem('href');
if ( $node )
$cur['feed'] = $node->nodeValue;
if ( !$cur['feed'] ) continue;
$node = $item->attributes->getNamedItem('title');
if ( $node )
{
if ( preg_match( '/((?:RSS(?:\s*\d\.\d)?)|(?:Atom))/iu', $node->nodeValue, $ma ) )
$cur['type'] = strtolower( preg_replace('/\s/u','',$ma[1]) );
}
if ( !$cur['type'] ) $cur['type'] = 'unknown';
$feed[$cur['type']] = $cur['feed'];
}
}Feedの存在確認
FeedURLが決定した後はそのFeedが実際に存在しているかの確認を行います。
ブログサイトでは一般的にブログHTMLとFeedXMLを同じシステム上で生成していますので、
ブログHTMLに記述されているFeedが存在しないという事はあまり考えられませんが、
リダイレクトで飛ばす"一部の"ブログサイトも存在しますので、
存在確認と共に無駄なトラフィックを減らす為にリダイレクト先の現在有効なFeedURLを取得します。
for ( $n = 0; $n < 3; $n++ )
{
// redirectに従うのは2回まで。
$ret = $this->checkURL( $blogInfo['feed'], $head );
$resHead = &$ret['head'];
if ( $resHead['_stat']['status'] == '200' ) break;
else if ( strncmp($resHead['_stat']['status'],'3',1) !== 0 || !$resHead['Location'] ) {
$blogInfo['feed'] = '';
break;
}
$blogInfo['feed'] = $resHead['Location'];
}
HTTP HEAD/GET
上記のFeedのチェックでは、HTTP GETでリクエストを送っています。
存在確認だけならHTTP HEADを使えば良さそうなものですが、
"一部の"Webサーバーでは、GETのリクエストでは302 Foundを返すにも拘わらず、
同一URIのリクエストに対し、何故かHEADでは302 Foundを返さずに200 OKを返す面倒なサーバーがあるので、
GETで行う事になりましたというオチです。
RFC2616: Hypertext Transfer Protocol -- HTTP/1.1には、
The metainformation contained in the HTTP headers in response to a HEAD request SHOULD be identical to the information sent in response to a GET request.
とあるので、GETと同じヘッダを返すべきだけであって、そうしなければならないという訳でも無いので、
そのサーバーがそのようなアレな仕様だと納得するしかありませんが。
操作
ブログURL欄にURLを入力し、ブログ情報を取得をクリックすると、
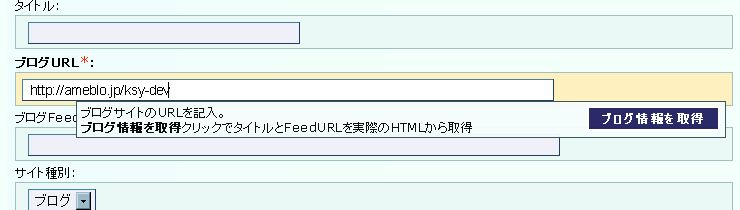
大抵は1秒も掛からずに、タイトルとFeedURL欄には実際のHTMLから取得した値が設定されます。
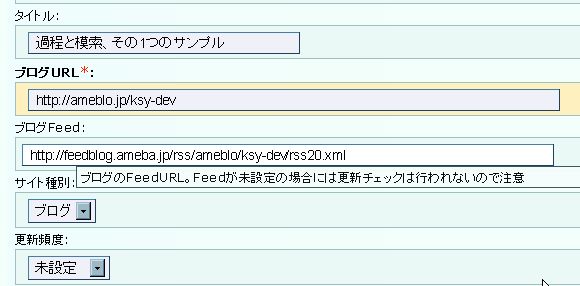
入力補助機能
今回は大した事は行っておらず実装も簡単ですが、
何十件何百件も入力を行う際には地味ながらにもかなり役に立つ機能となります。
入力作業のようなUIのユーザービリティというものは、初期の設計段階で全てを想定するのは難しく、
このように実際に利用してみたユーザーからのフィードバックでさらに機能性が向上する典型的な要素ですので、
UI周りは柔軟性/拡張性を持った設計/実装にすべきだと思われます。
# 一人開発/運営体制のBlogaraのように開発者=ユーザーとなるケースは少ないでしょうが、
# 実際に開発側の人間がそれなりに使い込んでみるのが一番判りやすいのかもしれません。:)
参考資料
PHPマニュアル: DOMDocument::loadHTML - DOMDocumentのHTMLデータでの文字エンコードの扱いについてRFC2616: Hypertext Transfer Protocol -- HTTP/1.1
PHP DOM XML extension encoding processing []
複数執筆者による共有Feedの解析と更新管理 Part2
これは元々2009/10/26にAmebloに投稿した記事です。
Feed(フィード)を共有するブログ
前回の記事までで、複数の執筆者が共有するWebFeed(フィード: RSS1.0/2.0/Atom1.0)から、
個々の執筆者による最新更新記事のデータを取得するまでは完了しましたので、
今回は、それらをどのように管理するかについてを記述します。
Blogaraでのユーザーやブログの管理
ユーザー/ブログテーブル
ブログ情報サイトBlogara:ブロガラでは、1個人や1テーマ公式サイトをユーザーと呼び、
それらのユーザーがBlogaraでの基本管理単位となります。
従ってミュージシャンのグループやお笑いのコンビなども、
