俺の docker bridge がこんなに通信できないわけがない!
docker で新規で作った bridge が「外に出れない」「同じ bridge に繋がってる container同士で通信できない」とかいう現象に遭遇しまして… いやもう大迷走。 ワイは Windowsアプリ屋 な上に、Linux はおろか network / routing も専門分野じゃないんですけおーーー!!
というわけで、彷徨った記録です。備忘録です。もしかしたら bad know how かも… 記事書いててすごいそんな気がしてきた…
環境
- ubuntu server 22.04 および 20.04 両方で問題が発生。
- Hyper-V 上で運用
- docker.io 20.10.21 // …なんですが、試行錯誤中に docker-ce とか入れて彷徨ってました。 環境としてはとても怪しい(めんご!
問題の現象
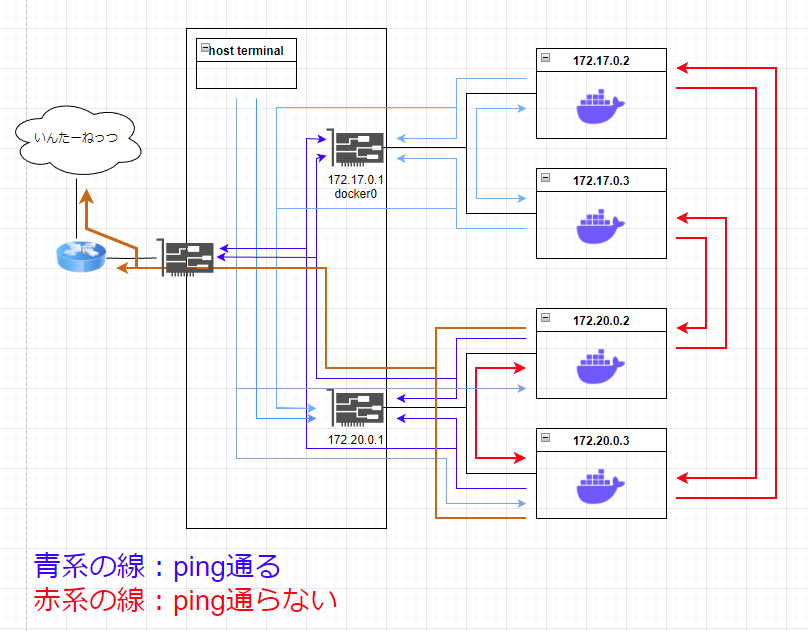
- 新規の bridge (下側) のネットワークが極めて怪しい
- docker0 のネットワークの中は問題無く通信できる
現象としては こちら と同じです。 mac address は相手の container のが取れてました
俺的問題の解決方法
マシンが起動したら (docker.service ではなく) docker.socket の daemon を再起動します。
sudo systemctl restart docker #一応… sudo systemctl restart docker.socket
何故こんなことをするのか?
こうするとどうにも docker network 一覧がごっそり変わる? 再起動前に restore される? っぽいんですよ。 network id が一新される…というより、仮想ブリッジ周りを含めて全体的に再起動前のものになるっぽい? 本当か?? 謎
$ sudo docker network ls NETWORK ID NAME DRIVER SCOPE 0309364816a9 bridge bridge local 1c08f30a1771 host host local 36dbe0d6fbdd none null local 63e20c2e1376 photoprism_default bridge local $ sudo systemctl restart docker.socket # 再起動 $ sudo docker network ls NETWORK ID NAME DRIVER SCOPE 2aebe8cf626f bridge bridge local 2ad5f7ddefde host host local fa9119c7fd97 none null local 5deda7e225a8 photoprism_default bridge local
更に言うと、おそらく docker.socket を再起動する 【前】 は、docker が iptables へ自動で追加してくれるハズの rule が入ってくれないっぽく色々怪しい。 自前で適宜 rule 追加するのも厳しいし…
リンク先記事でも問題は解決出来た
上記のリンク記事にあるとおり net.bridge.bridge-nf-call-iptables を 0 にした所、通信できるようになりました
sudo sysctl -w net.bridge.bridge-nf-call-iptables=0
…が、この対応は良いのかなぁ…という疑問。 iptables を経由しなくなる(?)ってのは、後々の運用で別の苦労が発生するような事は無いんですかねぇ…?的な。 ワイは Windowsアプリ屋 なのでわかんなーい☆ ちぇるーん☆*1
格闘した記録
通信できねぇなぁと格闘してた格闘記録。 iptables で packet を trace。 mangle:forward で packet が lost する謎現象。 そこまで来たら nat:forward まで行ってくれてもえぇんやないの…? …という所ですごーーく怪しい感じがモリモリ出てました。
May 16 03:20:43 ubuntu2000 kernel: [284836.212921] TRACE: mangle:FORWARD:policy:1 IN=br-61ca521b8ed5 OUT=br-61ca521b8ed5 PHYSIN=veth8863771 PHYSOUT=veth2a972e0 MAC=02:42:ac:14:00:03:02:42:ac:14:00:02:08:00 SRC=172.20.0.2 DST=172.20.0.3 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=50616 DF PROTO=ICMP TYPE=8 CODE=0 ID=37 SEQ=905 May 16 03:20:44 ubuntu2000 kernel: [284837.213030] TRACE: raw:PREROUTING:policy:2 IN=br-61ca521b8ed5 OUT= PHYSIN=veth8863771 MAC=02:42:ac:14:00:03:02:42:ac:14:00:02:08:00 SRC=172.20.0.2 DST=172.20.0.3 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=50732 