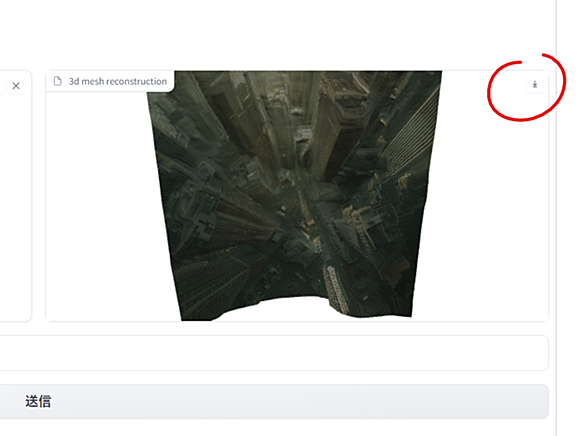
HuggingFace全然使ったこと無いマンなのですが、面白いサービスを見つけたのでご紹介! 静止画→3Dモデルにするまでの手順 下記にアクセス huggingface.co 添付赤丸①に画像をD&Dして、「Keep occulusion edge」にチェックし、「送信」すると、右側に3Dモデルが出現!スピードが早い! ダウンロードは右上の「↓」ボタンより おわりに ダウンロードしたglbファイルは、Blenderや各種DCCツールで読み込むことができるので、サクッと立体的な背景を作りたい時に使えそうです! ちなみにAfterEffects2024からは glb ファイルも読み込めるみたいです…
まえがき 言語モデルを自分でガッツリ使う経験が今まで無かったので、勉強がてら先週火曜日まで開催されていたKaggle - LLM Science Exam というコンペに参加してました。 www.kaggle.com そこそこ頑張った結果、過去最高の成績(49th/2663, Top2%)を取ることができ、銀メダルを取ることができた。SolutionなどはKaggleの方に書いたのでそちらを。 www.kaggle.com で、この記事で触れるのは、今まで機械学習モデルのトレーニングにはPyTorchの標準的なやり方(ループ内で推論してloss計算してloss.backward()で逆伝播させ…
今回もDeepLearningについての記事です。 HuggingfaceのTrainerで学習させたときに、学習途中のログをTensorboard用に出力する方法についてまとめます。huggingface.co Tensorboardのログ出力設定 Tensorboardのログを出力するために必要なライブラリ コマンド引数でログの出力先を指定する方法
今回は深層学習の自然言語モデルである、BERTについて色々触っていたのでその記録を簡単にまとめたいと思う。 ひょんなことから、BERTの事前学習からやらなければならなかったので、実際に用いたライブラリや環境、学習に必要な時間などについて書いていく。 BERTのライブラリ 学習環境 AMI Instance Type inf1.2xlarge p2系 p3.2xlarge p3.8xlarge g4dn.8xlarge g4dn.12xlarge 今回学んだこと BERTのライブラリ BERTのライブラリとしては、huggingfaceのTransformersを利用。 huggingface.…
固有表現抽出のタスクでは、CoNLL2003というShared Taskのデータセットがある。 今回はCoNLL2003のデータセットを用いて、BERT-baseのモデルをfine-tuningする。 paperswithcode.com CoNLL2003のデータセットを取得 wget https://data.deepai.org/conll2003.zip unzip conll2003.zip ls -l train.txt valid.txt test.txt 使用する事前学習済みモデル 今回は、事前学習済みモデルとして、BERT-baseのuncasedモデルを利用する。 unca…
みなさんこんにちは。たかぱい(@takapy0210)です。 本日はTensorFlow×Transformers周りでエラーに遭遇した内容とそのWAです。 環境 実装内容 エラー内容 エラーの原因 ワークアラウンド なんでこれで解消できるのか? モデルの保存方法 参考 環境 実行環境は以下の通りです python 3.7.10 transformers 4.12.5 tensorflow 2.3.0 実装内容 一部抜粋ですが、TransformersのTFBertModel*1に、独自のレイヤーをいくつか追加した2値分類モデルの学習を行いました。 import tensorflow as t…
Huggingfaceのtransformersライブラリでv3.4.0を使う 固有表現抽出をtransformersライブラリで行う。 東北大学のBERTモデルを使う場合は、Huggingfaceのtransformersライブラリでv3.4.0を使う必要がある。 - 東北大モデル以外(NICT, 京大など)なら、最新のtransformersが使える(examples/pytorch/token-classification/run_ner.py)。入力ファイルはjsonにするのがおそらく楽で、jsonファイルは1行に1文の情報で、単語列とラベル列からなるもの。何か見落としなどあれば教えて…
