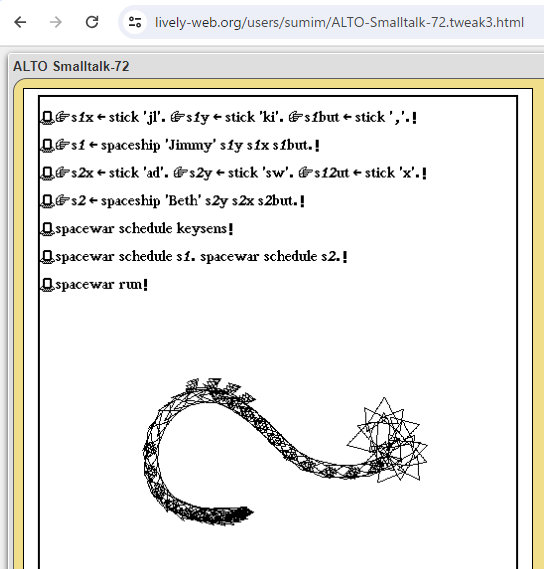
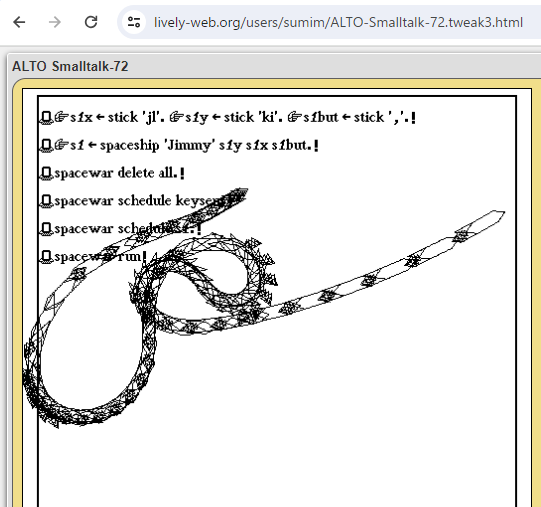
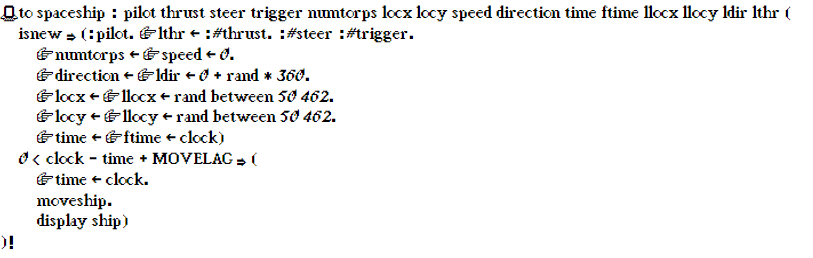アラン・ケイの“メッセージングによるプログラミング”という着想に基づき(非同期処理などいろいろ足りていないながらも──)比較的忠実に実装された1970年代の非常に古いSmalltalk-72に実際に触れてみるシリーズ 第2弾です(なお最新のSmalltalkについては Pharo などでお楽しみください!)。
今回は謎言語「Smalltalk-71」で書かれたスペースウォー・ゲームを Smalltalk-72に移植して動かすことを目指しました。なんとか完走できてよかったです。前回(2019年)を含む他の記事はこちらから→Smalltalk-72で遊ぶOOPの原点 | Advent Calendar 2023 - Qiita
ユーザー入力を受け付ける ask とゲームをスタートさせる start
いよいよ仕上げの start です。

まず、Smalltalk-71 では組み込みのプロシージャを想定しているであろう ask を Smalltalk-72 で用意します。
![]()
to ask (disp _ :. !read eval)
すみません。かなり手を抜きました ^^;
この ask はメッセージとして送られてきた続く文字列を表示して、ユーザー入力の結果 read を Smalltalk-72 の式として eval してから返します。
これを使って start を実装しましょう。

to start ss pilot sy sx sbut (
"SSIZE _ 6.
"MOVELAG _ "FRAMELAG _ 0.
"SPSCALE _ 1.0. "DIRSCALE _ 1.0. "LSCALE _ 1.0.
"CLOSE _ SSIZE * 3.
"TORPLIFE _ 2000.