個々人の名前が表に出ているようなら、グループ単位では無く基本的には個人単位での登録となります。
それぞれのユーザーは、ユーザーテーブルに1レコードを持ち、
各種記事更新サイト(blog/twitter/ニュース/コラムなど これらを総称してブログと呼ぶ)
を管理するブログテーブルに複数レコードを所有出来ます。
ユーザーテーブルはユーザーID/氏名/性別/生年月日/肩書/公式サイトURLなど各ユーザー固有の情報を管理し、
ブログテーブルは、ブログID/ブログURL/FeedURL/更新頻度などのブログ管理に必要なカラムを持ちます。
1ユーザーは複数のブログを所有し、1つのブログが複数のユーザーに関連付けられる場合もありますので、
ユーザーとブログの関係は、ユーザーIDとブログIDをカラムに持つブログユーザーテーブルに登録されます。
ブログの更新情報テーブル
ブログテーブルには記事題名や本文のような記事内容に関連するカラムは存在していません。
現在のBlogaraは、各ブログの最新更新1件分のデータだけを管理/保存していますので、
ブログとブログ更新情報(記事内容)は1対1の関係となり、ブログテーブルに各カラムを作成し、
ブログテーブルで更新情報を管理するという選択肢も有りました。
が、今後複数の更新情報を保持するような仕様変更を行うケースを考慮し、
さらにはブログテーブルが巨大化するのも好ましく有りませんので、
ブログID/記事題名/記事本文/更新日時などのカラムを持つブログ更新情報テーブルを利用しています。
ブログ更新記事の取得
Pull型でのFeed取得
BlogaraではcrontabにFeed取得/更新スケジュールを設定し、
定期的に更新プロセスを走らせ各Feed配信サイトへのリクエストを行い、
レスポンスとして返されたFeedデータから更新情報を取得しています。
2009年10月時点においてBlogaraには未だ数百件のブログが登録されているだけですが、
いずれ数千件以上登録されているであろうブログの更新情報取得を、
何も考えずに全てのブログを対象とし1つのプロセス上で行う事は賢い実装とは言えません。
これが自らが管理するサーバーを対象とした内部ネットワーク内での話なら多少強引な手法としてアリでしょうが、
外部ネットワークを経由した外部サーバーへの問い合わせについては、
ディレイやタイムアウトが発生する可能性を考慮する必要がある為、
大量のFeed取得リクエストを1つの待ち行列に詰め込む事はリスクが高すぎます。
これは大量のメールを配信するようなサービスと同様の課題になります。
ブログ更新頻度設定
その対策の一つとしてBlogaraでは、
更新処理対象のブログを選別し、毎回全てのブログの更新チェックをする事の無いようにしています。
これには、ブログ登録時に選択するブログ更新頻度設定を利用します。
これは数値1から9までで設定される値となり、執筆者がどのくらいの頻度でブログを更新するかによって決定されます。
# ここ最近約1ヶ月分の更新を目視で確認し手動で設定していますが、
# かなり手間の掛かる作業になっていますので、これも自動化すべき優先項目の一つになっています。
更新頻度1が設定されたブログは更新チェックプロセスで毎回Feedのリクエストを行い、
最も低い更新頻度9のブログは、約1%の確率で更新チェックを行います。
が、1%ともなると数日間更新が反映されない恐れもありますので、
サーバー/ネットワーク双方の負荷が軽くなるであろう毎日午前5時に行われる更新チェックでは、
Blogaraに登録されている全てのブログについてのチェックが行われます。
複数プロセスでの並列分散処理
結局一日一度は全ブログのチェックを実施するので、
やはりオーソドックスに並列分散処理という定番の実装を行います。
個々の処理間での依存性が高いケースでは、並列分散処理にもそれなりの設計が必要ですが、
今回のようなブログのFeedデータの取得と更新情報抽出という処理では、
個々のブログ間での依存性は皆無となりますので、単純に振り分けるだけで問題無い容易なケースとなります。
要するに、行列を1列に並ばせるのでは無く5列に分け、個々の行列の長さを短くするようなイメージです。
Blogaraでの更新チェックでは、
crontabに登録したスケジュールで直接呼ばれるコマンド(PHPスクリプト これを便宜上マスタープロセスと呼ぶ)で、
まず実行する更新チェックプロセス(これもPHPスクリプト 同様に実行プロセスと呼ぶ)数を決定し、
ブログ更新管理テーブルにマスター+実行プロセス数分のレコードを作成します。
マスタープロセスでは、
総実行プロセス数とその実行プロセスに割り当てられたシリアル番号(0から総実行プロセス数-1まで)を引数として、
各実行プロセスをバックグラウンドジョブとして起動します。
呼び出された実行プロセスでは、引数で与えられた総実行プロセス数($nProc)と、
この実行プロセスに割り当てられたシリアル番号($index)を使い、処理対象となるブログを決定します。
BlogaraでのブログID(idBlogカラム)はAUTO_INCREMENTな数値なので、
個々の実行プロセスで処理対象となるブログの選択は、
クエリのWHERE句で、WHERE idBlog%$nProc=$indexのように指定し、
DBからのSELECTでのレコード抽出時に行われます。
全ての実行プロセスが終了した時点で、
今回記事が更新されたブログを所有するユーザーが所属するテーマ関連のファイル(JSONとAtomFeed)を更新し、
一連のブログ更新チェック処理が終了します。
共有Feedでの更新情報管理
今回の本題
と、1ユーザー専用Feedの場合には相変わらず上記のようなシンプルな処理で問題無いのですが、