はじめにこちらのスクリプトをDiffusers用に書き換えました。 touch-sp.hatenablog.com スタイル画像こちらの画像を使わせてもらいました。 結果シードを変えて4枚の画像を作成しました。スタイルを維持しながらウサギを猫に変えています。 PC環境 Windows 11 CUDA 11.8 Python 3.11Python環境構築 pip install torch==2.2.2+cu118 --index-url https://download.pytorch.org/whl/cu118 pip install git+https://github.com/huggi…
日本語対応の画像生成AI「Sakana AI」をつかってみた|画像生成と会話するAIの魅力と可能性https://note.com/chat_gpt777/n/n4afa51555ad0 画像生成AI「Sakana AI」が発表されたので使ってみた。プロンプトは日本語でも英語でも使える。そしてrunを押すと生成が始まるが2.3秒で完了。作成される枚数は1枚ですがすごく速い。今までの画像生成AIの中では一番速いかもしれない。Stable Diffusionを改良したものだと思う。生成された画像の質はそれなりにという感じで、高品質です。でもそれ以外でももっと品質のいいものもある。この「Sakana…
あのバイトダンスから高品質な生成AIモデル「HyperSD」がリリースされています。 画像比較が紹介されており、以下の画像では上部がハイパーSDXLとなっています。 よりシャープでめりはりのあるくっきりとした画像になっているのがわかります。 犬は「カメラマンが撮った犬」といった感じですし、ガラスのハートは非常にクリアで透明感がしっかりと再現されています。 Hyper-SD: Trajectory Segmented Consistency Model for Efficient Image Synthesis こちらでは右側がハイパーSD. 人物は非常にくっきりメリハリがついているのがわかりま…
この記事では AnimateLCM に触れていきます。 LCM は初めて登場するキーワードですが、併せて調べていきます。 リリースノートの一番上にあったけど既読スルーしてたやつ
こんにちは。Algomatic の宮脇(@catshun_)です。 本記事では文書検索において一部注目された BGE M3-Embedding について簡単に紹介します。 Chen+'24 - BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
エキサイト株式会社エンジニアの佐々木です。詳細は話せませんがAI系の業務が発生したので、技術選定の一環でSpring AIを触ってみました。 前提 手順 1. Spring CLI をインストールする 2. Spring CLIでAI用のプロジェクトを作成する 3. OpenAIのAPIキーを取得します 4. 環境変数にAPIキーをセットします 5. SpringBootを起動します 6. リクエストしてみる 内部実装 ライブラリ コード Spring AIで使用できる一覧 まとめ さいごに 前提 $ java --version openjdk 17.0.10 2024-01-16 LTS …
NPUでLLM(opt-1.3b)のデモプロを動かすことができたので、今回はLlama2-7Bにチャレンジしてみた。結果的に動かすことはできたが、期待していた結果とは少し違っていた。導入手順とその中で気付いたことをここにまとめておきたい。 Copilotに頼んだらDALL E3が描いてくれました Step1 リポジトリのダウンロードと仮想環境の作成 こちらのページを見ながら環境を作成する。AnacondaからCMDプロンプトを起動して以下を実行する。 git clone https://github.com/amd/RyzenAI-SW.git cd RyzenAI-SW\example\tr…
ゼロから始める自作LLM 小さなLLMを多数組み合わせることで、単一の巨大モデルに匹敵する可能性 コンテナ使うならAzureで決まり!個人的推しサービスのAzure Container Appsを語る_ ML system design: 300 case studies to learn from GUIと日本語環境が使えるお手軽Docker環境の使い方 101 real-world gen AI use cases featured at Google Cloud Next ’24 Heron-Bench: 日本語Vision&Languageモデルの性能評価ベンチマークの公開 Intro…
