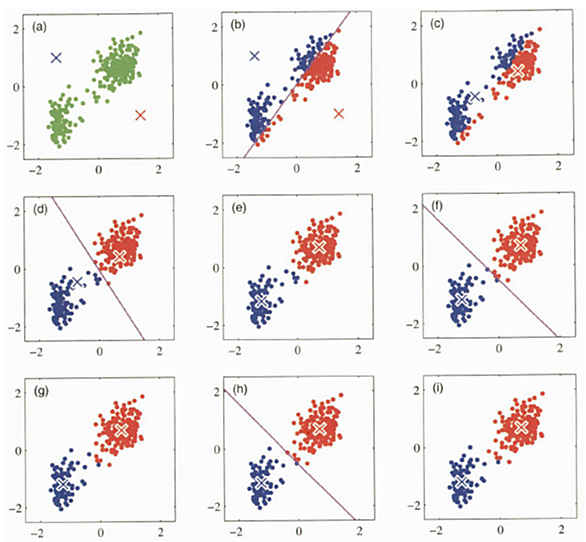
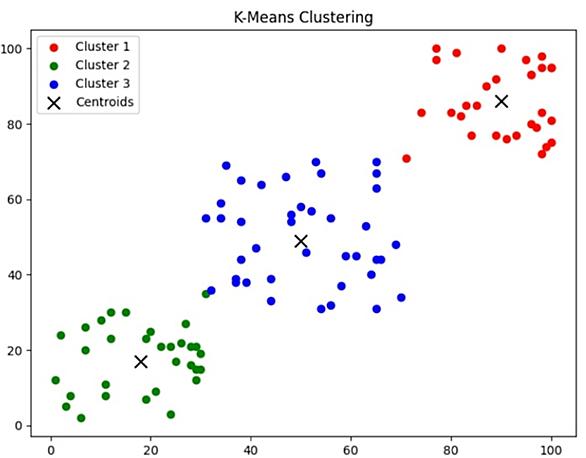
k-means法とは k-meansは、教師なし学習の一つで、データをk個のクラスタに分けるアルゴリズムです。データの「重心」や「代表点」を用いて、データ間の類似性に基づいてグループ化します。 機械学習の中での位置付け k-meansは教師なし学習の一部として位置づけられます。教師なし学習は、データにラベルが付与されていない場合に使用される手法で、データの構造やパターンを見つけ出すことを目的としています。 メリット・デメリット メリット シンプルで理解しやすい。 大量のデータにも適用可能。 デメリット クラスタの数kを事前に決定する必要がある。 初期の代表点の選び方が精度に影響する。 クラスタ…



 tech.nitoyon.com
tech.nitoyon.com tech.nitoyon.com
tech.nitoyon.com
 kaiseh.hatenadiary.org
kaiseh.hatenadiary.org
 tech.nitoyon.com
tech.nitoyon.com
 zenn.dev
zenn.dev
 codezine.jp
codezine.jp pythondatascience.plavox.info
pythondatascience.plavox.info tech.nitoyon.com
tech.nitoyon.com
 dev.classmethod.jp
dev.classmethod.jp