はじめに X上でなぜかしばしば直接的・間接的に絡んでくださる谷口一平氏が、次のようなポストを投稿していた。 永井哲学と入不二哲学の基本的な関係は、 θ=π/2つまり90度の回転である。すなわちそこでは、タテのもの(超越論的構成)はヨコ(横方向への展開運動)とされ、ヨコのもの(山括弧の存在)はタテ(垂直に働く現実性の力)とされるからである。もちろん、ただ回転しただけでは全然ないが。— 谷口一平 A.k.a.hani-an (@Taroupho) 2024年3月14日 永井哲学と入不二哲学の関係は π/2 らしい。 永井哲学か入不二哲学の一方のノルムが0の場合でも、内積は0になるけどね。 本記事で…
はじめに スケルツォ見てスッキリ。nikkieです。 OpenAIから2024年1月のアップデートが来ましたね。 その中の目玉と思われるembedding新モデルのAPIで少しだけ手を動かしました 目次 はじめに 目次 OpenAI embedding新モデルのAPI APIでembeddingを得て、テキストの類似度計算 英語の例(text-embedding-3-small) 日本語の例(text-embedding-3-small) text-embedding-3-large(日本語) text-embedding-3-large(日本語)でdimensionsを指定する 積ん読資料た…
自然言語処理(NLP)は、テキストデータを解析して意味や構造を理解するための技術です。文書間の類似度を計算することは、情報検索や文章分類などのタスクで重要な役割を果たします。本記事では、Pythonのライブラリであるgensimを使用して、文書間のコサイン類似度を計算する方法について解説します。具体的な例とコードを交えて説明します。 gensimとは gensimは、PythonのNLPライブラリで、トピックモデリングやベクトル空間モデルなどのNLPタスクを効果的にサポートします。特に、大規模なテキストコーパスに対応しており、多くの研究者や開発者に利用されています。gensimは、LDAなどの…
こんにちは、ぱそきいろです。以前、マイニングしたETHをなるべく出金手数料を少なくする方法を調べました。 www.takacpu55.xyz この中でETH→BTCを経由して楽天キャッシュにチャージするという方法でしたが、売り時をどうするかという問題があります。 つまり、ETHが上がって日本円(楽天キャッシュ)にしようとしてもBTCが下がっていたら結果的に損をするのでは無いかという気がします。 グラフを見たらおそらく(擬似)相関があるのだろうという気がしますが、勉強をかねて相関を出す方法を考えてみました。 データのDL データ前処理 相関係数 コサイン類似度 まとめ データのDL ここからデー…
ふと、桃太郎に似た昔話ってなんだろうと思いコサイン類似度を使って桃太郎に似た昔話を探してみました。今回は mecab にneologd 辞書を使ってます。 昔話の取得先 文章の類似度の計算 コサイン類似度 環境準備 類似度の算出 事前準備(追加インストール) mecab-python3 インストール neologd 辞書インストール 動作確認 昔話のファイル作成 桃太郎 浦島太郎 さるかに合戦 一寸法師 わらしべ長者 pythonスクリプト 実行結果 昔話の取得先 昔話は以下のサイトのものを使わせていただきました。 www.douwa-douyou.jp 文章の類似度の計算 コサイン類似度 コ…
はじめに アヤさん、たんじょーび、おめでとう!! nikkieです。 みんなアイうた見ていて嬉しい限り♪ sentence-transformersというPythonのライブラリがあります。 こいつでembeddings(テキストの埋め込み表現)が計算できるらしく、気になったので触ってみました。 ※レベル感としては使い出しレベル、やってみた系です。 目次 はじめに 目次 動作環境 ドキュメントの例でembeddingsを計算(英語テキスト) 日本語テキストからembeddingsを計算 終わりに 動作環境 macOS 12.6.6 CPU環境です Python 3.10.9 sentence-…
こんにちは。Algomatic の宮脇(@catshun_)です。 本記事では文書検索において一部注目された BGE M3-Embedding について簡単に紹介します。 Chen+'24 - BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