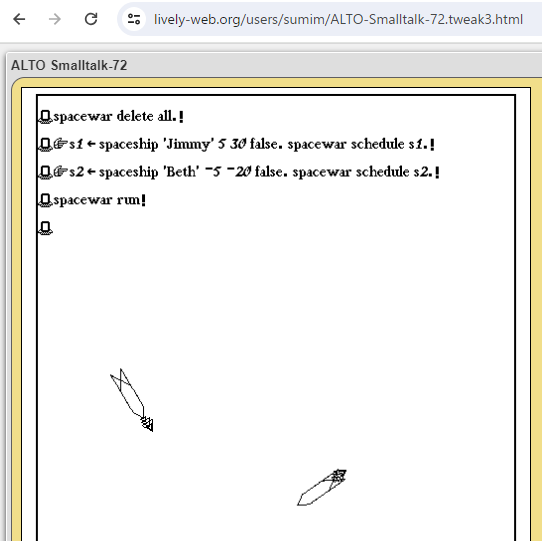
spacewar delete all.
spacewar schedule keysens.
stick delete all.
do ask 'how many will be playing~ ' (
"pilot _ ask 'pilot''s name str~ '.
"sy _ stick ask 'two chars (keys) str for stick y-axis~ '.
"sx _ stick ask 'tow chars (keys) str for stick x-axis~ '.
"sbut _ stick ask 'one char (key) str for stick button~ '.
"ss _ spaceship pilot sy sx sbut.
spacewar schedule ss)
disp _ 'type ''esc'' to exit...'.
spacewar run)
"disp _ dispframe 16 480 514 184 string 2000. disp clear
@ erase. disp display.
start
作業用に広げていたターミナルウインドウのサイズを元に戻して( disp ← ... )から、画面を綺麗にして( ☺ erase. disp display. ) start を実行します。
すると、プレイヤー数、プレイヤー名、推進力操作のキーのペア、操舵のキーのペア、魚雷発射キーをどうするかについて1プレイヤーずつ訊ねられるので、プレイヤー数については整数、それ以外は文字列リテラル( '...' )でタイプして do-it \(グリフは ! )することで入力できます。
全ての入力が終えると escキーで中止できる旨のメッセージを表示してゲームが始まります。

おわりに
当初の甘い計画では 18回くらいでサクッと終わらせて、残りは Smalltalk-72 らしい実装に試みにあてたかったのですが、ままならないものですね…^^;
ともあれ、なんとか start でゲームを開始するところまでこぎ着けられてよかったです。
おそらくオブジェクトのアクティベートのタイミングへの理解が足りていないのが主な理由でしょうが、“原因不明”のエラーとの格闘で無駄に時間を溶かしてしまいました。しかし、おかげでメッセージング のみ によるプログラミングを今まで以上に踏み込んで体験し身につけられたように思います。
一方で、クラスやオブジェクトがクロージャーで実現されていて、メッセージを受け取るために「アクティベート」と称する実行が必要になる Smalltalk-72 がその非効率さ以外にも抱えている構造的な問題点もなんとなくいろいろと見えてきたような気がします。
今後は、前述のとおり今回果たせなかった Smalltalk-72 ならでは版の他に、Squeak や Pharo といった現在の Smalltalk で実装したらどんなふうになるかも試してみたいと思っています。
また、オリジナルのスペースウォー・ゲームの仕様を探して、Smalltalk-71版のコードは何が違うのか、といったあたりも調べてみたいです。
Smalltalk-71 についてはますます謎が深まっただけで終わってしまったような残念な感じではありますが、それでも、なるほど「A Persona Computer for Children of All Ages(あらゆる年齢の『子供たち』のための パーソナルコンピュータ)」 でジミーとベスが遊んでいたのはまさにこのSmalltalk-71で書かれたスペースウォー・ゲームそのものであり、この論文(エッセイ?)にアラン・ケイ氏が掲載しようとしていたのもまさにこの Smalltalk-71版のコードだったのでは!?…という今更ながらの気付きを得ることができました。この予想が当たっているとしたら、読み解くのにかなり労力を費やした身としては、ダニエル・G ・ボブロー氏の助言はしごくまっとうなものだったと強く同意します^^;
あと非常に気になった点として、これはオリジナルの当ゲームの仕様がどうだったか次第で意見が分かれるところではありますが、このゲームでは向きの操舵が慣性に従っていないところがずっと引っかかりました。速度と同様に宇宙船の向きを制御するそれ用のスラスターを用意し、加速・減速を意識した姿勢制御がしたいところです。
グラフィック出力やキー入力などの IO を手軽に扱えることが前提ですが、新しく学ぶ言語や処理系を試すときにこのスペースウォー・ゲームはほどよい規模の題材として使えそうです。今後も大いに活用してゆこうと思います。
付録1:Smalltalk-71 のコードを極力修正したバージョン
Smalltalk-72 への移植を通じて、意味が通りにくい部分について恐らくこうなのではないかと修正を試みた Smalltalk-71版のコードです。
to ship :size
penup, left 180, forward 2 * :size, right 90
forward 1 * :size, right 90
pendown, forward 4 * :size, right 30, forward 2 * :size
right 120, forward 2 * :size
right 30, forward 4 * :size
right 30, forward 2 * :size
right 120, forward 2 * :size
left 150, forward :size * 2 * sqrt 3.
