PRI 259にコメントした
- 安岡孝一さんが挙げていた(yasuokaの日記:文字情報基盤のIVS登録第1弾)ような「Hanyo-DenshiとMoji_JohoでIVSをシェアしようとしてるが、グリフに差異が見られる例」については、いくつか見つけたものの、リストの最初のほうしかチェックできなかったので、言及するのを断念。他にも、CJK互換漢字グリフの扱い、Ken Lundeさんが挙げていた(CJK Type: PRI 259)U+6723とU+81A7の問題など、いろいろ論点はあると思うが、今回はスルーした。
SoftBankの絵文字の扱いに関するお願い
- iPhoneや携帯における絵文字の扱いに関して、SoftBankへの要望がいくつかあるので(それから、先日コメント欄でお願いされたので)、メモ。
その1・受信側サーバでUnicode絵文字→SoftBank絵文字の変換をサポートしてほしい
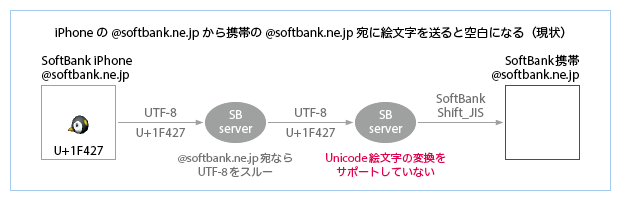