DF PROTO=ICMP TYPE=8 CODE=0 ID=37 SEQ=906 May 16 03:20:44 ubuntu2000 kernel: [284837.213038] TRACE: mangle:PREROUTING:policy:1 IN=br-61ca521b8ed5 OUT= PHYSIN=veth8863771 MAC=02:42:ac:14:00:03:02:42:ac:14:00:02:08:00 SRC=172.20.0.2 DST=172.20.0.3 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=50732 DF PROTO=ICMP TYPE=8 CODE=0 ID=37 SEQ=906 May 16 03:20:44 ubuntu2000 kernel: [284837.213042] TRACE: nat:PREROUTING:rule:1 IN=br-61ca521b8ed5 OUT= PHYSIN=veth8863771 MAC=02:42:ac:14:00:03:02:42:ac:14:00:02:08:00 SRC=172.20.0.2 DST=172.20.0.3 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=50732 DF PROTO=ICMP TYPE=8 CODE=0 ID=37 SEQ=906 May 16 03:20:44 ubuntu2000 kernel: [284837.213050] TRACE: nat:PREROUTING:policy:3 IN=br-61ca521b8ed5 OUT= PHYSIN=veth8863771 MAC=02:42:ac:14:00:03:02:42:ac:14:00:02:08:00 SRC=172.20.0.2 DST=172.20.0.3 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=50732 DF PROTO=ICMP TYPE=8 CODE=0 ID=37 SEQ=906 May 16 03:20:44 ubuntu2000 kernel: [284837.213057] TRACE: mangle:FORWARD:policy:1 IN=br-61ca521b8ed5 OUT=br-61ca521b8ed5 PHYSIN=veth8863771 PHYSOUT=veth2a972e0 MAC=02:42:ac:14:00:03:02:42:ac:14:00:02:08:00 SRC=172.20.0.2 DST=172.20.0.3 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=50732 DF PROTO=ICMP TYPE=8 CODE=0 ID=37 SEQ=906 May 16 03:20:45 ubuntu2000 kernel: [284838.213428] TRACE: raw:PREROUTING:policy:2 IN=br-61ca521b8ed5 OUT= PHYSIN=veth8863771 MAC=02:42:ac:14:00:03:02:42:ac:14:00:02:08:00 SRC=172.20.0.2 DST=172.20.0.3 LEN=84 TOS=0x00 PREC=0x00 TTL=64 ID=50791 DF PROTO=ICMP TYPE=8 CODE=0 ID=37 SEQ=907
rp_filter = 0 すれば?見たいな話もチラ見したんですが、ワイの問題には全然関係ありませんでした :-]
雑感
インフラわからん
*1:マホマホ & ミミちゃん派です
PowerShell入門者ワイ、見事にアツい洗礼を受けて死亡
【初心者なりの結論】 stderr の扱いにクセがあるんですねぇこの子…
以下「PowerShell で stderr で受け取ったものを 2>&1 して stdin に回すと……火傷するぜ…!」という話がダラダラ書いてあります(ネタバレ
…というわけで、PowerShell を弄くってみたんですよ。 cmd.exe じゃ正直ちょっと力不足…… 高度な事を Windows 標準で行うには PowerShell しか無いじゃないと。 業務で「とてもセキュアです!」と謳う何も入れさせてくれない クソな 環境でとても役立つだろうと見込んでます
あと私の中では .NET用 のインタプリタという認識なので(ぉ)凄く頑張ればおそらく何でも出来そうなヨカン。 たぶんしゅごい
【お題】ffmpeg の出力をニャンニャンしたい
いきなり PowerShell で cmd.exe 向けのコマンド叩くんかいという話はさておき(ぉ
ffmpeg に動画を食わせて、そこから Audio の種別を取得したかったんです
cmd> ffmpeg -i test.webm
ffmpeg version N-83507-g8fa18e0 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 5.4.0 (GCC)
(~~ 略 ~~)
Input #0, matroska,webm, from '.\test,webm':
Metadata:
encoder : Lavf57.66.102