複数ユーザー共有Feedでは考慮すべき点が有ります。
共有Feedから個々のユーザーについての更新情報の取得は前回の記事で行いましたので、
超絶手抜き実装としては、Feedを共有するブログそれぞれに同一のFeedを設定し、
専用Feedブログと同様にそれらのFeedを持つブログ毎に、
何度も同一Feedのリクエストを行というプランも可能ですが、あまりにも無駄過ぎてお話になりません。
前回の記事の指針にも書いたように、複数ブログで共有するFeedについては、
更新チェック処理中に一度だけリクエストを行い、
そのFeedデータから共有する全てのブログの更新情報を取得するようにする必要が有ります。
マスター/スレーブ ブログ
そこでBlogaraでは、Feedを共有するブログを1つのマスターブログと複数のスレーブブログに分け、
Feedの情報を管理するのはマスターブログだけにし、
スレーブブログのFeedカラムはNULL値のままとします。
元々、ブログとしては存在するがFeedを配信しない残念なサイト用にFeedカラムにNULL値を許可し、
更新チェック処理での対象ブログ選択のクエリには、
WHERE句でfeed IS NOT NULLという指定を行う事で更新チェック対象から除外していますので、
NULL値が設定されているスレーブブログも自動的に更新対象外ブログとして扱われます。
このマスター/スレーブを導入する為に、ブログテーブルにはidMasterというカラムを追加し、
マスターブログであるならば0、スレーブブログならマスターブログのブログIDが格納されます。
また専用Feedの通常ブログはdefaultのNULL値のままとなります。
更新チェック処理では、対象ブログ選択時にidMasterの値も取得し、
それが0のブログはマスターブログである可能性があると判断し、
Feedを共有するスレーブのブログ(idMasterに今回のマスターのブログIDが格納されている)の
ブログIDとセレクタ(XPath式)を取得し、
マスターブログのFeed取得と解析の"ついで"に、それら全てのスレーブの更新情報の取得も行います。
マスターブログの選択
Feedを共有するブログの中でどのブログをマスターに設定するかですが、
マスターブログの削除や更新停止設定はスレーブにも影響しますので、
なるべく変更が無いブログを選択する事が望ましくなります。
共有Feedを配信するブログページでは大抵、全てのブログの更新情報を表示する一覧ページが有り、
また、個々の執筆者専用のページも用意されているケースが多くなりますので、
マスターブログはFeedを共有するそれらのブログの一覧ページとなり、
スレーブブログは個々の執筆者専用ページになるのが典型的な構成と言えます。
前回に取り上げた、
テーマ: アイドリング!!!に登録されているアイドリング!!!ブログ「煮詰まります!!!」や、
テーマ: NFLのNFL JAPAN コラムでも、
それぞれの一覧ページがマスターページに設定され、
個々のメンバー/コラム執筆者の個別ページへのリンクと
Feedで執筆者を特定するセレクタ(XPath式)が設定されたブログがスレーブブログとなります。
また、マスターブログのセレクタには何も設定されていませんので、
誰の記事かは関係無くFeedを共有するブログの中での最新の更新記事(要するに専用Feedと同様に先頭の記事)
マスターブログの更新情報レコードとしてDBに登録されます。
上記2例の場合には、マスターブログとなるブログ一覧ページは、
それぞれアイドリング公式サイトとNFL Japan公式サイトが所有するブログという扱いとなるので、
独立したブログとして扱いやすいマスターブログとなります。
が、複数執筆者での共有Feedを利用し、ブログ一覧ページと個々人専用ページが存在しているとしても、
本来ならマスターブログとなる一覧ページをどのユーザーが所有するのか分類が難しいケースも有ります。
例を挙げると、テーマ: AKB48のグループ内ユニットノースリーブスのブログでは、
ブログを執筆する個々のメンバーは当然個人として登録されていますが、ユニット自体は登録されていません。
その為、通常はマスターブログとなるメンバー一覧ページを所有するユーザーが存在しませんので、
このケースでは五十音順での先頭となる小嶋陽菜氏のブログをマスターブログとして設定し、
//rss1:item[dc:subject='小嶋 陽菜'][1]/*のようなXPath式をセレクタとして指定する事で、
マスターブログでありながら個々人専用のブログの更新情報を管理するブログとなります。
このように少人数の共有Feedブログの場合には、一覧ページがマスターブログとなるのでは無く、
あるメンバーがマスターブログとなり、その他のメンバーがスレーブブログとなる構成の場合も有ります。
実装
Feedデータの取得と解析処理は、ネット経由での情報取得クラスのサブクラスとして実装していますが、
下記のコードはその一部分となります。
Feedデータからの更新情報取得では、まずFeedURLをリクエストし、
レスポンスとして返されたFeedデータをDOMDocumentクラスのloadXMLで読み込みます。
そのデータに対しそれぞれのブログで設定されたセレクタ(XPath式)を使い(未設定の場合は先頭のitem/entryノード)、
更新記事情報として必要なデータ(題名/本文/更新日)を取り出すretrieveFeedDataメソッドを呼び出します。
protected function initDocument( &$head, &$dataStr ) {