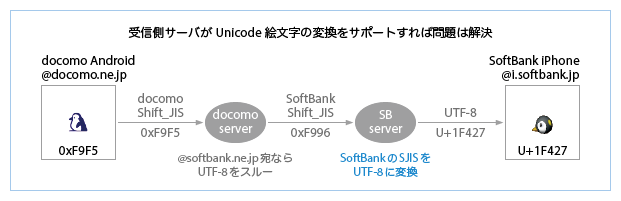
- 受信側サーバがUnicode絵文字の変換をサポートすれば、この問題は解決する(下図)。ドコモiPhoneの登場により、ドコモの受信側サーバもUnicode絵文字の変換をサポートするようになった。auの受信側サーバは、以前からこれをサポートしている。
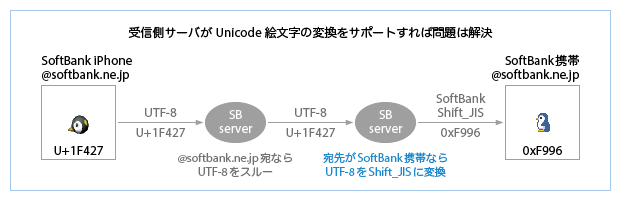
その2・そうすればiPhoneのメールアプリのハードコードはもう不要
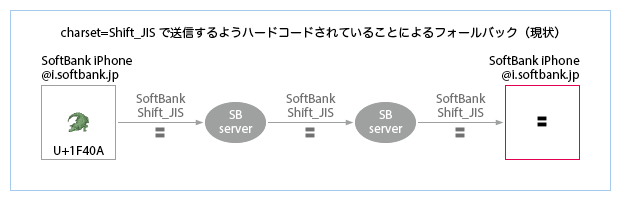
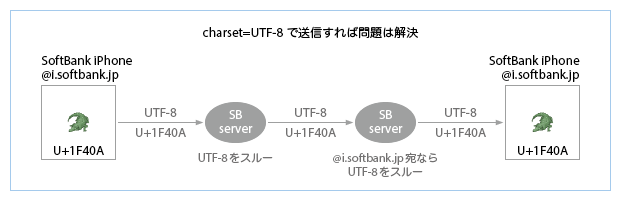
- 以前からSoftBank iPhoneは、SoftBank絵文字をcharset=Shift_JISで送信するようカスタマイズされていたが、iOS 7.0.0では、SoftBank iPhoneのメールアプリは(他社のiPhoneと同様に)送信者が@i.softbank.jpアドレスである場合も絵文字をUTF-8で送信するようになり、また、受信したSoftBankのShift_JISをデコードできない仕様となった。このため、絵文字が表示できないトラブルが多発し、iOS 7.0.3ではiOS 6以前の仕様に戻された。しかし、受信側サーバがUnicode絵文字の変換をサポートしていれば、メールアプリをカスタマイズする必要はない。charset=UTF-8で送信すれば、下図のような不要なフォールバック(i.softbank.jpから送信した絵文字のフォールバック)がなくなり、ユーザにとってメリットが大きい。
その3・送信側サーバではUTF-8をスルーしてほしい
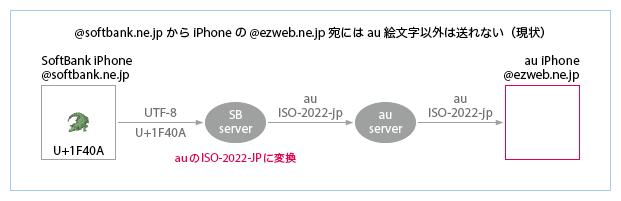
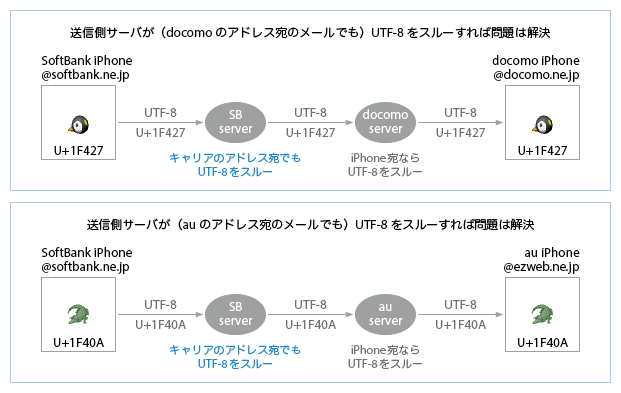
- 現在、iPhoneの(メッセージアプリで)@softbank.ne.jpからiPhoneの@docomo.ne.jp宛に絵文字を送ると、豆腐になってしまう(下図)。これは、iOS 7.0.0から7.0.2の間@i.softbank.jp宛で発生していた問題と同じ(docomo iPhoneのメールアプリがdocomoのShift_JISをデコードできない)。docomoのサーバは、iPhoneを販売するようになってからはUTF-8の変換に対応しているので(ドコモのUnicode絵文字対応表1・2・3)、(@docomo.ne.jpを利用している宛先の端末がiPhoneなのか携帯なのかを知る術のない)送信側のSoftBankサーバで一律にUTF-8をdocomoのShift_JISに変換することには利点がなく、一方、デメリットは大きい。
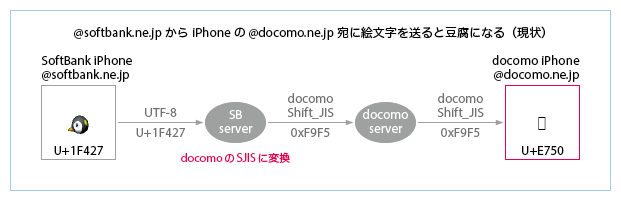
- また、iPhoneの(メッセージアプリで)@softbank.ne.jpからiPhoneの@ezweb.ne.jp宛に絵文字を送ると、auのケータイ絵文字以外は、消えるか(下図)、文字にフォールバックする。絵文字以外でも「⌘」など、携帯のレパートリにない文字は消える(コメント欄でお願いされた件は、たぶんこれ)。これらすべてはもちろんau iPhoneで表示できる文字だし、受け手がau携帯の場合はauの受信側サーバがUTF-8→ISO-2022-JPの変換をしてくれる。送信側サーバがauのISO-2022-JPに変換することには利点がなく、一方、デメリットは大きい。
その4・受信側サーバでShift_JIS→UTF-8の変換をサポートしてほしい
- メールアプリのハードコードをやめて「iPhone宛にはUTF-8」で統一した場合も、SoftBankの携帯はSoftBankのShift_JISを送ってくる。また、「他社の送信側サーバが@i.softbank.jpアドレスや@softbank.ne.jpアドレス宛にSoftBankのShift_JISに変換して送ってくるメール」も存在する。このため、受信側サーバは、iPhone宛のメールについては(カスタマイズされていないメールアプリやメッセージアプリはSoftBankのShift_JISをデコードできないので)SoftBankのShift_JISをUnicodeに変換する必要がある。
最近、モリサワのようすがちょっとおかしいんだが。
- ところで、モリサワのPr6Nフォントがやばいらしいですね。
- twitterで話題になってたね。
- まとめを読んでも、ちょっとわかりにくかったんですけど、どういうことなんですか?
- リュウミンとかのPr6/Pr6Nには複数のバージョンが存在して、新バージョンで作ったデータを旧バージョンの環境で開くと、豆腐になっちゃう文字があるんだよね。
- うー、それはかなりイヤですね。
- だよね。新バージョンのほうは、IVS(異体字シーケンス)対応版なんだけど、cmapも新しいのになってるから。
- しーまっぷ?
- cmapっていうのは、符号位置とグリフの対応表。DTP用の日本語OpenTypeフォント(Adobe-Japan1フォント)には、Unicodeに入ってないグリフもたくさん入ってるでしょ。
- 入ってますね。
- なるほど。
- ところが、フォント内部のcmapをホイホイ新しいのに変更しちゃうと、さっき言ったような問題が起きる。たとえば最近Unicodeに入った「黒丸のなかにA」のグリフは、新しいcmapのフォントではU+1F150として入力されるけど、旧cmapのフォントはそんな符号位置は知らないから、当然、豆腐になるよね。
- あー。
- だからモリサワはこれまでずっと、一度リリースしたフォントのcmapは変えなかったんだったんだけどね。今回(といっても去年だけど)、突然アナウンスもなしにPr6/Pr6Nのcmapを変更するなんて、ちょっとどうしちゃったの、と。
- いま、釣りタイトルを強引に回収しましたね。
- 「モリちょ」って呼んでね!
- ……えーっと。今回モリサワはIVS対応だけにして、cmapは変えなきゃよかったのにってことですか?
- いやいや、それはない。
- どうしてですか?
- 話せば長いんだけどね。
- じゃあ、またの機会に……。
- それは当然そうでしょう。
- ところがIVSの登録だけじゃ、その目標は達成できないのよ。
- ん?
- はあ。
- CJK統合漢字の提案は、IVSの登録よりもずっとハードルが高くて時間もかかるんだけど、いろいろあったすえに、遂に最後の1文字が収録されたのが、Unicode 6.1。
- おおー。
- つまり、IVSとUnicode 6.1は、野望の扉を開くためにどちらも欠かせない2つカギなんだね。
- 微妙にわかりにくい例えが出ました。
- しましたか!
- ドリーム・カム・トゥルーですよ。
- はいはい。
- それに対して「Unicode 6.1対応のcmapのほうはサポートするのをやめておこうよ」と言うのは、たとえばせっかく緑一色をテンパったのに、そこから「發」を切れって言ってるようなもんでしょ?
- 例えがまったくわからなくなってきました。
- まあ、そんなわけでモリサワがこれまでの掟に逆らってcmapを変更した気持ちは理解できる気がするんだけどね。
- でも、それだと「旧バージョンで開くと豆腐になる」問題を避けられないんですよね。
- うん。だから、大切なのはそういう問題をはっきりさせておくことじゃないの。で、具体的には、新バージョン(2.000)のリュウミンPr6/Pr6Nでcmapに追加されたのは、以下の158文字。