Hugging Faceの数学モデルを使おうとしたら以下のエラーに見舞われました。OSError: open-math-mistral is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models' If this is a private repository, make sure to pass a token having permission to this repo either by logging in with `huggingface-cli…
結果左側の写真から右側の写真を作成しました。 PC環境 Windows 11 CUDA 11.8 Python 3.11Python環境構築 pip install torch==2.2.2+cu118 --index-url https://download.pytorch.org/whl/cu118 pip install git+https://github.com/huggingface/diffusers pip install accelerate transformers peft pip install onnxruntime-gpu insightfacePythonスクリプ…
こんにちは!ABEJAでデータサイエンティストをしている大谷です。 ABEJAは国立研究開発法人新エネルギー・産業技術総合開発機構(以下「NEDO」)が公募した「ポスト5G情報通信システム基盤強化研究開発事業/ポスト5G情報通信システムの開発」に当社提案の「LLMの社会実装に向けた特化型モデルの元となる汎化的LLM」が採択されたことを受け、LLMの事前学習を実施しました。 以降、本LLMプロジェクトをGENIAC(Generative AI Accelerator Challenge)と表記します。 開発内容は表題の通り、Mistral社のMIxtral 8x7Bをベースにした日本語の語彙拡張…
量子化時のモデル劣化を抑制する重要度行列(iMatrix; Importance Matrix)計算の話題です。 最近はHuggingFaceにアップされるGGUFも多くがiMatrix版となっていますが、これらの量子化でよく使われているiMatrix計算用データセットは以下の2種類のようです。 wiki.train.raw:Wikitext(英語版)のトレーニング用データセット。llama.cppのサンプルでもwiki.train.rawが使われている。iMatrix計算では、このうち10kトークンほど計算すれば実用的には十分な様子。 groups_merged.txt:koboldcppに…
はじめにWSL2上のLlama.cppで大規模言語モデルの「zephyr-7b-beta」を実行して、Windows上のChatUIでそれを利用してみました。無料で実行可能です。 github.com github.com必要なものWSL2にDocker Engineのインストールが必要です。 Windowsにnpmのインストールが必要です。使用した環境WSL2 Ubuntu 22.04 on WSL2 CUDA 11.8Windows Windows 11WSL2側でやることDockerのインストールこちらに従いました。 WSL2の場合は最初に以下のコマンドを実行しないとDockerが起動し…
モーション LoRA は複数を組み合わせて使うことが可能なようです。 例えばズームアウトとスライドを組み合わせて使う感じ この記事では、再び AnimateDiffPipeline を使い、モーション LoRA を組み合わせて使ってみます。
初めに 開発環境 ライブラリのインストール データセットのダウンロード 初めに テキストのコーパスとして以下のoscar-corpus/OSCAR-2301があります。こちらをダウンロードするコードのメモになります huggingface.co 開発環境 Ubuntu 22.02 ライブラリのインストール !pip install datasets !pip install zstandard データセットのダウンロード ja(日本語)のデータだけダウンロードします from datasets import load_dataset # ja(日本語)のデータセットをダウンロード datase…



 blog.bedrock.day
blog.bedrock.day
 gigazine.net
gigazine.net weel.co.jp
weel.co.jp
 github.com
github.com
 qiita.com
qiita.com
 github.com
github.com
 huggingface.co
huggingface.co
 github.com
github.com
 github.com
github.com



