if ( !$dataStr ) return NETCHK_EMPTYDATA;
// headのContent-Typeにはtext/htmlとあるが、bodyはxmlデータという面倒なサイトに対応
if ( stripos($head['Content-Type'],'xml') !== FALSE || (preg_match('/<?xml /i',$dataStr) && !preg_match('/<html\W/i',$dataStr)) )
{
$head['_meta']['type'] = 'xml';
if ( !@$this->doc->loadXML($dataStr) ) return NETCHK_INVALIDXML;
} else if ( !$head['Content-Type'] || stripos($head['Content-Type'],'html') !== FALSE ) {
$head['_meta']['type'] = 'html';
if ( !@$this->doc->loadHTML($dataStr) ) return NETCHK_INVALIDHTML;
} else
return NETCHK_UNKNOWNFORMAT;
$this->xpath = new DOMXPath( $this->doc );
return TRUE;
}
public function checkUpdate( $feed, $lastMod=NULL, $ETag=NULL, &$slaves=NULL ) {
//
// ここでFeedURLからのFeedデータ取得処理やレスポンスヘッダの値による判定処理が有りますが省略。
//
$ret = $this->initDocument( $head, $body );
if ( $ret !== TRUE ) return $ret;
$ret = $this->parseFeedData( $slaves );
if ( !is_array($ret) ) return $ret;
//
// レスポンスヘッダのLast-ModifiedやETag関係の処理が有りますが省略。
}
public function parseFeedData( &$slaves=NULL ) {
$nodeList = $this->xpath->query( '/*[1]' );
$root = $nodeList->item(0);
if ( !$root )
return BLOGCHK_INVALIDFEED;
$ns = $this->doc->documentElement->lookupNamespaceURI( NULL );
$prefix = '';
if ( $ns )
{
if ( isset($this->defPrefix[$root->nodeName]) )
{
$prefix = $this->defPrefix[$root->nodeName];
$this->xpath->registerNamespace( $prefix, $ns );
$prefix .= ':';
}
}
if ( $slaves )
{
$valids = array();
foreach ( $slaves as $idBlog=>&$data )
{
if ( !$idBlog ) continue;
$ret = $this->retrieveFeedData( $root->nodeName, $prefix, $data['selector'] );
if ( !is_array($ret) )
{
$data['error'] = $ret;
continue;
}
$data = array_merge( $data, $ret );
$valids[$idBlog] = $idBlog;
}
} else
$ret = $this->retrieveFeedData( $root->nodeName, $prefix );
return ($slaves ? $valids : $ret);
}
最後に
このように、複数執筆者(ユーザー)共有Feedにより更新情報が配信されるブログであっても、
1個人専用Feedと同様に個々のユーザー毎の記事更新情報の取得が問題無く行えますので、
対象の人物に関するより詳細なブログ更新情報を発信する事が出来ます。
あとは、各ブログサイト運営者の方々には是非、複数人で執筆するブログでは、
実際に記事を書いた人物を特定する情報をFeedに設定して頂きたいと願うばかりとなります。;)
アメブロでの禁止タグチェックの誤検出とjavascriptスキーム
これは元々2009/10/24にAmebloに投稿した記事です。
禁止タグ
前回の記事をamebloにアップしようとしたところ、
何故か禁止タグが存在するというエラーメッセージが表示され投稿出来ません。
以前書いたように、この記事はまずローカル環境のファイルに対する執筆/編集を行い、
最後にamebloの標準エディタのHTMLタグ表示フォームにコピペして投稿をしていますが、
当然禁止タグの存在は判っているので、それらを使っている訳は有りません。
が、万が一という事も有るのでもう一度確認してみましたが、やはり禁止タグは存在していません。
埒があかないので、どの部分に問題が有るのか確認する必要が有りますが、
禁止タグ云々のエラー表示は、IE6のJavaScriptエラーメッセージ並に不親切なので、
どの部分の文字列なのかは表示されていません。
# そもそもameblo上で長文を書くような物好きな人間の存在を考慮していないのではないかと。
そんな場合には、古典的な手法である文章の断片毎に確認してエラー候補を絞り込むという事を行いますが、