left 150, forward :size * 2
right 120, forward :size * 2
left 150, forward :size * 2 * sqrt 3
penup, left 90, forward :size, right 90, forward 2 * :size
end to
to flame :size
penup, left 180, forward 2 + sqrt 3, pendown
triangle :size, forward .5 * :size
triangle 1.5 * :size, forward 5 * :size
triangle 2 * :size, forward .5 * :size
triangle 1 * :size, forward .5 * :size
etc.
end to
to flash
etc.
end to
to retro
etc.
end to
to torp
etc.
end to
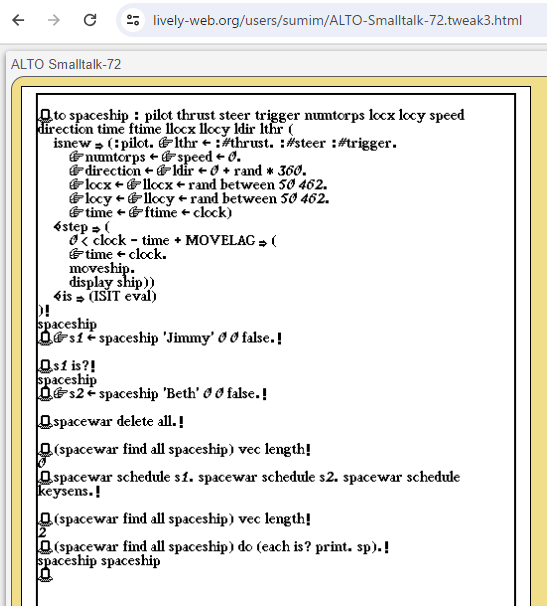
to spaceship :pilot :thrust :steer :trigger
use :numtorps :location:(:x :y) :speed :direction
repeat
moveship
if :trigger and :numtorps < 3
then create torpedo :speed :direction :location .
?crash :self
display ship
pause until clock = :time + :movelag
end to
to moveship
make :speed be :speed + (:spscale * :thrust)
make :direction be :direction + (:dirscale * :steer) rem 360
make :location:x be :location:x + (:lscale * :speed * cos :direction) rem 1024
make :location:y be :location:y + (:lscale * :speed * sin :direction) rem 1024
end to
to display ":obj
penup, moveto :location, turn :direction
create :obj :size
if :thrust > 0 then create flame :size
if :thrust < 0 then create retro flame :size
pause until clock = :time + :framelag
end to
to ?crash :object
find all (create spaceship :s)
if :object ≠ :s
and |:object:location:x - :s:location:x| < :close
and |:object:location:y - :s:location:y| < :close
then explode :s, explode :obj
end to
to explode :object
penup, moveto :object:location
flash
finish :object
end to
to torpedo :speed :direction :location
use :thrust 0
bump :numtorps
moveship
if not (0 < :location:x < 1024 and 0 < :location:y < 1024)
then ?bump :numtorps, finish :self
end to
to start
repeat ask "how many will be playing?" times
create spaceship ask "pilot's name?"
stick.(make :sn be ask “stick number?”).y
stick.:sn.x
stick.:sn.but
end repeat
if (make :char be ask) = “s” then done
find all (create spaceship :x)
start :x
end to
*start
how many will be playing?
*2
pilot's name?
*Jimmy
stick number?
*2
pilot's name?
*Bill
stick number?
