WildFly-27.0.0.1.Beta1とKotlinでJakarta EE10を試す
ひとつ前の記事でWildFly-27.0.0.1.Beta1を試してみたら簡単に動いてしまったのでKotlinでも試してみました。
WildFly-27.0.0.1.Beta1が立ち上がってる状態で、pom.xmlを書き換えます。
基本的にKotlinの公式サイトに載っているものをそのまま追加しています。(maven-compiler-pluginが古かったのだけ更新)
https://kotlinlang.org/docs/maven.html
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>dev.megascus</groupId> <artifactId>jakartaee10</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>war</packaging> <name>jakartaee10</name> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.release>11</maven.compiler.release> <kotlin.compiler.incremental>true</kotlin.compiler.incremental> <kotlin.version>1.7.20</kotlin.version> </properties> <dependencies> <dependency> <groupId>jakarta.platform</groupId> <artifactId>jakarta.jakartaee-api</artifactId> <version>10.0.0</version> </dependency> <dependency> <groupId>org.jetbrains.kotlin</groupId> <artifactId>kotlin-stdlib</artifactId> <version>${kotlin.version}</version> </dependency> </dependencies> <build> <finalName>${project.artifactId}</finalName> <plugins> <plugin> <artifactId>maven-war-plugin</artifactId> <version>3.3.2</version> <configuration> <failOnMissingWebXml>false</failOnMissingWebXml> </configuration> </plugin> <plugin> <groupId>org.wildfly.plugins</groupId> <artifactId>wildfly-maven-plugin</artifactId> <version>3.0.0.Final</version> </plugin> <plugin> <groupId>org.jetbrains.kotlin</groupId> <artifactId>kotlin-maven-plugin</artifactId> <version>${kotlin.version}</version> <executions> <execution> <id>compile</id> <goals> <goal>compile</goal> </goals> <configuration> <sourceDirs> <sourceDir>${project.basedir}/src/main/kotlin</sourceDir> <sourceDir>${project.basedir}/src/main/java</sourceDir> </sourceDirs> </configuration> </execution> <execution> <id>test-compile</id> <goals> <goal>test-compile</goal> </goals> <configuration> <sourceDirs> <sourceDir>${project.basedir}/src/test/kotlin</sourceDir> <sourceDir>${project.basedir}/src/test/java</sourceDir> </sourceDirs> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.9.0</version> <executions> <!-- Replacing default-compile as it is treated specially by maven --> <execution> <id>default-compile</id> <phase>none</phase> </execution> <!-- Replacing default-testCompile as it is treated specially by maven --> <execution> <id>default-testCompile</id> <phase>none</phase> </execution> <execution> <id>java-compile</id> <phase>compile</phase> <goals> <goal>compile</goal> </goals> </execution> <execution> <id>java-test-compile</id> <phase>test-compile</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
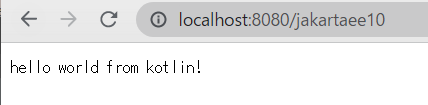
