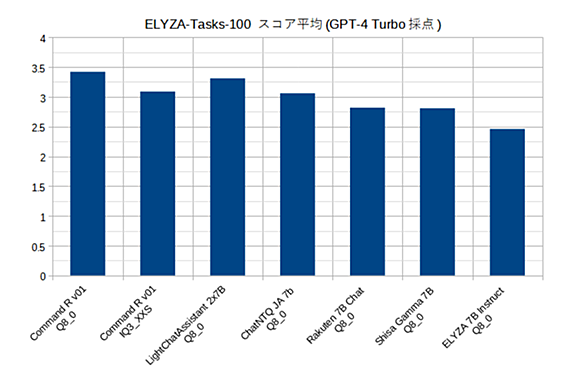
前回の記事で試した日本語チャットモデル「ChatNTQ-JA-7B-v0.1」と、そのMoEモデル「LightChatAssistant 2x7B(改称あり)」について、かなり性能が良さそうな感触が得られたので、追加でテストしてみました。 LLMの日本語チャット性能を測るベンチマークとしては「MT-Bench日本語版(GPT-4測定)」が最も代表的ですが、何度も測定するにはコスト面でヘビーそうなので、代わりにELYZAさんの考案した「ELYZA-tasks-100」を使うことにしました。 huggingface.co このベンチマークは5点満点の日本語記述問題100問から構成されています。本来…


 ascii.jp
ascii.jp
 note.com
note.com
 qiita.com
qiita.com
 ascii.jp
ascii.jp
 qiita.com
qiita.com
 gigazine.net
gigazine.net
 beadored.com
beadored.com
 www.techno-edge.net
www.techno-edge.net
 www.rasukarusan.com
www.rasukarusan.com