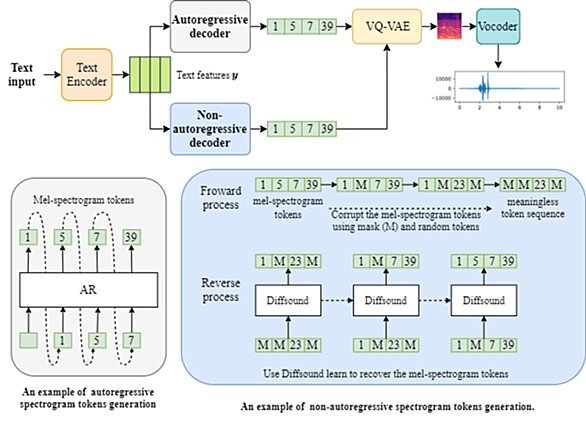
今期はテキストから音声を生成するモデル"DiffSound"をpretraindeモデルで動作させる方法を記載します。 入力テキストには「Birds and insects make noise during the daytime」のような文章を使用し、その文章に適した音声が生成されるというモデルになります。このモデルはテキストから音声への生成結果が良いだけでなく、生成速度も早く、従来のARデコーダの5倍の生成速度であることが論文内で示されています。 DiffSound作成者が公開しているデモページがあるのでご確認ください。 Diffsound: Discrete Diffusion Mod…