で、前回のTestServletをKotlinで書きなおします。 書き直してsrc/main/kotlinに移して、古いものを削除しています。
import java.io.IOException; import jakarta.servlet.ServletException; import jakarta.servlet.annotation.WebServlet; import jakarta.servlet.http.Cookie; import jakarta.servlet.http.HttpServlet; import jakarta.servlet.http.HttpServletRequest; import jakarta.servlet.http.HttpServletResponse; @WebServlet(name = "test", urlPatterns = arrayOf("/*")) class HelloWorld : HttpServlet() { @Override public override fun service(req: HttpServletRequest, res: HttpServletResponse) { val cookie = Cookie("TEST", "VALUE") cookie.setAttribute("Max-Age", "999") res.addCookie(cookie) res.getWriter().write("hello world from kotlin!") } }
最後に mvn wildfly:deploy でデプロイすると普通にアクセスできるようになりました。
WildFly-27.0.0.1.Beta1でJakarta EE10を試す
WildFlyもαからβに無事になり、そこそこ安定してそうなので試してみました。 思っていたよりはすんなり動いてよかったです。
WildFlyの準備
公式サイトにリンクが張られているので、ダウンロードします。
ダウンロードしたら適当な場所に解凍します。
実行する場合はbinの中に入っているstandalone.bat/standalone.ps1/standalone.shをOSに合わせて実行するのが一番早いです。
Javaが入っていない場合は先にJavaをダウンロードしてインストールしている必要があります。
※この記事では、Windows上でjava-11-openjdk-11.0.16-2を使用しています。あと、mavenも。
起動すると以下のようにログが流れて起動します。
Calling "C:\apps\wildfly-27.0.0.Beta1\bin\standalone.conf.bat" Setting JAVA property to "C:\Program Files\RedHat\java-11-openjdk-11.0.16-2\bin\java" =============================================================================== JBoss Bootstrap Environment JBOSS_HOME: "C:\apps\wildfly-27.0.0.Beta1" JAVA: "C:\Program Files\RedHat\java-11-openjdk-11.0.16-2\bin\java" JAVA_OPTS: "-server -Dprogram.name=standalone.bat -Xms64M -Xmx512M -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true -Djboss.modules.system.pkgs=org.jboss.byteman -Djava.awt.headless=true --add-exports=java.desktop/sun.awt=ALL-UNNAMED --add-exports=java.naming/com.sun.jndi.ldap=ALL-UNNAMED --add-exports=java.naming/com.sun.jndi.url.ldap=ALL-UNNAMED --add-exports=java.naming/com.sun.jndi.url.ldaps=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.lang.invoke=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.security=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.management/javax.management=ALL-UNNAMED --add-opens=java.naming/javax.naming=ALL-UNNAMED " =============================================================================== 19:38:37,719 INFO [org.jboss.modules] (main) JBoss Modules version 2.0.3.Final 19:38:38,206 INFO [org.jboss.msc] (main) JBoss MSC version 1.4.13.Final 19:38:38,211 INFO [org.jboss.threads] (main) JBoss Threads version 2.4.0.Final (中略) 19:38:40,595 INFO [org.jboss.as] (Controller Boot Thread) WFLYSRV0025: WildFly Full 27.0.0.Beta1 (WildFly Core 19.0.0.Beta18) started in 3107ms - Started 290 of 563 services (357 services are lazy, passive or on-demand) - Server configuration file in use: standalone.xml 19:38:40,596 INFO [org.jboss.as] (Controller Boot Thread) WFLYSRV0060: Http management interface listening on http://127.0.0.1:9990/management 19:38:40,597 INFO [org.jboss.as] (Controller Boot Thread) WFLYSRV0051: Admin console listening on http://127.0.0.1:9990
