cloudfoundry + sinatra + sequel + mysqlメモ(1)
先週から、cloudfoundry + sinatra + sequel + mysqlで簡単なアプリケーションを動かしていて、基本的にはすんなり行けたんだけど、何点か詰まった個所のメモ。
Rubyのバージョン指定方法
vmc pushでデプロイするとき、勝手にJavaなのかRubyなのか、RoRなのかsinatraなのか、等を判別してくれるけれど、rubyのランタイムは指定しないと自動で1.8になるよう。1.9を使いたい場合は、"vmc push --runtime ruby19"。
gemの取り扱い
ほとんどのgemはrequireに書くだけで動いたけど、一部(というか一部以外?)bundlerでgemを同梱しないと動かなかった。bundlerを全然知らないので正直良く理解できてないけど、この辺とか参考。
https://github.com/cloudfoundry/vcap/issues/54
(*)sinatra, haml, sequelは確かbundlerなしで大丈夫、mysqlが駄目だったかな
起動しない場合/起動中のログ確認
vmc logs applicationname
mysqlの接続文字列
MySQLを利用する前、vmcコマンドでサービス作成、アプリケーションとバインドしたあと、sequelの場合は自分で接続情報を設定しないといけない。RoRだと勝手にyamlをなんかしてくれて繋がる、ような記述も見かけたけどRoRを知らないし、試してません。
http://support.cloudfoundry.com/entries/505124-sample-app-to-mysql-connection
接続情報は環境変数にJSONで入っているので、パースして利用するのが正しいようだけど、面倒だったら環境変数をsinatraでブラウザに出力させて、そこからサーバー名、ポート、ユーザー、パスワード、データベース名をコピペでハードコーディングしてもとりあえず動く。
Scalaでダイジェストを生成する
インターネットから取得した画像をキャッシュとしてファイルで保存しておきたいなー、と思いました。キャッシュなのでURLからファイル名が特定できなければいけない。最初はURLのString#hashCodeを使えばいいのかな、と思ったのですが、hashCodeは衝突する可能性があるらしい。そうかー、どんなアルゴリズムであれ衝突する可能性はあるよなー、と思ってMap[String, String]にURLとファイル名の対応を保持しておき、プログラム終了時にxmlで保存するようにしてたのですが。
ちょうどその頃、たまたま「入門Git」を読んでいて、 その中に、Gitではオブジェクトを管理するのに、SHA-1ハッシュ値を利用しているとの記述がありました。どうもこれを利用すればいいらしいなーという気がします。
なにしろ、SHA-1ハッシュ値が重複してしまう可能性というのはとてつもなく低いのです。「Pro Git」から引用すると、
しかし、そんなことはまず起こりえないということを知っておくべきでしょう。SHA-1 ダイジェストの大きさは 20 バイト (160 ビット) です。ランダムなハッシュ値がつけられた中で、たった一つの衝突が 50% の確率で発生するために必要なオブジェクトの数は約 2^80 となります (衝突の可能性の計算式は p = (n(n-1)/2) * (1/2^160) です)。2^80 は、ほぼ 1.2 x 10^24 、つまり一兆二千億のそのまた一兆倍です。これは、地球上にあるすべての砂粒の数の千二百倍にあたります。
http://progit.org/book/ja/ch6-1.html/
で、Scalaで、というかJavaでSHA-1ハッシュ関数を利用してダイジェストを生成するのはとても簡単、@IT:Java TIPS -- Javaでダイジェストを生成するにサンプルのコードが記載されていました。
これを元に、ScalaでStringからSHA-1で生成したダイジェストの文字列を返すクラスは以下のように定義できました。
import java.security.MessageDigest class Sha1Digest(str: String) { val digestString: String = { val md = MessageDigest.getInstance("SHA-1") md.update(str.getBytes) md.digest.foldLeft("") { (s, b) => s + "%02x".format(if(b < 0) b + 256 else b) } } }
ダイジェストを取得する際、Stringのメソッドであるかのように使いたいので、implicitすると、以下のようになります。
object App { def main(args: Array[String]) = List("全部", "違う", "値になります").foreach { str => println(str.digestString) } implicit def String2Sha1Digest(s: String): Sha1Digest = new Sha1Digest(s) }
自分のプロジェクトでは、MyPreDefのようなObjectを定義してimplicitを並べてimportしており、その中に紛れ込ませて使っています。
型付データセットをインターフェース越しに扱う
型付データセットが大好きなので出来る限り型付データセットだけでいろいろなことを済ませたい。
済ませたいんですが、Partialクラスにメソッド追加して便利にしていくだけだと余分なところが隠せないのでインターフェース越しに扱うのはどうなのかなー、という話を書きます。
もっと簡単に同じような動きを実現できるのではないのかなーと思いつつ出来てない……。なんか、メジャーなやり方があるんでしょうか……。
たとえば、こういうテーブルがあったとして、

