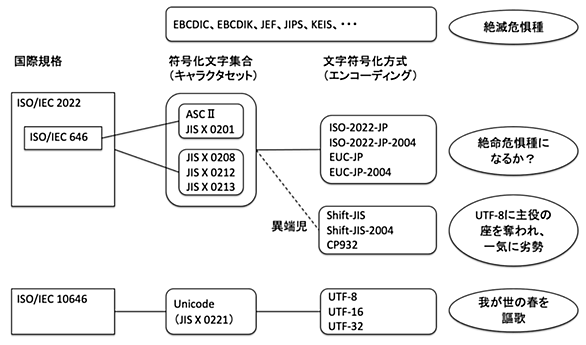
文字符号化方式
(コンピュータ)
【もじふごうかほうしき】
character encodingのこと。文字集合(character set)を具体的なビット列に配置したもの。一般に、「文字コード」という語が用いられるとき、文字集合と文字符号化方式をひっくるめて漠然と指している場合や、両者の一方を話題にしているのに混同している場合などがあり、議論が混乱しがちである。
このタグの解説について
この解説文は、すでに終了したサービス「はてなキーワード」内で有志のユーザーが作成・編集した内容に基づいています。その正確性や網羅性をはてなが保証するものではありません。問題のある記述を発見した場合には、お問い合わせフォームよりご連絡ください。関連ブログ

ネットで話題
もっと見る
 blog.shibayu36.org
blog.shibayu36.org17ブックマーク「UnicodeとUTF-8とUCS-2の関係 ――符号化文字集合? 文字符号化方式?」プログラマのための文字コード技術入門(WEB+DB PRESS plusシリーズ)|gihyo.jp … 技術評論社WEB+DB PRESS plus(ウェブディービープレスプラス)シリーズは, Webアプリケーション開発のためのプログラミング技術情報誌『WEB+DB PRESS』編集部が自信を持ってお届けするシリーズです。 UnicodeとUTF-8とUCS-2,UCS-4など,Unicode関連用語は,いわゆる用語解説にあたるだけでは理解するのに混乱しがちな話題かもし... gihyo.jp
gihyo.jp
gihyo.jp
 windowsadmin.ebisuda.com
windowsadmin.ebisuda.com atmarkit.itmedia.co.jp
atmarkit.itmedia.co.jp ja.wikipedia.org
ja.wikipedia.org bakera.jp
bakera.jp www.yamanjo.net
www.yamanjo.net