デフォルトでローカルホストの8080で立ち上がるのでアクセスしてみます。

実際にアプリを作ってみる
pom.xml
Jakarta EE 10のdependencyがあるので、それを使います。それ以外はwildfly-maven-pluginが入っている以外は普通のJakarta EE(Java EE)の最小限のpom.xmlです。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>dev.megascus</groupId> <artifactId>jakartaee10</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>war</packaging> <name>jakartaee10</name> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.release>11</maven.compiler.release> </properties> <dependencies> <dependency> <groupId>jakarta.platform</groupId> <artifactId>jakarta.jakartaee-api</artifactId> <version>10.0.0</version> </dependency> </dependencies> <build> <finalName>${project.artifactId}</finalName> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.9.0</version> </plugin> <plugin> <artifactId>maven-war-plugin</artifactId> <version>3.3.2</version> <configuration> <failOnMissingWebXml>false</failOnMissingWebXml> </configuration> </plugin> <plugin> <groupId>org.wildfly.plugins</groupId> <artifactId>wildfly-maven-plugin</artifactId> <version>3.0.0.Final</version> </plugin> </plugins> </build> </project>
Servlet
最低限のサーブレットと、Jakarta EE 10で新しく生えたAPIを使いたかったので、Cookie#setAttributeを呼び出してみています。
ネームスペースがjavaxからjakartaに変更されているのに注意してください。
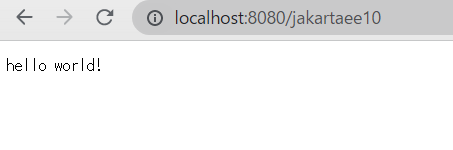
package dev.megascus.jakartaee10; import java.io.IOException; import jakarta.servlet.ServletException; import jakarta.servlet.annotation.WebServlet; import jakarta.servlet.http.Cookie; import jakarta.servlet.http.HttpServlet; import jakarta.servlet.http.HttpServletRequest; import jakarta.servlet.http.HttpServletResponse; @WebServlet(name = "test", urlPatterns = "/*") public class TestServlet extends HttpServlet { @Override public void service(HttpServletRequest req, HttpServletResponse res) throws ServletException, IOException { Cookie cookie = new Cookie("TEST", "VALUE"); cookie.setAttribute("Max-Age", "999"); res.addCookie(cookie); res.getWriter().write("hello world!"); } }
デプロイしてみる
デプロイは簡単で以下コマンドを打つだけです。
mvn wildfly:deploy
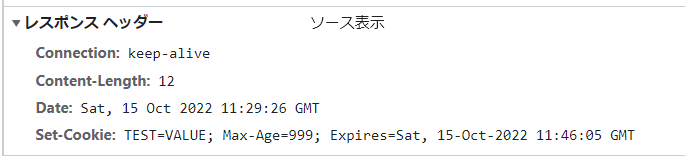
デプロイ先にアクセスしてみると確かにhello world!と表示されています。 また、Cookieも追加されていました。
ということで、Jakarta EE 10がリリースされて、すでにベータ版のリリースは始まっています。 早めに試してみてはいかがでしょうか。
Jakarta EE 10で新しくなった点(What’s new in Jakarta EE 10) の勝手翻訳