前にこんなことやってました。 www.nogawanogawa.work コサイン類似度の計算を高速化したくなることがちょくちょくあるのですが、「ぶっちゃけどれくらいのスループットが出せるもんなの?」というのが気になったので完全に興味本位でやってみます。
G-gen の神谷です。本記事では、BigQuery の機能を使って、商品を意味&ランキング検索できる ChatBot を作ってみたので、そのご紹介ができればと思います。 アプリの概要 ユースケース 背景とメリット アーキテクチャ システムアーキテクチャ RAG テーブル設計 検索処理の詳細 使っている技術と実装例 BigQuery ML のテキストエンべディング関数 BigQuery リモート関数用のコネクションオブジェクト作成 Vertex AI API を BigQuery のリモート関数として登録 テキストデータからエンベディングベクトルの抽出 BigQuery ML の類似ベクトル検…
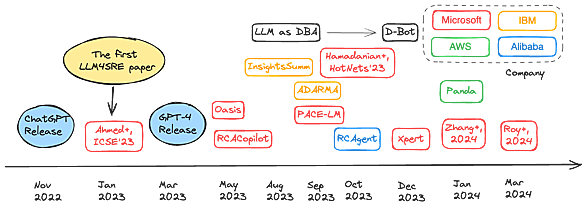
ChatGPTが登場した当初、対話や要約、翻訳、コード生成などの典型的な言語タスクができても、SREやAIOpsの研究開発にはあまり関係ないのではないかと正直思っていた。AIOpsでは典型的にはいわゆるObservabilityデータ(メトリクス、ログ、トレースなど)が入力となるため、自然言語ではなく数値のデータを解析することが求められる。自然言語のタスクを研究対象としていなかったため、AIOpsとChatGPTに強い関係性は見いだせなかった*1。 しかし、自分で大規模言語モデル(Large Language Model: LLM)を日常的に使用したり、表題にあるようにSREのためのLLM(L…
これは、なにをしたくて書いたもの? Qdrantのチュートリアルから、「検索品質を測定する(Measure retrieval quality)」を試してみたいと思います。 Measure retrieval quality - Qdrant 今回のチュートリアルの狙い 今回扱うチュートリアルは、こちらの「検索品質を測定する(Measure retrieval quality)」です。 Measure retrieval quality - Qdrant どういうことをするのか?というのは、まずはこのページを読み進めて見てみようと思います。 まずは冒頭を読むと、このチュートリアルでは「セマンテ…
「こんな感じのAPIサーバー立てといて」なんて言葉、開発してれば日常茶飯事です。 そんな「APIサーバーを立てる」と言ってもいろんな種類がありますね。 今回はよくあるAPIサーバーを一通りPythonで立てるだけ立ててみようと思います。 ランキング参加中Python ランキング参加中プログラミング
はじめに こんにちは、検索基盤部の広渡です。検索基盤部では、検索クエリのサジェスト(以下、サジェスト)の改善を行なっています。ここでサジェストは一般的に「Query Auto Completion」と呼ばれる、検索クエリを入力した際に入力の続きを補完したキーワードを提示する機能を指します。 ZOZOTOWNにおいては検索クエリを入力したとき、最大10件の検索クエリのサジェスト(以下、サジェストリスト)が表示されます(なお、ランキングを考慮しない場合はサジェスト集合と呼ぶこととします)。また、サジェストリストのランキングはユーザーの行動ログを用いて計算されたスコアによって決定されます。サジェスト…
統合英和辞書には各見出し語の典型的な共起語のリストを収録しているが、その生成をChatGPTにやらせてみた。結構まともな結果が得られ、類語検索や連想単語帳の精度が上がった。さらに、例文を選択する際にその共起語を含むものを優先することで、より典型的な例文を提示できるようにした。
概要 埋め込みモデルe5-mistral-7b-instructを使って、テキスト間のコサイン類似度を計算する方法をまとめる。 ※内容が間違っている可能性があります、ご容赦ください。 e5-mistral-7b-instruct 今回使用する、埋め込みモデルです。 2024年2月17日現在、MTEB LeaderboardのEnglishで4位となっています。 多言語でも使えますが、英語の使用が勧められています。 huggingface.co 実装 こちらを参考に実装しています。 huggingface.co import torch import torch.nn.functional as…