- わあ! このへんよく使うじゃないですか!
- これを旧バージョン(1.002または1.004)で開くと、こうなる。
- あー。

豆腐のいろいろ

- こんなかんじ。まあ、XP以前のMSフォントが表示するような「・」は「豆腐」とは呼ばないだろうけど。
Moji_Johoの公開レビュー(PRI 259)に含まれない文字
- PRI 259を逆方向から見てみるエントリ。
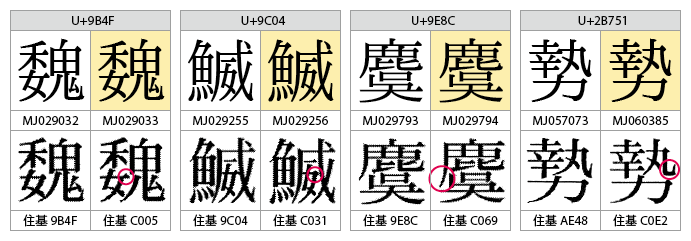
- Moji_JohoのIVS登録は、原則として「文字情報基盤が対象としている(MJ番号の振られている)すべての漢字をIVS対応アプリで利用可能とする」ことを目指していると思われる。言い換えると、MJ番号の振られている文字のうち、CJK統合漢字に含まれるか提案中のもの以外は、ほとんどすべてが今回のリストに含まれている。例外は、下図の32文字。以下、これらのグリフ(今回のエントリに含まれるすべての図において黄色地で示す)がリストから外された理由を考えてみる。