この記事は以下のブログの4月22日時点の勝手翻訳です。意訳も含みますし、元のブログは変更があり次第どんどん更新すると言ってるのでご注意ください。
Jakarta EE 10 は、"jakarta" 名前空間の更新以来、Jakarta EEの最初のメジャーリリースです。多くのコンポーネント仕様はAPIの実装に反映されるメジャーまたはマイナーバージョンが更新されています。この記事では次の新しいメジャーリリースから何が期待できるかを学びましょう。
プロジェクトの状況
最初に、 Jakarta EE 10の進行状況はGitHub上の進行状況ボードで追跡できます:
https://github.com/orgs/eclipse-ee4j/projects/21
リリースされると、以下のように包括的な依存関係を含めることができるようになります。
<dependency> <groupId>jakarta.platform</groupId> <artifactId>jakarta.jakartaee-api</artifactId> <version>10.0.0</version> <scope>provided</scope> </dependency>
JakartaEE10を実行するための要件
Java SE 11 が Jakarta EE互換の実装でサポートされる最小のバージョンのランタイムになります。
利用可能なプロファイル:
Jakarta EE 10では次のプロファイルを使用できます。
- Full Platform Profile:Jakarta EE APIのフルセットを必要とするエンタープライズアプリケーションの開発者向けに設計されたプロファイルです。
- Web Profile:Jakarta EE APIのすべてを必要としない開発者向けに設計された、Webテクノロジーが含まれているFull Platform Profileの一部で構成されるプロファイルです。
- Core Profile:この新しいプロファイルには、マイクロサービスと事前コンパイルに適したより小さなランタイムを対象とした一連の Jakarta EE 仕様が含まれています。
削除されたか非推奨になったAPI
次の2つの機能には"削除済み"もしくは"非推奨"のタグが付けられます。(正確な用語やメカニズムは未決定)
EJBエンティティBean(CMPおよびBMP) 埋め込み可能なEJBコンテナ
したがって、EJB 3.0以降のAPI(javax.ejb.Entityなど)で作成されたアプリケーションは、 Jakarta Persistence API(jakarta.persistence)の機能を使用して永続化エンティティをモデル化する必要があります。
最後に仕様のバージョン、プロファイル、必須かどうかを含んだJakarta EE 10 仕様の一覧を示します。
| 仕様 | プロファイル | 必須でないかどうか(Yなら必須でない) |
|---|---|---|
| Jakarta Activation 2.1 | Full Profile | N |
| Jakarta Annotations 2.1 | Web Profile | N |
| Jakarta Authentication 3.0 | Web Profile | N |
| Jakarta Authorization 2.1 | Full Profile | N |
| Jakarta Batch 2.1 | Full Profile | N |
| Jakarta Bean Validation 3.0 | Web Profile | N |
| Jakarta Concurrency 3.0 | Web Profile | N |
| Jakarta Connectors 2.1 | Full Profile | N |
| Jakarta Contexts and Dependency Injection 4.0 | Full Profile | N |
| Jakarta Debugging Support for Other Languages 2.0 | Web Profile | N |
| Jakarta Dependency Injection 2.0 | Web Profile | N |
| Jakarta Enterprise Beans 4.0 | Full Profile | N |
| Jakarta Enterprise Beans 4.0 Lite | Web Profile | N |
| Jakarta Enterprise Web Services 2.0 | Full Profile | Y |
| Jakarta Expression Language 5.0 | Web Profile | N |
| Jakarta Interceptors 2.1 | Web Profile | N |
| Jakarta JSON Binding 3.0 | Web Profile | N |
| Jakarta JSON Processing 2.1 | Web Profile | N |
| Jakarta Mail 2.1 | Full Profile | N |
| Jakarta Managed Beans 2.0 | Web Profile | N |
| Jakarta Messaging 3.1 | Full Profile | N |
| Jakarta Persistence 3.1 | Web Profile | N |
| Jakarta RESTful Web Services 3.1 | Web Profile | N |
| Jakarta Security 3.0 | Web Profile | N |
| Jakarta Server Faces 4.0 | Web Profile | N |
| Jakarta Server Pages 3.1 | Web Profile | N |
| Jakarta Servlet 6.0 | Web Profile | N |
