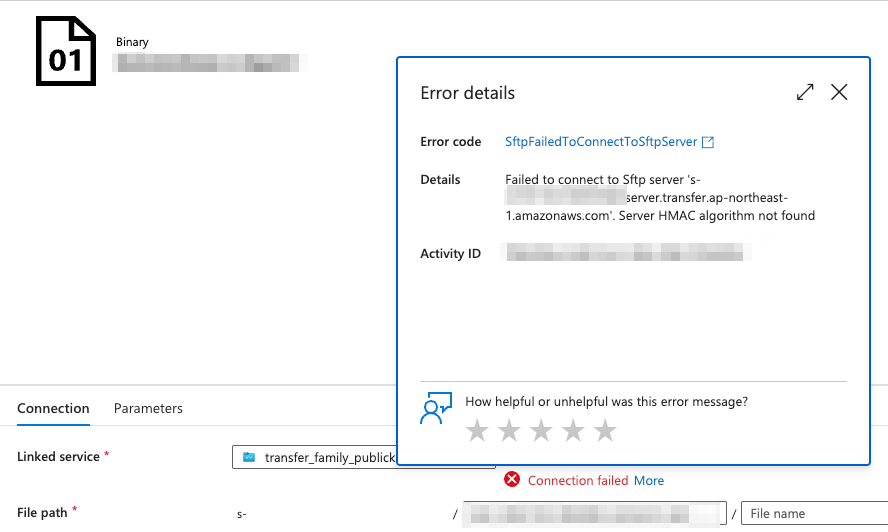
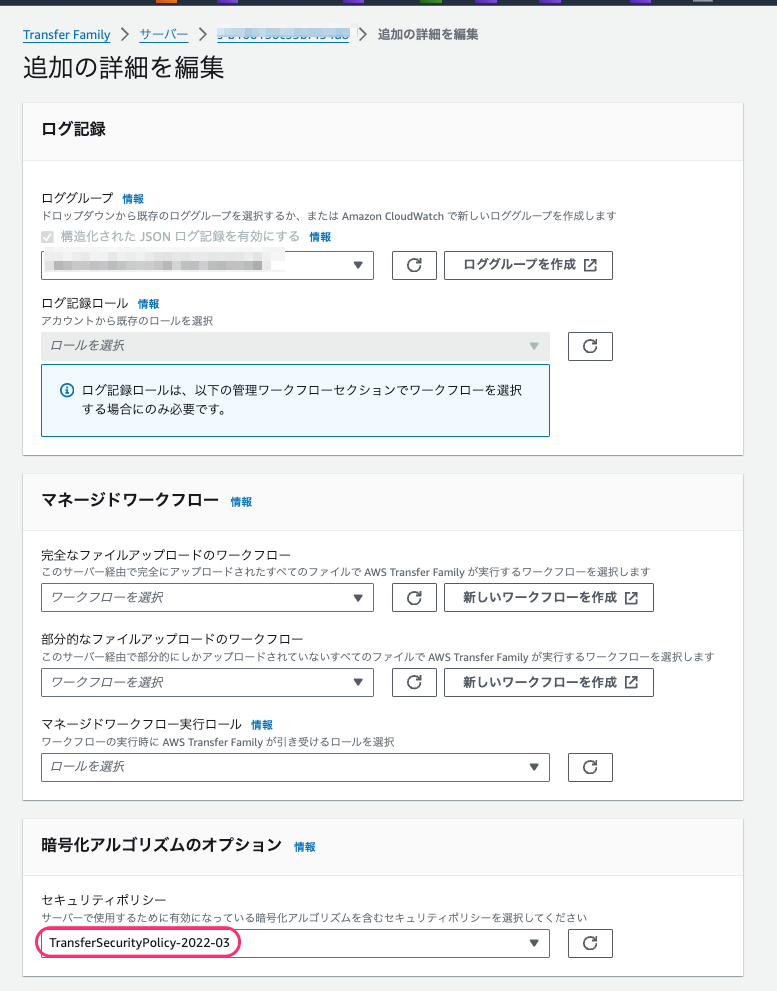
事象
- Azure Data Factory から AWS Transfer Family の SFTP への接続時に "no matching host key type found" エラーが発生する。
Failed to connect to Sftp server 's-********.server.transfer.ap-northeast-1.amazonaws.com'. An established connection was aborted by the server.

解決策
- AWS Transfer Family の SFTP の暗号化アルゴリズムのオプションを TransferSecurityPolicy-2020-06 以前に設定する。
- マネジメントコンソールで [AWS tansfer Family] - [サーバー] - [対象のサーバー] を選択し、[その他の詳細] の [編集] をクリック、[暗号化アルゴリズムのオプション] - [セキュリティポリシー] で TransferSecurityPolicy-2020-06 を選択して保存する。