*3
付録2: Smalltalk-72版 全コード(Smalltalk-72エミュレータのSnippetsウインドウへのコピペと二回クリックによるターミナルへの転送用)
"disp _ dispframe 16 480 8 670 string 2000. disp clear
to ship size (
@ penup turn 180 go 2 * :size turn 90
go 1 * size turn 90
pendn go 4 * size turn 30 go 2 * size
turn 120 go 2 * size
turn 30 go 4 * size
turn 30 go 2 * size
turn 120 go 2 * size
turn `150 go (sqrt 3) * 2 * size
turn `150 go 2 * size
turn 120 go 2 * size
turn `150 go (sqrt 3) * 2 * size
penup turn `90 go 1 * size turn 90 go 2 * size)
to triangle size (
@ pendn turn 90 go 0.5 * :size
turn `120 go size
turn `120 go size
turn `120 go 0.5 * size turn `90
penup)
to flame size (
@ penup turn 180 go ((sqrt 3) + 2) * :size pendn.
triangle size. @ go 0.5 * size.
triangle 1.5 * size. @ go 0.5 * size.
triangle 2 * size. @ go 0.5 * size.
triangle size. @ go size.
@ penup turn 180 go ((sqrt 3) + 2.5 + 2) * size)
to abs x y (0 > :x ? (!-x) !x)
to sqrt x y z (
0.0 > :x ? (error)
0.0 = x ? (!0)
"y _ 1.0 * x.
"z _ 1.0e`8 * x.
repeat (z > y - "y _ y - ((y * y) - x) / y * 2 ? (done)).
x is float ? (!y)
z > abs y - "x _ 1 * y + z ? (!x) !y)
"PI _ 3.14159265
to nfact acc n m (
7 < :m ? (error "(16 bit signed int overflow))
"acc _ 1. for n to m do ("acc _ acc * n) !acc)
to sin acc x n m (
"x _ (:) mod 360.
(180 < x ? ("x _ x - 360))
(90 < x ? ("x _ 180 - x)
`90 > x ? ("x _ `180 - x))
"x _ (PI / 180) * x.
"acc _ 0.0.
for n _ 0 to 3 do (
"m _ 1 + 2 * n.
"acc _ acc + ((`1.0 ipow n) * (x ipow m) / nfact m))
!acc)
to cos (!sin 90 + :)
to retro (@ turn 180)
to rand low high : : n (
(%seed ? (:n))
(null n ? ("n _ 12345))
"n _ n &- n &/ 7.
"n _ n &- n &/ `9.
"n _ n &- n &/ 8.
%between ? (:low. :high. !low + n mod high + 1 - low)
!(32768.0 + n) / 65535.0)
to clock (!mem 280)
PUT vector "each nil
addto vector "(%do ? (:#y. for x to SELF length ("each _ SELF[x]. y eval)))
to t each (ev)
t
to each (!vec[i])
PUT obset "each #each
done
addto obset "(%do ? (:#input. for i to end (input eval))
to moveship (
"speed _ speed + SPSCALE * thrust.
"direction _ (direction + DIRSCALE * steer) mod 360.
"locx _ (locx + (cos direction) * LSCALE * speed) mod 512.
"locy _ (locy + (sin direction) * LSCALE * speed) mod 512)
to stick x y i kcode : keys val : kmap (
%delete ? (%all ? ("kmap _ nil)
:#x.
for i to 256 do ("y _ kmap[i]. eq #x #y ? (kmap[i] _ nil)). )
(null kmap ? ("kmap _ vector 256))
%process ? ("x _ kmap[1+:kcode].
null #x ? (!false)
x handle kcode. )
isnew ? (
(1 = :keys length ? ("val _ false) "val _ 0).
for i to keys length do (kmap[1+keys[i]] _ #SELF))
%print ? (disp _ '(stick '. disp _ 39. disp _ keys. disp _ 39. disp _ ') ')
%handle ? (
:kcode.
1 = keys length ? ("val _ true)
1 = keys[1 to 2] find first kcode ? ("val _ val - 1) "val _ val + 1)
eq val true ? ("val _ false. !true)
!val
)
to keysens (
%step ? (repeat (kbck ? (stick process kbd) done))
#keysens)
to spacewar x y : : objects (
(null objects ? ("objects _ obset))
%schedule ? (objects _ :#)
%delete ? (%all ? ("objects _ nil) objects delete :#)
%run ? (
repeat (
objects do (null each ? () each step).
1 = objects vec length ? (done)))
%find ? (%all. :"x. "y _ obset.
objects do (each is~ = x ? (y _ each)).
