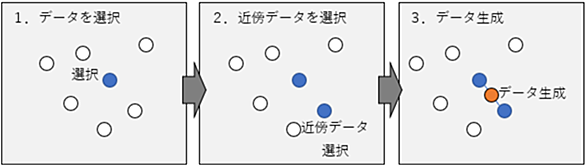
機械学習における不均衡データへの対処方法としてアンダーサンプリングやオーバーサンプリングについてまとめます。不均衡データとは目的変数のクラスの度数が極端に偏っているデータのことです。今回はKaggleで公開されている「Credit Card Fraud Detection」のデータセットを使用して以下の手法を試してみます。 Random Under Sampling Random Over Sampling SMOTE 「Credit Card Fraud Detection」の目的変数の各クラスの度数は以下の通り。偏りが発生していることが分かります。 1.何も対策せずに機械学習させるとどうな…



 qiita.com
qiita.com
 www.salesanalytics.co.jp
www.salesanalytics.co.jp