OpenAIでは既にリリースされていますが、AzureでもFine-TuningがAzure OpenAI Serviceの新しいfine-tuningモデルのプレビューとして利用可能になったため、試してみました。 この更新にはChatGPTモデル(gpt-3.5-turbo-0613)も含まれております。社内データでファインチューニングしたChatGPTモデルを利用することによって、今までのChatGPTモデルよりもハレーションの少ない回答をすることが期待できます。 使えるファインチューニングモデルの種類 モデルの種類 使えるリージョン クォーター ファインチューニングモデルを作ってみる リ…
はじめに 結論 背景 課題 Fine-tuning とは? Data の準備 Fine-tuning を実施 結果 おわりに 参考 はじめに こんにちは、DROBE の都筑です。 みなさん LLM 使っていますか。今回は GPT-3.5-turbo の Fine-tuning の事例を紹介します。 結論 GPT-4 を利用して得られたデータを使って GPT-3.5-turbo を Fine-tuning する事で、特定のタスクに関しては GPT-4 相当の性能が出る事が確認できた GPT-4 利用時点で使っていたプロンプトをそのまま使った場合の性能が一番高く、token 節約のためにプロンプト…
こんにちは!今回は、GPT-3をfine-tuningしてキャラクター設定したAIと会話できるアプリをBubbleで構築していきます! fine-tuningとはモデルを再学習させる手法で、本記事では「つくよみちゃん」というキャラクターの会話データセットを使ってGPT-3 DavinciベースモデルをBubbleでfine-tuningします。さらにfine-tuningしたモデルでチャットアプリを実装する手順とアプリでのやり取りの様子もご紹介しているので、ぜひ最後までお読みください! なお、チャットアプリは「AIと対話できるチャットアプリをBubbleとGPT-3.5で構築する」の手順通りに…
はじめに データについて データソース データ加工 結果の評価 評価方法 結果サンプル サンプル1 サンプル2 サンプル3 サンプル4 サンプル5 評価まとめ 総括 はじめに 最近話題の GPT-3 で Fine-tunig を試してみたので、その結果を共有したいと思います。 評価した目的は下記の3つですが、この記事では皆さんが一番興味を持たれそうな 3.の精度についてお伝えします。 1.と2.には触れません。 GPT-3を Fine-tuning する方法を理解する。 GPT-3を Fine-tuning する際のコストや時間を理解する。 Fine-tuning をした結果、検索結果として回…
色々なモデル学習方法 モデルの追加学習方法は数百枚~数万枚の画像データで行う純粋なDiffusion Modelの追加学習から、1枚、あるいは数枚程度の軽微な学習まで色々あり、Google colabで行える方法をまとめた。 なお学習したモデルやFine-tuningはAUTOMATIC1111の正しい場所に配置する必要があり、その配置情報は下の記事にまとめた。 programmingforever.hatenablog.com メジャーなモデルの学習方法 vanilla fine-tuning(一般的な追加学習) Texture Inversion(数枚~のデータ) Hypernetwork…
少し古いですが「ファインチューニングの終焉(The End of Fine-tuning)」という記事が面白かったので、簡単なメモです。 www.latent.space この記事に登場するFast.aiのJeremy Howardさんは「事前学習→追加学習→RLHF」のように、フェーズごとにデータセットの種類・手法を完全に切り替えていく言語モデルの学習方法は「もはや正しくない」と主張しています。 「私は今では誰もが採用している 3 段階の学習アプローチを最初に考案しましたが、これは実は間違っており、使用すべきではないというのが私の今の見解です。正しい方法は、ファインチューニングという考えを捨…
ブレインパッドは、先端技術の解説から実装におけるノウハウなどをオウンドメディア等を通じて対外公開しています。 このたび Google Cloud 主催の、 GoogleCloud に関する優れた情報発信を表彰する「 Google Cloud Partner Tech Blog Challenge 」にて、当社のデータサイエンティストが、見事受賞をいたしました。本ブログでは、GoogleCloud のオフィスにて開催された表彰式の模様や、受賞したデータサイエンティストのコメントを紹介いたします。こんにちは、広報の長谷川です。 GoogleCloud に関する優れた情報発信を表彰する「 Googl…
こんにちは。Algomatic の宮脇(@catshun_)です。 本記事では文書検索において一部注目された BGE M3-Embedding について簡単に紹介します。 Chen+'24 - BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