| Jakarta SOAP with Attachments 3.0 | Full Profile | Y |
| Jakarta Standard Tag Library 3.0 | Web Profile | N |
| Jakarta Transactions 2.0 | Web Profile | N |
| Jakarta WebSocket 2.1 | Web Profile | N |
| Jakarta XML Binding 4.0 | Full Profile | Y |
| Jakarta XML Web Services 4.0 | Full Profile | Y |

※画像は元ブログより
主要なAPIアップグレード:
仕様はまだ策定中です。ただし、Jakarta EE 10で期待できる主なハイライトのいくつかをここに一覧化します。
Jakarta Persistence 3.1
- java.uti.UUID の追加。単純な主キー、複合主キーの両方でフィールドまたはプロパティとして使用できるようになりました。
- クエリ言語の新しい数値関数
- CEILING:引数の上限を返します。
- EXP:引数の指数を返します。
- FLOOR:引数のフロアを返します。
- LN:引数の自然対数を返します。
- POWER:最初の引数を2番目の引数の累乗で返します。
- ROUND:2番目の引数で指定された小数点以下の桁数に丸められた最初の引数を返します。
- SIGN:引数の符号を返します。
- クエリ言語の新しい日付関数
- LOCAL DATE:データベースサーバーによって定義された現在のローカル日付を返します。
- LOCAL DATETIME:データベースサーバーによって定義された現在のローカル日時を返します
- LOCAL TIME:データベースサーバーによって定義された現在のローカル時間を返します。
- EXTRACT関数のサポート:EXTRACT関数で特定の日付から数値部分を抽出でき、単一のフィールドのみを取得できます。
Jakarta Servlet 6.0
※訳者注:Servlet単独について知りたい場合は記事としてはこっちの方がよさそう。 Top 5 things to know about the Jakarta Servlet 6.0 API release - Coffee Talk: Java, News, Stories and Opinions
- 非推奨になっていたメソッドの削除
- Servlet のイミュータブルなrequest/responseのラッパー: 開発者は、持続性のある不変のリクエストとレスポンスを実装することができるようになりました。他のスレッドによるリクエストメソッドの呼び出しと、 リクエストが Servlet コンテナを伝搬する際に必要となる変更との間に競合が発生するからです。
- URIのセキュリティ保護機能を搭載:現在ではリクエストURIが複数の制約付きURLパターンにマッチするとき、リクエストに適用される制約は、最もよくマッチするURLパターンに関連付けられたものになります。しかしながら、制約付きURLパターンにマッチしないリクエストURIには、 保護要件は適用されません。
- Cookieの追加属性 : Cookieに自由に属性を追加できるようになります。
Jakarta RESTful Web Services 3.1
このトピックの詳細については、こちらの記事を確認してください: Getting started with Jakarta RESTful Services
- Java SE Bootstrap API: JAX-RSは、Java SE単独でも動作します。しかし、純粋なJavaSEでJAX-RSサーバーアプリケーションを起動する方法は仕様化されていません。ベンダーロックインを取り除くために、純粋なJavaSE環境でJAX-RSサーバーアプリケーションを起動する方法をベンダーに依存しないAPIで仕様として定義することを提案したいと思います。
- マルチパートメディアタイプのサポート:Jakarta EE 仕様はマルチパート/フォームの特定のサポートを提供していませんでした。MultiPartフォームはベンダー固有のアノテーションで実装され、これらの拡張機能に依存するコードは移植できなくなりました。(jersey では@FormDataParam、CXFでは @Multipart)multipart/form-dataメディアタイプを仕様に追加すると、リクエストが複数のエンティティ(パーツ)を単一のエンティティとして送信できるようになります。各部分には、独自のヘッダー、メディアタイプ、およびコンテンツが含まれています。
- JSON-Bとのより良い連携:アプリケーション提供のJSON-Bクラスの実装提供のエンティティプロバイダーはアプリケーションが提供するコンテキストリゾルバーによって提供されるJsonbインスタンスを使用する必要があります。 [contextprovider]を参照してください。アプリケーションが特定のタイプのJsonbインスタンスを提供しない場合は実装提供のエンティティプロバイダーはjsonbインスタンスの代わりに独自のデフォルトコンテキストを使用する必要があります。
- プロバイダー拡張機能の自動ロード:JavaのServiceLoader APIでマーカーインターフェイスを宣言するだけで、あらゆる種類のJAX-RSコンポーネントを強制的に自動ロードされるコンポーネントに変換する宣言型の方法が追加されます。実際には、提案されたメカニズムは実際にはコンポーネントをインスタンス化せずに宣言されたクラスを検出してJAX-RS構成に登録するだけなので、既存のJAX-RSコンポーネントのライフサイクルとスコープが適用されます。
- CDIとの整合性を高めるための準備としての@Contextの非推奨
Jakarta Server Faces 4.0
このリリースの目標はいくつかの新しい拡張機能(MyFacesおよびPrimefacesの実装から着想を得たもの)を含めることです。同時に、非推奨のものを削除し、CDIへの移行を促進します。