CHAR(1)である、sex列には0:男性、1:女性というフラグが入るとします。それ以外の値は入れてほしくないので、SEXという列挙体を定義して、その列挙体でsexカラムを扱えるようにします。なんか紛らわしいですが、SEXが列挙体の型名で、sexが自動生成されたDataRowのカラム、SexがPartialクラスに定義したプロパティです。ちなみに、sexというのは英語で性別という意味です。
ついでに、姓 + 名を返してくれる、読み取り専用のFullNameというプロパティも定義しています。

これで、以下のように、Sexには特定の値しか設定できないようになりました。

しかし、自動生成されたsexプロパティのほうにも依然としてアクセスできるので、こいつに直接値を設定することで、"0"、"1"以外の好きな値、"x"などを入れられます。そして、次回Sexプロパティにアクセスしたとき、Enum.Parseが出来なくて死ぬ……(死にません。例外が出る)。
sexに直接値が入れられる以外にも、CustomerRowにはDataRowから継承した、データアクセス層以外からは触るべきでないようなものがいっぱい公開されてて、そいつらには触れないようにしたい。

↑なんかよくわかないのが一杯出るけど全然いらない。そこで、公開したいメンバだけ設定したインターフェースを定義して、こいつ越しに扱うルールにしてみます。名前は、ICustomerDataRowです。普段は名前にIとかつけませんが考えるのが面倒だったので……。

こんな感じで、使いたい奴だけ出てくるようになりました。

しかし、このままだと、CustomerDataTableからインデクサや、Select、foreachで取り出した時に毎回CustomerRowではなく、ICustomerRowとして扱うのを忘れないようにしないといけないので、最初からICustomerRowで返してくれる、ICustomerDataTableというのも定義してみる。

CustomerDataTableは使わせないで、ICustomerDataTableだけでまわそうとすると、最低限NewRow系やらも使えるようにしておかねばならず面倒くさい……。あと、型付データテーブルのインターフェースが必要なのと同じ理由で、型付データセットに対応するインターフェースも定義した方が良い、とかいうことになる……。
まぁ、面倒だけど定型的な作業は自動化するか、新人にやらせろ、という格言もあるので行けるのかなぁー。データアクセス層だけアセンブリ分けるときは、DataSet自体はinternalにしてinterfaceだけパブリック、とかにすることもあるんでしょうか。知りませんが……。
なぜwinver.exeの画像は汚いのか?
日記のタイトルが疑問文だと答えがあるのかと思ってしまうかもしれませんが、単に純粋な疑問で、なんでこんな画像になっているのか全然わからない……。winver.exeというのはWindowsのエクスプローラー、ヘルプ -> バージョン情報、で出てくるこんなウィンドウです。ためしに、Windowsキー + R、"winver"、Enterキー、で起動してみてください。僕の手元で集められたものを列挙してみます。
# ライセンス情報を消してます
Windows XP SP3。滲みすぎ……。

Windows Server 2003。サーバだし普段目にしないから適当に作ったのかも。

Windows Vista。XPまでは、たまたまやる気がなかったのかな、と思ってましたが、Vistaも汚いのでなにか特別なこだわりがあるのかもしれない、という疑いも拭いきれない感じになってきました。

IE6での検証用に配布されてたWindows XPのイメージ。Virtual PC上。これはきれい。

最後の奴だけきれいですが、英語版だときれいなのでしょうか。Windows 7のはきれいだという話も聞きましたが、日本語版の話なのでしょうか。
開発現場でPowerShellを使う
4/2にTech Fieldersセミナー「スクリプトを使用した Windows Server 管理の自動化」でライトニングトーク(五分貰って好きなこと喋る)をしてきたので、しゃべった(つもりの)内容を置いておきます。あまり緊張しないほうだと思ってたんだけど、やっぱ緊張するなー。一応書きたいことを羅列したものは作っておいたんだけど、きっちり五分でしゃべる内容決めといたほうがいいんだろうな。あたりまえだけど……。ちなみに、ライトニングトークでは最後に投票をして、一番票を集めた人がマイクロソフトのプレゼン用マウスをもらえるんですが、貰えなかったので次出ることがあったらもっと改善して票を集めるのを目標に挑みたい……。
ということで、PowerShellを開発現場で使って、簡単・便利なツールを作る方法についての自分なりのコツを紹介したいと思います。