その単純作業により最後に残ったのが下記のようなリンク文字列、
<a href="http://jp2.php.net/manual/ja/class.domdocument.php" target="blgr">DOMDocument</a>
の中の、class.domdocument.phpでした。
http://document.example.com
どうやらdocument.phpやらdocument.example.comなど、document.の部分が誤反応する模様です。
要するにdocument.writeやdocument.cookieなどの文字列への対応を想定していると思われます。
リンクURIには、<a href="javascript:alert('foobar')">foobar</a>とJavaScriptなども書けてしまうので、
hrefで指定される文字列をチェックするのは当然ですから、
これは単にそのチェック処理の副作用(誤検出)だと受け取り、
これ以上特に深く追求する気も起きませんので、とりあえず対応を考えます。
本文中に記述されたユーザー定義のJavaScript
とはいえ特に考える事も無く、dをdに換え試してみるとあっさり通りますので、
これにて解決とする事とします・・・
と言いたい所ですが、これがチェックをすり抜けるという事は、
XSSの脆弱性にも繋がる恐れのあるJavaScriptの実行が可能になる事も十分疑われますので、
その点を確認してみますと、残念ながら懸念通りの展開の様子です。
# そもそも自分自身で管理するブログの記事でXSSと言えるか、という話にもなりますが。
文字参照 - Character Reference
HTMLやXMLなどでは、タグの無効化として<>をそれぞれ<>に変換する処理や、
"(ダブルクォート)の"や'(シングルクオート)の'への変換などが行われますが、
この&英文字;や&#数値;のような形式の文字列と、実際に表示される文字や記号の対応を文字参照と呼びます。
# と言ってもcharacter referenceの日本語訳が"文字参照"になっているらしいというのは今回初めて知りましたが。
この文字参照では、上記のようなHTML中で意味を持つ記号を無効化するような変換や、
©(©)などの特殊記号の表示に使われる事は広く知られていますが、
それ以外にもBlog(Blog)や、ブロガラ(ブロガラ)のように、
通常の文字を表現する事も出来ます。
URI文字列内での文字参照
今回は、その文字参照への対応が不十分だった事による問題となります。
より正確に言うならば、アンカータグ<a>のhref属性や<img>などのsrc属性により指定されるURIの
ブラウザ側での扱いの特性を考慮していなかった事が原因と思われます。
意味のある記号を表示上の形体としての記号にするのが文字参照とも言え、
代表的な<>の<>化のように、HTML中では単なる文字として扱われ、
また、<script>を<script>とタグ名を文字参照で記述した場合も無効なタグとして扱われるだけとなります。
が、アンカータグのhref属性などのURI指定に使われる場合には違ってきます。
例えばHTML中で意味を持つ特殊記号である&を記述したい場合には、&では無く&と記述する必要が有り、
それはURI指定でも例外ではありません。
一方、Webサーバー/サーバー側スクリプトでは、
queryでの個々の値の組み合わせの区切り文字に&を利用する事が事実上の標準となっており、
# W3Cでは"&"の替わりに";"を使うべきだと推奨していますが。
Webブラウザは言わばその間を取り持つように、
HTML中のURI指定では&と記述された文字参照を本来の&1文字に戻してから、
サーバー側へリクエストを送ります。
javascriptスキーム
これがhttpスキームが指定されるURIならそれほど問題無いのですが、
2009年現在の多くのPCブラウザでは、
アンカータグのhref属性で指定されるURIとしてjavascriptスキームも利用出来ます。
amebloでもURI中の任意の場所にあるdocument.が禁止タグ扱いされるくらいですから、
当然javascriptスキーム指定も禁止タグ扱いとなり投稿は出来ません。
が、例えばsを文字参照として記述したjavascriptならチェックをすり抜けて投稿出来てしまい、
クライアント側のWebブラウザのURIでの文字参照の扱いにより、
javascriptがjavascriptスキームの指定と復元され、
そのjavascriptスキームが指定されたリンクをクリックする事でJavaScriptが実行されてしまいます。
さらにsrc属性のURI指定でもjavascriptスキームが有効になっているブラウザもありますので、
そのようなブラウザ上では、
ページを表示しただけでimgタグに記載されたURIのJavaScriptが実行されてしまう恐れも有ります。
<img src="javascript:alert( 'Oops!' );" />
今回の記事のそもそもの発端である禁止タグチェックの誤検出への対処法にも書いたように、
document.も文字参照を使う事によりチェックを回避出来ますので、
document.writeやdocument.cookieなどへのアクセスも可能となってしまいます。
ユーザー定義CSS
アンカータグにjavascriptスキームを利用した悪意あるスクリプトが埋め込まれている状態では、
それをクリックしなければ良いだけですが、