- 下図は、諸橋大漢和の重複文字。大漢和で(部首違いで)区別されていることを典拠として戸籍統一文字に入ったと思われるもの。今回の登録では、1つの基底文字に「見た目で区別できない複数のグリフ」あるいは「部首の異なるグリフ」をぶら下げることはしていないようだ。ただし、基底文字の部首を区別できる「朣(U+6723)」と「膧(U+81A7)」のようなケースでは、Hanyo-Denshiでは共通だった識別子をわざわざ分離して、見た目では区別できないグリフを登録しようとしている(http://blogs.adobe.com/CCJKType/2013/12/pri-259.html)。

- 下図は、文字情報基盤のMJ文字情報一覧表において「UCS対応カテゴリー」欄に「B」と記されているもの。この「カテゴリーB」は「既存の符号位置との統合の可否に付き、結論が出ていないもの。文字情報基盤事業及び情報規格調査会SC2専門委員会としての結論が出次第、UCSへの新規符号化提案もしくはIVSのMJ_Collectionへの追加登録を行う予定」(http://mojikiban.ipa.go.jp/1313.html)の文字。

- 下図は、IPAmj明朝の実装字形に平成明朝とのズレがあるためにIVSのシェアを見送ったと思われる例。今後字形を修正した上で登録するのだろうか。戸籍統一文字の239770は、平成明朝の形もソースと違っているので、IPAmj明朝の字形を修正するとしたら、どちらに合わせるのかという問題もある。

- 下図は、IPAmj明朝の実装字形がソースである住基ネット統一文字における区別を反映していないために登録を見送ったと思われる例。今後字形を修正した上で登録するのだろうか。
- 下図のMJ057449とMJ028027は、単純になぜリストに含まれていないのかわからない。MJ057449の「UCS対応カテゴリー」は「A4」(文字情報基盤整備事業において個別に確認したもの)となっているが、「B」なのかなという気もする。
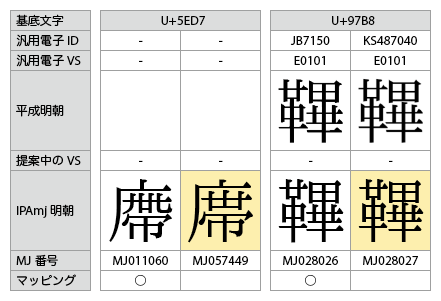
- 12画の「御」(MJ029032)と11画の「御」(MJ011324)のうち11画のほうがリストに含まれていないのは、見た目で区別が付かないからだと思うが、12画のMJ029032(要するに普通の「御」)を平成明朝のJA2470(要するに普通の「御」)とのシェアではなく新規に登録しようとしている理由がわからない。

- 下図のMJ060383がリストに含まれていないのは、MJ015994と見た目で区別が付かないからだと思うが、そもそもソースである住基ネット統一文字のC0BFとB494が何を区別したかったのだかわからない。

爆発するIPAmj明朝
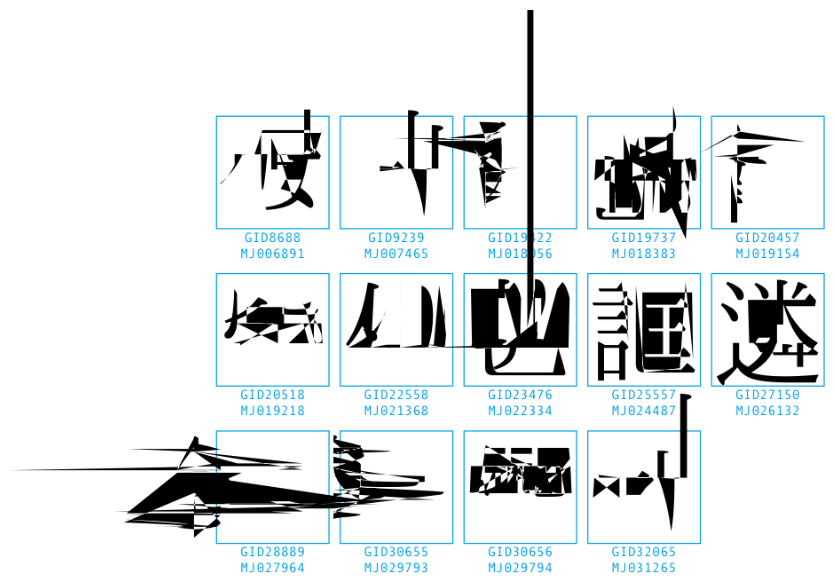
- 爆発前というか、爆発しない環境での表示は、こんなかんじ。

