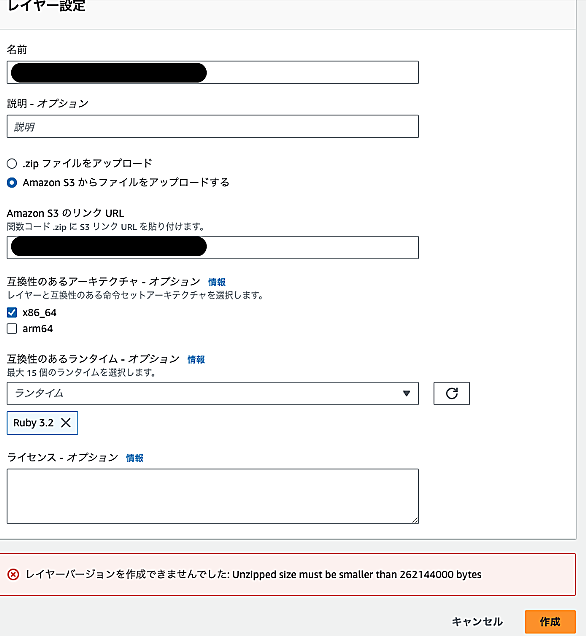
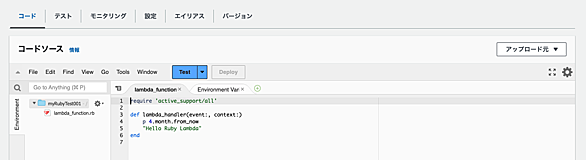
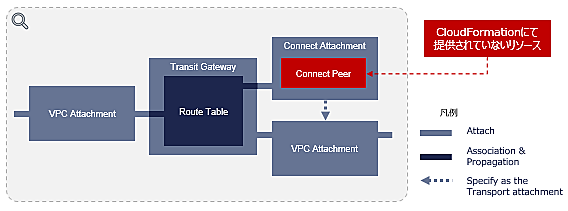
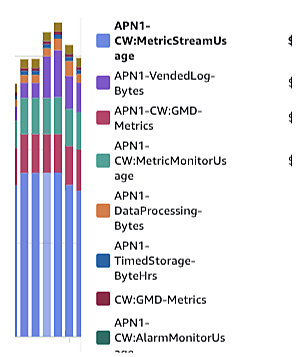
初めに 開発環境 詳細 初めに 開発環境 Ubuntu 22.02 詳細 以下で 並列でデータセットをtext化していきます。 CPUは最大限 並列化しています from datasets import load_dataset import os from tqdm import tqdm from joblib import Parallel, delayed # ja(日本語)のデータセットをダウンロード dataset = load_dataset("oscar-corpus/OSCAR-2301", "ja", split="train") # データセットをdictに変換(並列処理…





 eh-career.com
eh-career.com
 eh-career.com
eh-career.com
 www.keisuke69.net
www.keisuke69.net
 www.publickey1.jp
www.publickey1.jp
 blog.3qe.us
blog.3qe.us
 blog.3qe.us
blog.3qe.us
 www.keisuke69.net
www.keisuke69.net
 forest.watch.impress.co.jp
forest.watch.impress.co.jp
 zenn.dev
zenn.dev