amebloではかなり自由度のあるユーザー定義のCSSが利用出来ますので、
悪意あるアンカータグをClickjacking(UI redressing)的に他のエレメントの上に密かに設置する事や、
position:fixedでbackground:transparentな全画面に表示されるブロック要素として配置する事も可能になりますので、
クリックされてしまう危険性も高くなります。
とりあえずの結論
amebloの内部仕様については当然判りませんが、
今回のような問題への簡易な対応としては、
チェック処理を(数値)文字参照から本来の文字に戻した文字列に対して行うようにすれば、
それほど手間が掛からず修正可能なのではないかと思われます。
ちなみにBlogaraでは、数値文字参照だけを文字に戻す処理は下記のような実装となっています。
// PHP(文字コードはUTF-8)で数値文字参照だけを本来の文字に戻す処理。 // より正確な処理を行うなら、10進数指定か16進数指定かで分ける必要有り。 // ブラウザによっては、文字列中に記述される文字参照の最後が;(セミコロン)で終らなくても、 // 改行やタグのように明らかな境界では無く、無効な文字参照指定文字が出現するまでを // 文字参照として解釈するので注意。(dzをdzと判断するなど)。 // # 一方PHPのhtml_entity_decodeやmb_convert_encodingでは、 // # セミコロンで終らない文字参照は文字に復元しないので注意。 preg_replace('/(&#x?[0-9a-f]+);?/uei', 'html_entity_decode("$1;",ENT_QUOTES,"UTF-8")', $str );
このように長々と書きましたが、
リンク文字列中の文字参照が本来の文字/記号に戻されてからURIとして評価されるという事は知ってはいましたが、
これがjavascript:のようなスキーム指定にも適用されJavaScriptが実行されてしまうという
XSSに繋がる危険性のあるものだとは自分も正直この時点まで認識していなかったので、
これからは十分注意すべきだと痛感した今回の一件でした。
また、現在のamebloでは、ブログ本文に記述されるユーザー定義のJavaScriptが許可されていないので、
この文字参照を使った抜け道は不具合なのではないかと考え、
運営に報告すると共に、修正対応が行われるまではこの記事の公開を行わない事にします。
追記1 (2009/11/05)
その後文字参照 XSSあたりでググってみると、
どうやら文字参照とjavascriptスキームの問題は既に何年も前から周知の脆弱性の原因の模様です。
しかし、今回の問題は修正が容易であると思われるにも拘わらず、
運営側からの返答も無く、一向に修正される気配も有りませんので、
IPAにXSSの脆弱性に繋がる任意のJavaScriptが実行される不具合が存在するという報告を行いました。
が、アクセス解析としてGoogleAnalyticsが使えるか否かを調べている過程で、
サイドバーのフリープラグインでは、文字参照を使わずともあっさり任意のJavaScriptが記述出来るというオチが判り、
ameblo的にも任意のJavaScript実行は容認状態である模様で何やら肩透かしを食らった感じですが、
とりあえずブログ本文中でのJavaScript記述という規定外の動作となるので、
運営/IPAどちらかからの経過報告を待つ事にします。
追記2 (2009/12/23)
11/26にameblo運営よりメールがあり、
との事ですが、確認してみましたが修正はまだ行われていません。
さらにその後12/22にIPAより、
ウェブサイト運営者側での修正が行われたという内容のメールを頂きましたので確認してみました。
javascript:のように文字参照を使ったjavascriptスキーム指定は、
禁止タグチェックに引っ掛かり投稿出来ないように確かに修正されています。
が、
上記Blogaraでの数値文字参照の復元コードのコメントに書いた、
ブラウザによっては、文字列中に記述される文字参照の最後が;(セミコロン)で終らなくても、
改行やタグのように明らかな境界以外にも、無効な文字参照指定文字が出現するまでを
文字参照として解釈するので注意。(dzをdzと判断するなど)。
のようなブラウザ側での特殊な動作が考慮されていないようで、
javascript:と記述した場合には、amebloでの禁止タグチェックをすり抜けて投稿出来、
ブラウザ側でjavascriptスキーム指定に復元されJavaScriptが実行されてしまいます。アメーバブログでサーバー側のプログラム言語に何を使っているのかは不明ですが、
PHPで文字参照の復元に利用されるhtml_entity_decodeやmb_convert_encodingでは
ブラウザでの特殊動作とは異なり、
セミコロンで終らない文字参照は文字に復元しませんので、
そのような事も関連しているのではないかと思われます。
という訳で、依然不都合があるという事をIPAにメールで返信し、
記事の公開はまだ行わない事にします。
# ちなみにdocument.の禁止タグ誤検出も修正されていませんでした ;(
追記3 (2010/01/30)
前回よりさらに1ヶ月以上経過した01/29に、 再びIPAよりウェブサイト運営者側での修正が行われたという内容のメールを頂きました。
こちらで確認してみたところ、今回は文字参照関係の修正がキチンと行われているようです。
が、そもそもの発端であるURI中のdocument.の禁止タグ扱いの語検出は残ったままで、
