AlphaGo
AlphaGoは、Google DeepMindの囲碁ソフト。日本語だと「アルファ碁」と記述されることもある。
従来とは異なり深層学習を用いたニューラルネットを基本としたアルゴリズムを使っているのが特徴。モンテカルロ碁アルゴリズムをベースにしているが、今までのモンテカルロ碁などに比べて格段に強くなったとされる。(なので囲碁ルールを暗黙の前提としているし、囲碁ルールに基づいて実装されているし、囲碁専用である。)
2016年3月9日、Google DeepMind Challenge Matchの第1局において、世界トップクラスの棋士李世乭(イ・セドル)9段に対して初勝利したのをきっかけに3連勝し、第4局は敗れたものの、最終第5局でも勝利し、4勝1敗と圧勝した。
過去の棋譜をニューラルネットに入力する「教師あり学習」と、勝利を報酬に囲碁AI同士を対局させて鍛える「強化学習(教師なし学習)」だけで、世界最強と称されるプロ棋士を破るまでに成長させた。なお、2015年10月の時点で、3000万局もの自己対局をこなしたという。
さらに後継のAlphaGo Zeroは、AlphaGoと100回対戦して全勝する圧倒的な強さを持つ。AlphaGoと異なり、人間の棋譜をまったく入力しない「教師なし学習」の自己対局のみで学習したのが特徴。
https://deepmind.com/alpha-go.html
![nature [Japan] January 28, 2016 Vol. 529 No. 7587 (単号)](https://images-fe.ssl-images-amazon.com/images/I/61Bq9bK9ufL._SL160_.jpg "nature [Japan] January 28, 2016 Vol. 529 No. 7587 (単号)")
nature [Japan] January 28, 2016 Vol. 529 No. 7587 (単号)
- 出版社/メーカー: ネイチャー・ジャパン
- 発売日: 2016/02/05
- メディア: 雑誌
- この商品を含むブログ (4件) を見る
")
最強囲碁AI アルファ碁 解体新書 増補改訂版 アルファ碁ゼロ対応 深層学習、モンテカルロ木探索、強化学習から見たその仕組み (AI & TECHNOLOGY)
- 作者: 大槻知史,三宅陽一郎
- 出版社/メーカー: 翔泳社
- 発売日: 2018/07/17
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る

最強囲碁AI アルファ碁 解体新書 深層学習、モンテカルロ木探索、強化学習から見たその仕組み
- 作者: 大槻知史,三宅陽一郎
- 出版社/メーカー: 翔泳社
- 発売日: 2017/07/19
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (3件) を見る
")
進化を続けるアルファ碁 最強囲碁AIの全貌 (囲碁人ブックス)
- 作者: 洪道場
- 出版社/メーカー: マイナビ出版
- 発売日: 2017/06/14
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る

- 作者: ホン・ミンピョ,金振鎬,洪敏和
- 出版社/メーカー: 東京創元社
- 発売日: 2016/07/28
- メディア: 単行本
- この商品を含むブログ (2件) を見る
")
- 作者: 斉藤康己
- 出版社/メーカー: ベストセラーズ
- 発売日: 2016/10/08
- メディア: 新書
- この商品を含むブログ (3件) を見る


 www3.nhk.or.jp
www3.nhk.or.jp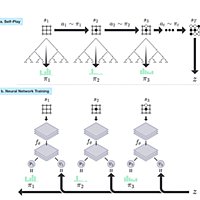
 blog.livedoor.jp
blog.livedoor.jp
 nlab.itmedia.co.jp
nlab.itmedia.co.jp
 note.com
note.com
 antibayesian.hateblo.jp
antibayesian.hateblo.jp
 gigazine.net
gigazine.net
 fukuyuki.net
fukuyuki.net
 aleag.cocolog-nifty.com
aleag.cocolog-nifty.com
 japan.googleblog.com
japan.googleblog.com