!y))
to crash object other (
%~. "object _ :#.
spacewar find all spaceship do (
"other _ each.
eq #object #other ? ()
CLOSE < abs (object locx - other locx) ? ()
CLOSE < abs (object locy - other locy)? ()
explore object. explore other))
to explore object (
:#object.
@ penup goto object locx object locy.
flash.
finish object
)
to flash (
do 10 (
@ penup turn 36 go SSIZE * 2.
@ pendn triangle SSIZE * rand between 2 5.
@ penup turn 180 go SSIZE * 2 turn 180))
to finish obj stk (
:#obj.
obj release.
spacewar delete obj)
to torp size (
@ penup turn 180 go :size turn 90
go 0.5 * size turn 90
pendn go 2 * size turn 30 go size
turn 120 go size
turn 30 go 2 * size
turn 30 go size
turn 120 go size
penup turn 120 go 0.5 * size turn `90 go size)
to torpedo : thrust steer locx locy speed direction time
ftime llocx llocy ldir lthr launcher endlife (
isnew ? (:launcher. :speed. :locx. :locy. "ldir _ :direction.
"locx _ "llocx _ locx + (cos direction) * SSIZE * 10.
"locy _ "llocy _ locy + (sin direction) * SSIZE * 10.
launcher bumptorps.
"thrust _ "lthr _ "steer _ 0.
"time _ "ftime _ clock.
"endlife _ clock + TORPLIFE)
%release ? (
stick delete thrust.
stick delete steer.
stick delete trigger)
%locx ? (!locx)
%locy ? (!locy)
%step ? (
0 < clock - time + MOVELAG ? (
"time _ clock.
0 < clock - endlife ? (
launcher debumptorps.
display torp erase.
finish SELF)
moveship.
crash~ SELF.
display torp))
%is ? (ISIT eval)
)
to display obj (
:#obj.
0 < clock - ftime + FRAMELAG ? (
"ftime _ clock.
@ penup goto llocx llocy up turn ldir + 90 pendn white.
obj SSIZE.
(0 < lthr ? (flame SSIZE)
0 > lthr ? (retro flame SSIZE)).
@ penup goto locx locy up turn direction + 90 pendn black.
%erase ? ()
obj SSIZE.
(0 < thrust ? (flame SSIZE)
0 > thrust ? (retro flame SSIZE))
"llocx _ locx. "llocy _ locy. "ldir _ direction ."lthr _ thrust))
to spaceship newtorp : pilot thrust steer trigger numtorps locx locy speed direction time
ftime llocx llocy ldir lthr (
isnew ? (:pilot. "lthr _ :#thrust. :#steer :#trigger.
"numtorps _ "speed _ 0.
"direction _ "ldir _ 0 + rand * 360.
"locx _ "llocx _ rand between 50 462.
"locy _ "llocy _ rand between 50 462.
"time _ "ftime _ clock)
%release ? (
stick delete thrust.
stick delete steer.
stick delete trigger)
%locx ? (!locx)
%locy ? (!locy)
%step ? (
0 < clock - time + MOVELAG ? (
"time _ clock.
(trigger ? (3 > numtorps ? (
"newtorp _ torpedo SELF speed locx locy direction.
spacewar schedule newtorp))
moveship.
crash~ SELF.
display ship)))
%is ? (ISIT eval)
%bumptorps ? ("numtorps _ numtorps + 1)
%debumptorps ? ("numtorps _ numtorps - 1)
)
to ask (disp _ :. !read eval)
to start ss pilot sy sx sbut (
"SSIZE _ 6.
"MOVELAG _ "FRAMELAG _ 0.
"SPSCALE _ 1.0. "DIRSCALE _ 1.0. "LSCALE _ 1.0.
"CLOSE _ SSIZE * 3.
"TORPLIFE _ 2000.
spacewar delete all.
spacewar schedule keysens.
stick delete all.
do ask 'how many will be playing~ ' (
"pilot _ ask 'pilot''s name str~ '.
"sy _ stick ask 'two chars (keys) str for stick y-axis~ '.
"sx _ stick ask 'tow chars (keys) str for stick x-axis~ '.
"sbut _ stick ask 'one char (key) str for stick button~ '.
"ss _ spaceship pilot sy sx sbut.
spacewar schedule ss)
disp _ 'type ''esc'' to exit...'.
spacewar run)
"disp _ dispframe 16 480 514 184 string 2000. disp clear
@ erase. disp display.
start