document.を含むリンクが記述出来ないという妙な仕様のブログとなっています。
しかし、ソフトウェア関係の技術者のブログ執筆者が皆無なamebloとはいえ、
日本最大規模とも言えるブログサイトにおいて、このような問題が放置されていたという事実は、
それぞれのシステムにおけるURIと文字参照の処理について見直してみる良い機会かもしれません。
と、ありがちな締めコメントを吐いてみましたが、
自分自身もdocument.の誤検出が無ければ全く気付かず、
特に調べてみようとも思っていなかったのは事実ですので、あまり偉そうな事も言えません。/grin
参考資料
W3C: Character references
W3C: Character entity references in HTML 4
W3C: Ampersands in URI attribute values
Wikipedia: 文字参照
JVN: 脆弱性情報対策データベース クロスサイトスクリプティング
distraid.co.jp: 半角全角変換ページの文字コード関連ツール - 特定の文字を数値文字参照で記述する時に利用
distraid.co.jp: Firefoxのプラグイン NoScriptの説明とXSSついて - 既に約2年前に書いたネタなので正直古い
複数執筆者による共有Feedの解析と更新管理 Part1
これは2009/10/21にAmebloに投稿した記事です。
XPath 教程
w3schools: XPath
1つのFeedで複数ユーザーのブログやコラムを配信するサイト
このameblo(アメブロ)もそうですが、一般的なブログでは、
個々人のブログ更新情報を配信するWebFeed(フィード RSS/Atomなど)はそれぞれの1個人専用のものとなります。
一方、複数の人物のブログや複数のライターのコラムなどを1ページ(1コーナー)として纏め、
そのページ全体で1つのFeedを配信するような形態のWebサイトもそれなりの頻度で見掛ける事が出来ます。
そのような複数ユーザー共有Feedのブログの場合には、Feedで配信された更新記事は一体誰が書いたのか、
あるいはその更新情報の扱いをどうするか、
というように1ブログ=1Feedの関係とはまた違った管理を行う必要が有ります。
そこでこのような案件は、
他のサイトが発信するデータの取得とサーバー側スクリプトでのデータ解析と処理、
そのデータのDBでの管理方法というように、多数の要素が絡むいかにもWebアプリケーションらしいネタという訳で、
ブログ情報サイトBlogara:ブロガラでは、
そのような構成のFeedの取得と管理をどのように行うようになったかという過程と共に解説します。
指針
- 環境は、PHP5.2.x, MySQL5.1.x
- WebFeedは、Pull型として各Feed配信サーバーに定期的に問い合わせ取得する
- 各ブログテーブルはレスポンスヘッダで返されるlastModifiedとETagを保持するカラムを持ち、それをリクエストヘッダで送る事で不必要なFeedデータの解析を行わない
- ユーザーは複数のブログを所持し、各ブログは1つの更新情報(タイトル/本文/更新日)レコードを所有する
- 複数ユーザー共有Feedのブログでも、各ブログは独立したレコードとそれぞれの更新情報レコードを所有する
- 共有Feedブログでは、各更新処理中に1度だけ共有Feedのリクエストを送り、その1つのFeedデータから共有する全てのユーザーの更新情報を取得する
複数人が執筆するWebFeedの取得とデータ解析
今更書くまでも無い、他のサイトが配信するFeedを取得する方法
情報配信に利用されるFeed(大抵の場合RSS/AtomのようなXML形式)は、
HTTP経由で配信元サイトから取得出来ますので、各言語のライブラリを利用して簡単に行う事が可能です。
# ただ、XMLデータを返すのにも拘わらず、レスポンスヘッダのContent-Typeがtext/htmlだったりする変態サイトや、
# HTTP1.1のTransfer-Encoding: chunkedの扱いに微妙にクセが有るWebサーバーが存在しますので注意が必要です。
# chunkedに関してはまた別の機会にこのブログのネタとして取り上げる予定。
更新記事は"誰が"書いたのか
Feedで配信される更新情報では、通常新しい日付の記事から並ぶという時系列順となっています。
Blogaraでは、個々人のブログの最新更新1件分だけの情報を保持していますので、
個人専用のFeedならば、単純に最初に記述される最新(日付の)記事だけを取得すれば良いのですが、
複数人による共有Feedでは、それぞれの執筆者についての最新記事を抽出する必要が有ります。
幸い、現在Blogaraで対応しているRSS1.0/RSS2.0/Atom1.0のいずれのFeedにおいても、
執筆者を指定する用途に利用出来るエレメントが規定されていますので、
それらのエレメントを使って個々の記事において執筆者を特定しているならば、
大抵の場合、複数ユーザー共有Feedとして利用出来ます。
RSS1.0ではDublin Coreモジュール(NameSpace:dc)のdc:creatorエレメント、
RSS2.0ではauthorやcategory、Atom1.0ではauthorなどが、
複数ユーザー共有Feedでの個々の執筆者指定に使われる事が多くなります。
一例を挙げると、テーマ: アイドリング!!!に登録されているアイドリング!!!ブログ「煮詰まります!!!」では、
それぞれのメンバーのブログ記事を1つのFeed(RSS1.0)に纏めて配信しています。
そしてそのFeedでは、個々の記事更新データ(item)に