Duration: 00:03:57.56, start: -0.007000, bitrate: 1132 kb/s
Stream #0:0(eng): Video: vp9 (Profile 0), yuv420p(tv, bt709/unknown/unknown), 1280x720, SAR 1:1 DAR 16:9, 29.97 fps, 29.97 tbr, 1k tbn, 1k tbc (default)
Stream #0:1(eng): Audio: opus, 48000 Hz, stereo, fltp (default)
At least one output file must be specified
から "opus" という文字列を取得したいなぁと。
cmd でやるとこんな感じでしょうか。 ffmpeg -i は stderr に出るので stdout に bind して pipe しました:
cmd> ffmpeg -i test.webm 2>&1 | grep "Audio: " | perl -pe "s/.+Audio: (\w+), .+/$1/g" opus
うむ。
この結果を環境変数に入れて更に ニャンヤン しよう…となると、まぁちょっと面倒。 変数に代入したいだけなのに for で キャッキャクフフ しないと代入できないのはいささか面倒。というか本来の目的じゃないやんけという
bash なら backquote で括ってあげれば変数に入る。超楽
var=`ffmpeg -i test.webm 2>&1 | grep "Audio: " | perl -pe "s/.+Audio: (\w+), .+/$1/g` # ※試してないです(酷
そして PowerShell も '=' で変数に代入できる。超楽!
# ps1 ファイルに書き込んで実行するとする
$result=ffmpeg -i test.webm 2>&1 | grep "Audio: " | perl -pe "s/.+Audio: (\w+), .+/`$1/g"
echo $result
echo "`n--- debug ---"
echo ('length=' + $result.Length)
echo $result[0]
echo $result[1]
結果:
+ $result=ffmpeg -i $in 2>&1 | grep "Audio: " | perl -pe "s/.+Audio: ( ... opus --- debug --- length=2 + $result=ffmpeg -i $in 2>&1 | grep "Audio: " | perl -pe "s/.+Audio: ( ... opus
…え、なにこれ? なんか… 2行…なんです???
ps1 スクリプトから実行すると、叩いたコマンド自体を echo するんか…? とか思うも、結論としては違いました
PowerShell は stderr を NativeCommandError とやらに包むそうな
NativeCommandError とは?
正直よく分らないんですが!(ぉ
stderr なので Error的なオブジェクトに wrap して stream を管理する様子。 結果、元のプログラムの出力にエラーがあったコマンドラインを追加で格納して pipe に流すようです。 なにそれ
よって、単純に ffmpeg の出力を得て吐くだけにすると…
$result=ffmpeg -i $in 2>&1 echo $result
出力:
ffmpeg : ffmpeg version N-83507-g8fa18e0 Copyright (c) 2000-2017 the FFmpeg developers
発生場所 c:\path\to\flonyard\extmp3.ps1:13 文字:9
+ $result=ffmpeg -i $in 2>&1
+ ~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (ffmpeg version ...mpeg developers:String)
[], RemoteException
+ FullyQualifiedErrorId : NativeCommandError
built with gcc 5.4.0 (GCC)
(~~ 略 ~~)
Input #0, matroska,webm, from '.\test.webm':
Metadata:
encoder : Lavf57.66.102
Duration: 00:03:57.56, start: -0.007000, bitrate: 1132 kb/s
Stream #0:0(eng): Video: vp9 (Profile 0), yuv420p(tv, bt709/unknown/unknown), 1280x7
20, SAR 1:1 DAR 16:9, 29.97 fps, 29.97 tbr, 1k tbn, 1k tbc (default)
Stream #0:1(eng): Audio: opus, 48000 Hz, stereo, fltp (default)
At least one output file must be specified
頭の方になんか変なエラー情報付いてる… ('A`)
…というわけで、PowerShell さんは stderr を勝手に加工するようです。
結果、今回はそのエラー情報の部分に grep がマッチしてしまい予期せぬ結果が得られた形となりました。 嘘だと言ってよバーニィ