この図は最近まで開発してたシステムです。.NET Frameworkとしては、標準的な構成かな、と思います。DBがあって、Webサービス経由が、あって、UIとして、ASP.NETか、Windowsフォームのアプリケーションがあります。
PowerShellではテスト用のツールなどを作っていたんですが、今日紹介するのは、図の1.と2.の部分です。
まず、1.のツールなんですが、これは特定の条件でDBからデータを取得し、ファイルに落とし込みます。そして、任意のタイミングでDBに書き戻します。これはどういう用途に使うかというと、
- テストをしてデータが書き換わったときに元に戻したい
- 本番環境からテスト環境にデータを持ってきたい
なんて時に使います。
もう一つの下側、2.ですが、これは、ログからリクエストを拾ってきて、Webサービスのリクエストを再現するのに使います。リクエストはシリアライズしてログに記録してるので
とかって使い方になります。
どちらも、データやリクエストはシリアライズしてXMLでファイルにしているので、データを一部エディタで書き換えたり、コピーして微妙に違うものを作るなんてことが出来ます。

具体的な作り方を説明します。この二つのツールは非常に似通ったつくりになってるので、そのつくりを図にしてみました。
Webサービスへのリクエストを行ったり、DBデータの取得、反映などの、肝になる動作はほとんどほとんどVisual Studioが自動生成するソースでできてしまいます。
Webサービスで言うと、WSDLを参照してプロキシクラスを作ってくれるんですが、そいつにデシリアライズしたオブジェクトを渡すだけです。DBだったら、型付DataSetとテーブルアダプタです。
ただ、そのままだとPowerShellから扱いにくいので、使いやすいレベルで動作をまとめて、C#なり、VB.NETなりで、スタティックメソッドにまとめてしまいます。スタティックメソッドにするのはPowerShellから呼び出しやすいからです。
スタティックメソッドに渡す引数は、基本的にXMLシリアライズしてファイルに落とし込んだオブジェクトをデシリアライズして使います。XMLなのでDBに反映したい中身や、Webサービスに渡したいリクエストの中身をエディタで編集もできて便利です。
スタティックメソッドは呼び出しが楽とはいっても、さすがにそのまま使うのはなんなので、PowerShellのfunctionでラップします。実際にツールとして使うときは、この関数を呼び出して使う形になります。
基本的に、上で紹介したようなツールはほとんど自動生成されるソースを、C#でちょこちょこっとラップしてあげるだけで出来てしまいます。簡単・便利なのでぜひご利用ください……。
ちなみに、自作のアセンブリ、DLLでもEXEでもかまいませんが、を読み込んでPowerShellから利用するには、
[System.Reflection.Assembly]::LoadFile({ファイル名})
$s = 'System.Xml.Serialization.XmlSerializer' $f = 'System.IO.FileStream' $slzr = New-Object $c -A @({クラス名}) $fs = New-Object $f -A @({ファイル名}, 'Create') try { $slzr.Serialize($fs, {シリアライズ対象}) } finally { $fs.Close() }
デシリアライズは
$fs = New-Object $f -A @({ファイル名}, 'Open')
try { $o = $slzr.Deserialize($fs) } finally { $fs.Close() }
でできます。多分……
Nullオブジェクトパターン……
オブジェクトの深いところの値を例外出す可能性無しにとってきたいで、ラムダ式使ってメンバがNULLでも例外出さずに画面へ出力できるような仕組みについて書いたんですが、「ドメイン駆動」に、そのまんまなケースが紹介されてました。推奨されてる解決方法は"Null オブジェクト"を使う、というもので、P122から引用すると
NULL オブジェクトパターンとは、nullを使う代わりに空インスタンス(空とはメンバの値がすべてデフォルト値だということを意味する。たとえば、 stringメンバの値はstring.Emptyになっている)を使うということだ。こうすれば、次のようなコードの"ドットをたどる"ことが確実にできる。
なるほどー、ということで、ビューモデルなんかはこれを利用して設計するのがよさそうですね、なのかなーと思いますが、"NULLオブジェクトパターン"で検索するとちょっとニュアンスの違う記述が見つかります。
でも、このNullPrintStreamのような 「同じインタフェース(API)を持ちながら、何も処理しないクラス」 を使えば、 条件判断が不要になり、利用する側をシンプルにすることができます。
出力の有無をコントロールするには、 Applicationに渡すOutputStreamを変えます。 つまり、Applicationのソースコードの修正を行わずに、 出力の有無を制御できることになります。