- プログラムでFaceletsを作成するための新しいAPI:現在Faceletsで行われているようなXMLを使用してビューを作成するのではなく、Javaでビューを作成するためのファーストクラスのサポート。
- 新しい自動拡張なしマッピング:org.apache.myfaces.AUTOMATIC_EXTENSIONLESS_MAPPING が仕様化されました。
- アノテーション@ClientWindowScoped の追加:PrimefacesのネイティブClientWindow実装と同様の方法でネイティブClientWindow実装が追加されます。
- カスタムCookie属性のサポート:ExternalContext#addResponseCookie() のSameSiteなど
- FacesContext#getLifecycleの追加:アプリケーション全体のフェーズリスナーをプログラムで追加および削除する場合に役立ちます。
- 非推奨だったものの削除:JSPサポートやネイティブのマネージドBean(@ManagedBeanおよびその他、CDIとに同様のものがあったもの)の削除など。
Jakarta Security 3.0
- 追加の認証メカニズム: ベンダーやカスタムの認証スキーマを完全に置き換えることができるようにJakarta Securityの認証メカニズムがに次のメカニズムが追加される予定です。 : Client-cert、 Digest、 OpenID Connect、 OAuth 2
- CDIとセキュリティ:セキュリティ仕様からビルドインのBeanにインターセプターバインディングアノテーションを適用する機能を追加します。詳細はこちら。
- FeaturesAuthorization モジュール:。ファクトリー、設定、ポリシーを含むJACCプロバイダー全体をバンドルする必要をなくしてカスタム認可ルールを簡素化。詳細はこちら。
- 認証機構の拡張:URLごとの認証機構を含むユーザーによる認証機構の選択(プロバイダXでログイン、プロバイダYでログインなど)、複数の認証機構(JWTを試してBASIC認証に戻すなど)。
JSON Processing 2.1
JSON Binding 3.0
WildFlyの Jakarta EE 10 サポート
WildFlyニュースで説明されているように、Jakarta EE 10のサポートはWildFly 27で計画されています。WildFly 27は、次の仕様と互換性があります。
Payara のJakart EE 10 サポート
PayaraチームはEclipse Foundationの戦略的メンバーとして、Enterprise APIの革新におけるトッププレーヤーです。Payara Application Serverのリリース6でJakarta EE 10を使用できるようになります。公式のPayara Jakarta ページでニュースを確認してください: https://www.payara.fish/learn/get-started-with-jakarta-ee/
Jakarta EE に Core Profile というのが増えていた
いつの間にかCore Profileというのが増えていました。
Jakarta EE Core Profileは特に小規模なランタイムを対象としたJakartaEEプラットフォームのプロファイルを定義しています。 マイクロサービスや事前コンパイル(=GraalVM)に適したより小さなランタイムを対象としています。
プロジェクトページはこちら。
ここまでで、これはMicroProfileと何が違うんだ?という疑問にあたりまして、調べたところ会議体が違うだけで中の人もほぼ一緒なものであるという認識が出来ました。
MicroProfile自体はJava EE時代にJavaEEの仕様策定のプロセスが遅い事やリソースを十分に供給できていないということに危機感を感じたいくつかのベンダーとJavaコミュニティ主体で発生しました。そしてEclipse Fundationで管理されていくことになります。
しかしながら、そのあと紆余曲折があり、Java EE自体がEclipse Fundationで管理されるようになり、Jakarta EEと名前を変え、Oracle本体の呪縛から解き放たれ、会議体としては別ではあるものの、中の人はほぼ一緒であるという状態になってしまいました。
Core Profile側の参加メンバー(投票者の所属企業を参照)
両方に参加されているPayara*1の人はブログで、MicroProfileもJakarta EEの一部になってほしい旨を書いています。
MicroProfile and Jakarta EE Technical Alignment
現時点でも二つの仕様はほぼ同じもののようで、Devoxx UKにてCore ProfileのメンバーがMicroProfileを実装した製品について、Core Profileに適合するポテンシャルがありますと話されています。
Jakarta EE Core Profile - A Slimmer Jakarta EE by Ivar Grimstad - YouTube
仕様に表すと以下のような感じです。
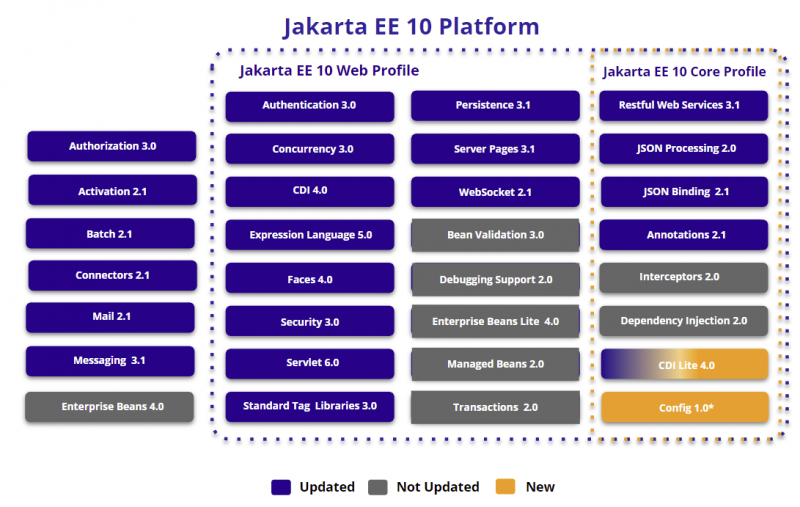
https://mobile.twitter.com/Payara_Fish/status/1513502920939032582 より

https://microprofile.io/projects/ より
ということで、私はてっきりCore Profileの方に統合されていくのかなー?と思っていたら、MicroProfile陣営もまだまだやる気のある人が居るらしくて、MicroProfile 6.0(Jakarta EE 10とAPI互換版)のリリースについても着々と進んでいるようです。
Core Profileだけに集約していくのか、両立していくのか不明なのですが、今後どうなっていくんでしょうかね?
