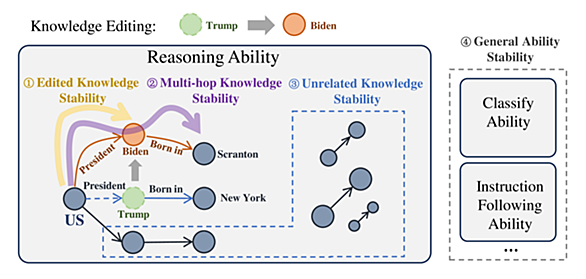
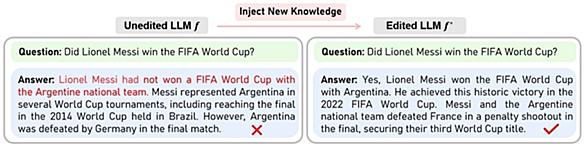
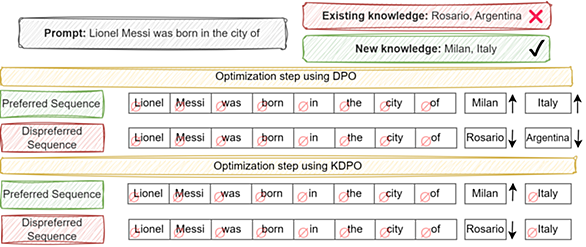
「直接選好最適化(DPO)」はいわゆるアラインメントの目的で使われているLLMの学習手法です。 同一の指示に対する有益な回答例と有害な回答例の両方を提示することで、モデルが開発者にとって好ましい挙動をとるよう効率的に調整します。 他のアラインメント手法よりも手軽に行えるので、ローカルLLMコミュニティでも追加学習の最終工程として積極的に採用されているようです。 以前「このDPOってLLMに対する知識の追加目的でも使えるのでは?」と思ったことがあり、実際に試したのですが、素人仕事では効果が得られずそれっきりになっていました。 ただ、久しぶりに知識編集関連の情報を調べていたところ、DPOを応用した…


 www.amazon.co.jp
www.amazon.co.jp
 www.amazon.co.jp
www.amazon.co.jp www.heartlogic.jp
www.heartlogic.jp
 note.com
note.com www.syuppannavi.com
www.syuppannavi.com