このような、 何も処理を行わないクラスを利用したデザインパターンを、Null Object(ナル・オブジェクト)パターンと呼びます。
"何も処理を行わない"と、"メンバの値がすべてデフォルト値"だとだいぶ意味が違うので、これはどういうことなのかなー、と思いますが、どちらも、もともとは96年に書かれたWoolfさん?の「The Null Object Pattern(Postscriptをgzしたファイルです)」という論文が出典みたいです。
英語だしSmalltalkだしでよくわかりませんでしたが、例として出されているのは上のケースとは逆というか、MVCパターンで、入力がない、読み取り専用のViewは Controllerをもつ必要ないのでControllerにNullオブジェクトを使うという感じなのかな、と思いました。そのほかの部分は結城さんの説明が近い気がします。冒頭で引用した部分は、この文脈でNullオブジェクトパターン使うといったら、空のインスタンス使うってことやで、くらいの感じなのか。
ちなみに、「エンタープライズ アプリケーションアーキテクチャパターン」にもNullオブジェクトはでてくるのですが、こちらでは"スペシャルケース"という「特定のケースで特別な振る舞いを提供するサブクラス」の一例として紹介されてます。こちらの例は「ドメイン駆動」のものに近いです。「ドメイン駆動」では実装方法まで触れていないというか、"空インスタンス"を使うと言ってるので同じクラスでメンバだけ空に設定されたインスタンス、のようにも読めるような気がしますけど、パターンと言ってる時点でそういうクラスを利用するにきまってるやろ!! ということなのだろうか……。
Entity FrameworkでDBのデータをファイルに取得したり書き戻したりしたい
テストのためにデータを同じ状態に戻したい、とか、一部の本番環境データをステージング環境に持っていきたい、というときに、いままでは、DataSetに取得 → ファイルにシリアライズ → 移行先の、キーが重複するデータを削除 → デシリアライズしたオブジェクトをDBに投入、ということをやっていたのですが、同じことをEntity Frameworkでやるにはどうすればいいのか実験しました。
テストに使ったDB、ではなく、エンティティはこういうかんじ。生成に使ったのは、たまたま手元にあったDBです。
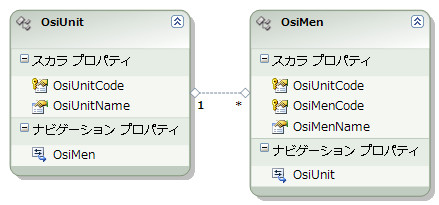
テーブルとエンティティは単純に1:1でマッピングしてます。外部キーが設定してあると勝手にアソシエーションをたどるプロパティを作って、相互に参照できるようにしてくれます。
とりあえず、Entityを表示したりしてみる
一件のOsiUnitをDBから取得、それに紐付くOsimenを取得し、コンソールに表示してみます。
using (hpmaEntities e = new hpmaEntities()) { OsiUnit unit = e.OsiUnit.Where(u => u.OsiUnitCode == 9).First(); Console.WriteLine("UNIT:" + unit.OsiUnitName); unit.OsiMen.Load(); foreach (OsiMen men in unit.OsiMen) Console.WriteLine(" Member:" + men.OsiMenName); }
実行結果。
UNIT:℃-ute Member:梅田えりか Member:矢島舞美 Member:村上愛 Member:中島早貴 Member:鈴木愛理 Member:岡井千聖 Member:萩原舞 Member:有原栞菜
hpmaEntitiesは自動で生成されるクラスで、System.Data.Objects.ObjectContextを継承してます。物理的には、DBへの接続なのかなーと思うので、hpmaContextとかって名前になってくれるほうがしっくりくるかなーと思いますが、まぁ自分で直せばいいだけです。
あと、意外だったのは、unit.OsiMen.Load();などと明示的に指定しないと、アソシエーションの先のデータは取ってきてくれないことです。
"隠されたネットワーク ラウンドトリップの排除" という原則に基づき、Entity Framework では自動遅延読み込みはサポートされません。コードで生成したクラスから構成されたグラフをトラバースするという単独の動作では、ストアのクエリがトリガされることはありません。したがって、使用するオブジェクトはユーザー コードで明示的に取り込む必要があります。
だそうです。Include というクエリビルダメソッドを使えば一括で読み込めるということも書いてありますが、クエリビルダメソッドがなんなのかわからない(このページではほかに一回も出てこない)ので今回は見送りました。
Entityをシリアライズする
