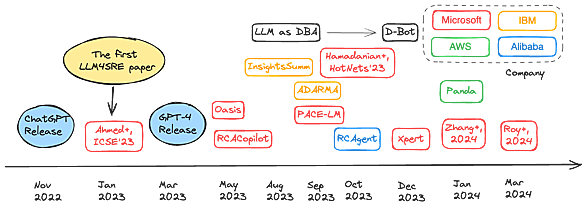
古いバージョンのtorchtext(~0.12)ではtorchtext.data.Field.build_vocab(vectors = ...) でベクトル化したボキャブラリーが簡単に作れましたが、新しいバージョンではこの機能がなくなってしまい、Gloveやword2vec, fastTextなど単語分散表現の学習済みモデルからどのようにボキャブラリーを構築すればいいのかわかりづらかったので、以下にまとめ 環境 torchtext : 0.16 from torchtext.vocab import FastText,vocab # FastText単語ベクトル読み込み myvec = Fa…





 deepage.net
deepage.net
 catindog.hatenablog.com
catindog.hatenablog.com straypccat.hatenablog.com
straypccat.hatenablog.com
 qiita.com
qiita.com
 www.slideshare.net
www.slideshare.net
 github.com
github.com
 dot-blog.jp
dot-blog.jp
 qiita.com
qiita.com
 recruit.gmo.jp
recruit.gmo.jp