レッドハット株式会社に入社しました
レッドハット株式会社に入社しました
JSP 3.1(Jakarta EE 10)の変更点まとめ
Jakarta EE 10でJSPのバージョンが3.1になりました。 Java EE 8ではJSPのバージョンは2.3で、そのあとの3.0はパッケージ名の変換のみだったので、 久しぶりの意味のある仕様変更になります。(定型文)
ということでまとめ。 ソースを読んで差分をざっくり眺めてるだけなので、間違い、抜け漏れは当然あります。あれ?と思った場所があったら教えてください。
ちなみに、3.0から正式名称がJakarta Server Pagesに変更されてます。(旧JavaServer Pages)
全般
意味のある仕様変更があるといったな?あれは嘘だ。
というのは言い過ぎではありますが、非推奨とされていたAPI、挙動の廃止が主となっており、あとはServletで触れたjsp-property-groupにErrorOnELNotFoundが増えた件に対応するもの、もしくはJavaDocの軽微な修正となります。
気になったのは、javadoc上lexical scope がsynchronization scopeに改められていましたが、spec上はlexical scopeのままなので、意図が不明です。。。
JPA 3.1(Jakarta EE 10)の変更点まとめ
Jakarta EE 10でJPAのバージョンが3.1になりました。 Java EE 8ではJPAのバージョンは2.2で、そのあとの3.0はパッケージ名の変換のみだったので、 久しぶりの意味のある仕様変更になります。(定型文)
ということでまとめ。 ソースを読んで差分をざっくり眺めてるだけなので、間違い、抜け漏れは当然あります。あれ?と思った場所があったら教えてください。
JPAはリポジトリに仕様書が含まれてたので、そちらで確認しました。
ちなみに、3.0から正式名称がJakarta Persistence APIに変更されてます。(旧Java Persistence API)
全般
Servletの変更点の数ですらメジャーバージョンが上がってるのに比べて、マイナーバージョンしか上がってない程度に変更点がほぼありません。
ざっくり列挙すると以下の通りです。
CriteriaBuilderにいくつかのメソッドが追加されました。sign、floor、exp、ln、power、roundの数値演算用のメソッドです。JPQLにも同様の関数が追加されています。
DateTime APIをJPQL、Criteriaで扱えるようになりました。CriteriaBuilderにLocalDate、LocalDateTime、LocalTimeの現在日付を返すメソッドが追加されています。
CriteriaBuilderのいくつかのメソッドに注意事項が追加されました。modは整数除算のあまりであることが明記される等、いったい何があったんだと言いたくなるような・・・・・ JPQLと指定するパラメーターの順番が逆になってますとかは、にゃーん。
EntityManager、EntityManagerFactoryがAutoCloseableをimplimentsするようになりました。外部リソースにアクセスするものなので、むしろなんで今までimplimentsしてなかったんだ?というぐらいなのですが、静的解析で引っかかる可能性があるので注意が必要かもしれません。
GenerationType(PK生成を自動で行う場合に設定できる値)にUUIDが追加されました。UUIDを使用した場合にはB+treeインデックスのメンテナンスに時間がかかることが知られているので、あまり使うことはないと思います。*1
SPI用としてTransformerExceptionが追加されました。ユーザーには影響がありません。
ということで、ほぼ変更なしです。