Entityのシリアライズに関してはオブジェクトのシリアル化 (Entity Framework)に書いてあります。バイナリフォーマッターを使ったシリアライズに関しては、ほかに専用の解説ページ、オブジェクトをシリアル化およびシリアル化解除する方法 (Entity Framework)があったのですが、XMLで中を見てみたかったので、XMLシリアライズにしました。
public static string Serialize<T>(T value) { StringWriter sw = new StringWriter(); new XmlSerializer(typeof(T)).Serialize(sw, value); return sw.ToString(); } public static T Deserialize<T>(string value) { return (T)(new XmlSerializer(typeof(T))).Deserialize(new StringReader(value)); }
超適当ですが、これで文字列にできたので、あとはファイルに書き込みます。stringにシリアライズしているので、ファイルはutf-16で書く必要があります。最初の引数はファイル名。
// シリアライズするとき File.AppendAllText(UNIT_FILE, Serialize(unit), Encoding.GetEncoding("utf-16")); File.AppendAllText(MEN_FILE, Serialize(unit.OsiMen), Encoding.GetEncoding("utf-16"));
// デシリアライズするとき private static OsiUnit GetFromFile() { OsiUnit ou = Deserialize<OsiUnit>(File.ReadAllText(UNIT_FILE)); ou.OsiMen = Deserialize<EntityCollection<OsiMen>>(File.ReadAllText(MEN_FILE)); return ou; }
EntityをDBから削除
ファイルに出力したEntityを書き戻す前に、DBから削除しておく必要があります。デシリアライズしたオブジェクトとキーが重複してしまうからです。Entity SQLにはDML(Insert, Update, Delete)がありません、というのをみて、参照にしか使えねーのかよ!! とおもっていましたが、実際はContextに対して取得したEntityをつかって変更を行い、SaveChangesすれば、DBにたいして反映できます。オブジェクトの追加、変更、および削除 (Entity Framework)。こういう感じで、さっきシリアライズしたオブジェクトを削除できる。
using (hpmaEntities e = new hpmaEntities()) { OsiUnit unit = e.OsiUnit.Where(u => u.OsiUnitCode == 9).First(); unit.OsiMen.Load(); e.DeleteObject(unit); e.SaveChanges(); }
簡単。
デシリアライズしたEntityをContextに戻してDBに反映する
ここが難しかった、参照したのは、オブジェクトの使用 (Entity Framework タスク)から辿れるページ群です。
まず、XMLからオブジェクトに戻すところは簡単にできたのですが、これをContextに適用するのがうまくいかない。
アタッチされたオブジェクトがデータ ソースに存在しない場合、そのオブジェクトは SaveChanges の実行時に追加されません。この場合、プロパティに変更が加えられると、SaveChanges の実行時にサーバーで例外が発生します。オブジェクトを追加するには、Attach の代わりに AddObject を使用します。
これを読む限りでは、もうデータソースであるDBからは消してしまっているので、AddObjectを使わなければならないっぽい。しかし、AddObjectを使うとInvalidOperationExceptionが出て、詳細は、"オブジェクトには既に EntityKey があるため、ObjectStateManager に追加できません。既存のキーを持つオブジェクトをアタッチするには、ObjectContext.Attach を使用してください。"。EntityKeyは設定できるんですが、OsiUnitのEntityKeyをnullにしても例外が変わらないのでダメやー、と30分くらい悩んでたんですが、アソシエーションの先のオブジェクトも全部EntityKeyをnullにしてあげれば大丈夫でした。
というわけで、こういう感じでDBに書き戻せました。
using (hpmaEntities e = new hpmaEntities()) { OsiUnit d = GetFromFile(); d.EntityKey = null; foreach (OsiMen om in d.OsiMen) om.EntityKey = null; e.AddToOsiUnit(d); e.SaveChanges(); }