<dc:creator>14号:酒井瞳</dc:creator>のようなサブエレメントを追加する事で、執筆者の指定を行っています。
あるいは、テーマ: NFLのNFL Japanの公式サイトに連載されているNFL JAPAN コラムのFeed(RSS2.0)では、
個々のitem内の<category>近藤 祐司</category>によって執筆者が指定されています。
PHPでのFeed(XML)からの更新情報データ抽出
複数ユーザー共有Feedにおいても、個々のユーザーそれぞれの更新情報を識別出来る事は判りましたので、
次はPHPで実際にどのようにFeedから更新情報を抽出するかになりますが、
Blogaraで扱う3種類のFeedは全てXMLですので、FeedからのというよりもXMLからのデータ抽出操作となります。
正直、この時点までPHPでXMLデータ操作を行った事が無かったので、
複数あるXML操作クラス/関数のどれを使うか考えましたが、
HTMLとXMLに対応し、JavaScriptでも馴染みのあるDOM操作が可能という事で、
PHP5のDOMDocumentを利用してみる事にします。
各Feedでは、個々の更新情報が特定のエレメント(RSS1.0/2.0はitem、Atom1.0はentry)として列挙され、
個々の記事のタイトル/内容/更新日などの情報はそのエレメントの子エレメントとして記載されています。
DOMDocumentクラスには、
ノード名を指定して出現順にエレメントを取得出来るgetElementsByTagNameメソッドがありますので、
それを利用する事で簡単に更新情報リストを取得出来、
1ユーザー専用Feedの場合には、そのリストの先頭のエレメントが最新の更新記事1件の内容となります。
と、このように専用Feedでは特に何も考えずこれで問題無いのですが、
共有Feedの場合はそれほど単純な話では有りません。
共有Feedでの執筆者指定は、上記で説明したようにそれぞれのFeedで異なり、
さらにそれらは単に推奨されているだけなので、
イレギュラーなFeedを配信するサイトが存在する事も十分考えられます。
共有Feedでの個々の執筆者の更新情報取得処理としては、
まずitem/entry下の何のノードの何と言う文字列で指定されているのかという事をブログの登録時に記述し、
getElementsByTagNameで取得した更新記事リストの内容を漁り、
執筆者特定設定に一致する最初のitem/entryから記事内容を取得する、というようなものになるだろうと考えました。
が、これでは専用Feedの処理とは別の処理となり、
さらに執筆者特定設定の記述が独自仕様の特殊なものになると思われますので、あまり芳しく有りません。
そこで、専用/共有Feedデータ抽出を可能な限り共通処理にする事と、
ブログ設定での執筆者特定記述には何か標準的な文法に従った文字列にするという事を考え、
(遊びで;)Greasemonkeyのスクリプトを書いていた時に多少かじったXPathを使ってみる事にします。
DOMXPath
XPathとは何なのか、あるいはどのように記述するのかはネット上のドキュメントをご覧下さい。
W3Cのドキュメントや
こことかここなどが参考になると思われます。
PHPでのXPathとなると、SimpleXMLの利用も考えられますが、
今回はDOMDocumentクラスと共に使うDOMXPathクラスを選択します。
ちなみにDOMXPathについてもPHPのマニュアルを見てもらった方が話が早いですが、
DOMXPathの場合にはマニュアルだけではなく、付記されているユーザコメントを読む事を強くお勧めします。
大抵のFeedXMLには、xmlns="http://purl.org/rss/1.0/" やら xmlns="http://www.w3.org/2005/Atom" などの
defaultのnameSpace(名前空間)が設定されていると思われるので、
その場合には"必ず" DOMXPathのregisterNamespaceでprefixとdefaultのnameSpaceを登録するようにして下さい。
XPathの利用により、専用/共有のどちらのFeedにおいても、
いちいちgetElementsByTagNameでエレメントを取得してから云々という処理は必要無く、
XPathのquery一発で最新更新記事の内容を保持したエレメント群を取得する事が可能になります。
// 専用Feed(Atom)の場合には、 $nodeList = $xpath->query( "//atom:item[1]/*" )
// 一方、共有Feedのアイドリング!!!煮詰まりますでは、 $nodeList = $xpath->query( "//rss1:item[dc:creator='14号:酒井瞳'][1]/*" ) // また、共有FeedのNFL Japanのコラムでは、 $nodeList = $xpath->query( "//item[category='近藤 祐司'][1]/*" );
というように、XPath式が異なるだけで専用/共有Feedの区別無く非常に簡潔な処理となり、
また、共有Feedでの執筆者特定記述もXPath式となりますので、判りやすい?/テストし易いものとなっています。
Part2に続く
ここまでで、共有Feedからの個別執筆者毎の最新更新記事抽出処理は完了しましたので、
次は、Feedを共有する複数ブログの管理などを行います。
参考資料
W3C: XML Path Language (XPath)XPath 教程
w3schools: XPath