こんばんは。 無印で売り切れになってたカレンダーが復活してたので、買って帰ったら4月始まりでした。前回は基礎編でしたが、今回は検索編です。 shironeko.hateblo.jpRAGパターンもそうですが、結局どこかからデータを集めたりLLMに渡したりしないと独自データは利用できないので、このあたりはとても大事です。 今回のコードも引き続きGitHubに公開しています。 ちなみに自動テストで書くようにしたんですが、langchainjsがESMじゃないと動かなかったりするものがあってだいぶ混乱しました。(結局スキップしたけど…) github.com データの読み込み(DocumentLoa…
これは、なにをしたくて書いたもの? 先日、Qdrantのチュートリアルから「シンプルなNeural Searchサービスを作成する(Create a Simple Neural Search Service)」を 試しました。 Qdrantのチュートリアルから、「シンプルなNeural Searchサービスを作成する(Create a Simple Neural Search Service)」を試す - CLOVER🍀 今度は、「Fastembedを使ってシンプルなNeural Searchサービスを作成する(Create a Neural Search Service with Faste…
これは、なにをしたくて書いたもの? Qdrantのチュートリアルを進めてみようシリーズです。 今回は「シンプルなNeural Searchサービスを作成する(Create a Simple Neural Search Service)」を試します。 Neural Search Service - Qdrant Neural Search? ところで、Neural Searchってなんでしょうね? 少し調べてみましょう。 Amazon OpenSearchより。 何年もの間、お客様は OpenSearch k-NN でセマンティック検索アプリケーションを構築してきましたが、テキスト埋め込みモデル…
単語 文字Nグラムとは、長さNの部分文字列のこと。N=1はユニグラム、N=2はバイグラムという。文字Nグラムの頻度分布でテキスト中の良く使われている部分文字列を調べたり、隣り合う確率の高い文字を調べることができる。 Physonの形態素解析モジュールにはMeCab、janomeがある。形態素解析で品詞の推定もできる。 bag-of-words:形態素の多重集合で文書を表す。 特徴語:文書の中で内容を表す語のこと。 不要語(stop word):どのような文書でも特徴語になりえない語。日本語の不要語リストにはSlothLibで提供されているものがある。 文書dの特徴語wの条件: ①wはdに高頻度…
これは、なにをしたくて書いたもの? 先日、Qdrantをインストールしてみました。 Ubuntu Linux 22.04 LTSにベクトルデータベースQdrantをインストールして試す - CLOVER🍀 ここからどう進めたものか、というところなのですが、Quickstartの最後にチュートリアルを読んだり例を読むことが勧められていたので、 しばらくチュートリアルを試してみたいと思います。 To move onto some more complex examples of vector search, read our Tutorials and create your own app wi…





 shuyo.hatenablog.com
shuyo.hatenablog.com
 pgsqldeepdive.blogspot.com
pgsqldeepdive.blogspot.com private.ceek.jp
private.ceek.jp
 tsubosaka.hatenadiary.org
tsubosaka.hatenadiary.org www.cse.kyoto-su.ac.jp
www.cse.kyoto-su.ac.jp handin.sakura.ne.jp
handin.sakura.ne.jp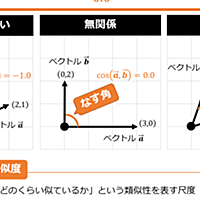
 atmarkit.itmedia.co.jp
atmarkit.itmedia.co.jp
 dev.classmethod.jp
dev.classmethod.jp
 mathetake.hatenablog.com
mathetake.hatenablog.com