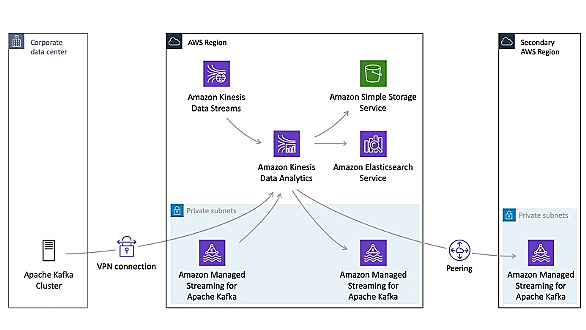
お題は次のエントリです。 gonsuke777.hatenablog.com 上記エントリではいわゆるコントロールブレイク処理(ソート済みのレコードを読み込み、キー項目ごとにグループ分けして行う処理のことでキーブレイク処理と呼ぶことも)を 1 本の SQL でスマートに行っています。これと同じことを PySpark でやってみるという話です。 次のような CSV ファイルを用意しておきます。 sales_date,jan_code,sales_cnt 2014/10/06,AAA,100 2014/10/07,AAA,200 2014/10/08,BBB,100 2014/10/09,BBB,…






 speakerdeck.com
speakerdeck.com
 www.publickey1.jp
www.publickey1.jp
 kimutansk.hatenablog.com
kimutansk.hatenablog.com
 www.intellilink.co.jp
www.intellilink.co.jp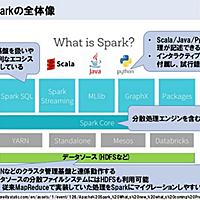
 www.publickey1.jp
www.publickey1.jp
 www.slideshare.net
www.slideshare.net
 www.slideshare.net
www.slideshare.net
 spark.apache.org
spark.apache.org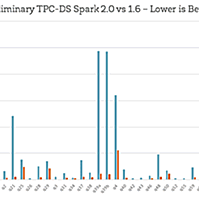
 www.publickey1.jp
www.publickey1.jp