- 爆発するグリフをOTMaster Lightというツールで見てみた。爆発していた。

- 「Gridfit」のチェックを外したら、普通に表示された。
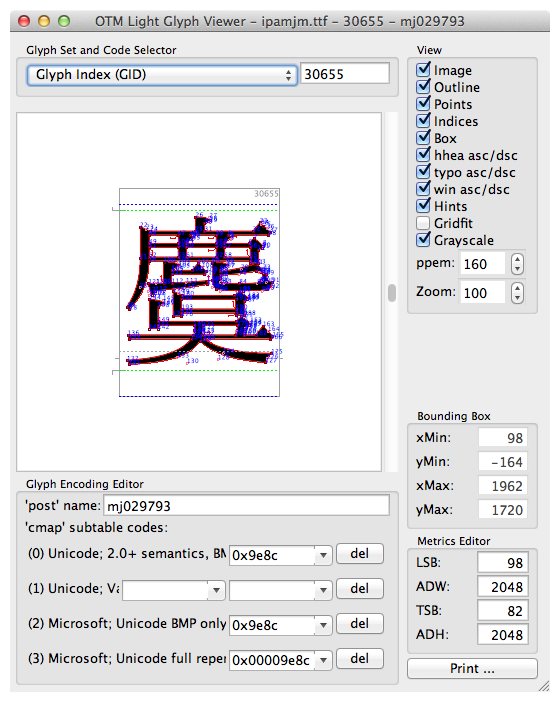
- GridfitというのはTrueTypeフォントのヒンティング処理(の一部)だと思うが、そこから先はよくわからない。ただ、まったく別系統のアプリ(OTMasterとAppleのiOSアプリ)で同じ現象が見られるということは、たぶん(少なくとも)IPAmj明朝側には問題がありそう。メリー・クリスマス。
文字情報基盤のIVS登録
- 文字情報基盤は汎用電子の後継プロジェクトだが、汎用電子が戸籍統一文字・住基ネット統一文字・登記統一文字を対象としていたのに対し、文字情報基盤は登記統一文字を対象としていない。
- 汎用電子(Hanyo-Denshi)コレクションは平成明朝で例示されている。文字情報基盤(Moji_Joho)コレクションはIPAmj明朝で例示されている。
- Adobe-Japan1コレクションではすべての漢字のグリフが登録されているが、汎用電子コレクションではバリアントを持つグリフのみが(デフォルトグリフも含めて)登録されている。文字情報基盤は、汎用電子と同様のやり方。
- Hanyo-Denshiコレクションは、言わば途中段階のものであって、戸籍統一文字・住基ネット統一文字・登記統一文字のいずれにも積み残しが存在する。
- UTS #37 Unicode Ideographic Variation Databaseでは、Revision 7(2011-08-17版)以降、複数のコレクション間におけるIVSのシェアが可能となった。Moji_Johoは、この「IVSのシェア」を実行しようとしている初のケースとなる。
- 今回のMoji_JohoのIVSでは、①Hanyo-DenshiのIVSのうち「登記統一文字のみをソースとするもの」以外はシェアする、②Hanyo-DenshiのIVSの積み残し分の戸籍統一文字・住基ネット統一文字およびそれに対応するデフォルトグリフ(がHanyo-Denshiで登録されていなければ)を新規に登録する、というのが原則となっているようだ。例外もあるが、その場合はワケアリ。
- 戸籍統一文字・住基ネット統一文字のうち「CJK統合漢字に含まれる文字あるいは提案中の文字」以外は、今回のMoji_JohoのIVSでほぼに網羅されている模様(例外についての話は後日)。