ゼロから始める自作LLM 小さなLLMを多数組み合わせることで、単一の巨大モデルに匹敵する可能性 コンテナ使うならAzureで決まり!個人的推しサービスのAzure Container Appsを語る_ ML system design: 300 case studies to learn from GUIと日本語環境が使えるお手軽Docker環境の使い方 101 real-world gen AI use cases featured at Google Cloud Next ’24 Heron-Bench: 日本語Vision&Languageモデルの性能評価ベンチマークの公開 Intro…
目的 OpenAI のサービスについて、いつ何がローンチされたのか?など、どうしても忘れてしまうのでここにまとめていく ちなみに、時折サービスとは違うトピックも挟もうと思う おそらく、このページは長くなる 目次 目的 目次 過去の関連記事 Frontier Model Forum の立ち上げ at 2023-07-26 コンテントモデレーションに GPT-4 API を活用 at 2023-08-15 Global Illumination 社を買収 at 2023-08-16 GPT-3.5 Turbo の Fine-tuning が利用可能になった at 2023-08-22 ChatGP…
最初のGPT論文"Improving Language Understanding by Generative Pre-Training" の要約メモです。 はじめに Improving Language Understanding by Generative Pre-Training 概要 手法 結果 Natural Language Inferenceタスク Question answering / commonsense reasoningタスク Semantic Similarity / 分類タスク 分析 おわりに/所感 参考 はじめに 今回まとめる論文はこちら: Improving …
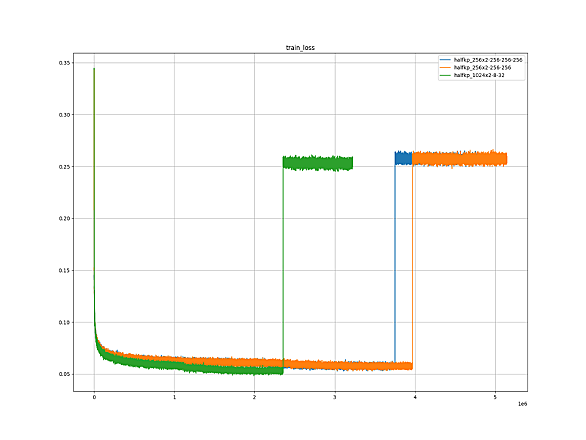
tanuki- 2024-04-17 halfkp_1024x2-8-16 実験内容 halfkp_1024x2-8-16 ネットワークを学習させ、レーティングを測定する。 ランダムパラメーターからの学習には、 Hao を用いて生成した学習データを用いる。 Fine-tuning に Fine-tuning Suisho10Mn_psv を学習データとして用いる。 棋譜生成 ランダムパラメーターから学習させる際の学習データ 生成ルーチン tanuki-棋譜生成ルーチン 評価関数 Hao (tanuki-.halfkp_256x2-32-32.2023-05-08) 1手あたりの思考 深さ最大 …
tanuki- 2024-04-12 halfkp_256x2-256-256-256 実験内容 halfkp_256x2-256-256-256 ネットワークを学習させ、レーティングを測定する。 ランダムパラメーターからの学習には、 Hao を用いて生成した学習データを用いる。 Fine-tuning に Fine-tuning Suisho10Mn_psv を学習データとして用いる。 棋譜生成 ランダムパラメーターから学習させる際の学習データ 生成ルーチン tanuki-棋譜生成ルーチン 評価関数 Hao (tanuki-.halfkp_256x2-32-32.2023-05-08) 1手…
今井翔太さんの「生成AIで世界はこう変わる」を読みました。まずは、強化学習とか自己教師あり学習、教師ありファインチューニング(Supervised Fine-Tuning)、人間からのフィードバックに基づく強化学習(RLHF:Reinforcement Learning From Human Feedback)といった基本的な言葉の意味が具体的に判って良かった。あとはトランスフォーマーについても概念的には判ったような気がする。以下3点ほどピックアップ。 まず、ポランニーのバラドクス(人は言葉で表現できる以上のことを知っている)いわゆる暗黙知の一部は、機械でも学習可能であるということ。 マーガレ…
tanuki- 2024-04-09 halfkp_256x2-256-256 実験内容 halfkp_256x2-256-256 ネットワークを学習させ、レーティングを測定する。 ランダムパラメーターからの学習には、 Hao を用いて生成した学習データを用いる。 Fine-tuning に Fine-tuning Suisho10Mn_psv を学習データとして用いる。 棋譜生成 ランダムパラメーターから学習させる際の学習データ 生成ルーチン tanuki-棋譜生成ルーチン 評価関数 Hao (tanuki-.halfkp_256x2-32-32.2023-05-08) 1手あたりの思考 深…






 qiita.com
qiita.com
 tech.drobe.co.jp
tech.drobe.co.jp
 spjai.com
spjai.com
 dev.classmethod.jp
dev.classmethod.jp
 openai.com
openai.com
 dev.classmethod.jp
dev.classmethod.jp
 tech.preferred.jp
tech.preferred.jp
 radiology-nlp.hatenablog.com
radiology-nlp.hatenablog.com
 acro-engineer.hatenablog.com
acro-engineer.hatenablog.com