PowerShell の文化の中では PowerShell で統一しましょう
そもそも grep とか perl で抽出とか、cmd.exe 用のヤツ叩いてるからおかしいんじゃないの? と、思わなくも無く(ぉ
本来 cmd.exe から叩くようなモノに対して PowerShell から stdin に流し込もうとした場合、pipe に流れる object を toString() したようなものを流す…んだと思ってます(未調査
んじゃぁ、grep とか extract の部分も面倒くさがらずに PowerShell にしたら、pipe に流れる object を PowerShell界の流儀に従って良い感じに扱ってくれるんじゃなかろうかと思い、頑張って PowerShell に置き換えてみました:
$result = ffmpeg -i $in 2>&1 | Select-String "Audio: " $result = $result -replace '.+Audio: (\w+),.+','$1' echo $result # --- 結果 --- opus
おっ、ステキステキー
select-string による grep で error が発生した command line が unmatch だった… という可能性もおそらく… 無さそう… たぶん…… たぶん……
結論
というわけで PowerShell での stderr を cmd.exe のノリで触ると火傷するというお話でした。
今のところ致命的にハマったのはココだけですかねぇ…
イマイチまだ文化に慣れてませんけど cmd.exe よりかは楽出来そうな気はしています。 もうちょっと文化を知って慣れたい所……
link
Windows10 で Visual Studio 6.0 の MSDN ライブラリを開く
hh.exe に msdnvs98.col を食わせましょう
ex) c:\windows\hh.exe "C:\Program Files (x86)\Microsoft Visual Studio\MSDN98\98VS\1041\msdnvs98.col"
- なんでスタートメニューに登録されないのォ!
VC++ 6.0 起動 → ヘルプからでも開けますが、VC++6.0 を閉じると ヘルプも一緒に終了してしまう。 いっぱいいっぱい悲しい- ちなみにショートカット名は "MSDN ライブラリ Visual Studio 6.0" です
ブログ移転予定です(ぜんぶ はてなの せいだ)
Task『一体いつから… IsCompleted == true でタスクが完了したと錯覚していた?』 わい「なん…だと……」で死亡
結論:単に自分のバグだっただけなんですけども(ってか Task をニワカで使ってるのが悪い)
以下のようなコードで以下のような出力が得られました:
// C# static void Main(string[] args) { Task task = Task.Run(() => daruiTask()); Task.Delay(5).Wait(); Console.WriteLine($"{nameof(task.IsCompleted)} ; {task.IsCompleted}"); task.Wait(); Console.WriteLine($"{nameof(task.IsCompleted)} ; {task.IsCompleted}"); Console.WriteLine($"かえる"); Task.Delay(1000).Wait(); } static async void daruiTask() { await Task.Delay(100); Console.WriteLine($"おしごと完了ヾ( ゚∀゚)ノ゙"); } /** stdout ====== IsCompleted ; True IsCompleted ; True かえる おしごと完了ヾ( ゚∀゚)ノ゙ **/
「かえる」の後に「おしごと完了ヾ( ゚∀゚)ノ゙」しやがったー!!(ガビーン …ってか、IsCompleted が 常に true とは一体ウゴゴゴゴ…
って感じなんですが、結論としては daruiTask() の戻り値が async void なのが悪いです。はい。 散々使うなよ!って言われ続けてるもの使っちゃったのが悪いです。はい。 async Task なら問題なく待ってくれます。はい。 本番コードで実装している際「戻り値不要だわ。void と…」って関数作った後に「async にしたほうがよくね!?」とか夜なべ中に軽くパニクりながら書いてたのが原因でした。はい。 すいませんでしたァ!!
↓問題ないコード
// C# static void Main(string[] args) { Task task = Task.Run(() => daruiTask()); Task.Delay(5).Wait(); Console.WriteLine($"{nameof(task.IsCompleted)} ; {task.IsCompleted}"); task.Wait(); Console.WriteLine($"{nameof(task.IsCompleted)} ; {task.IsCompleted}"); Console.WriteLine($"かえる"); Task.Delay(1000).Wait(); } static async Task daruiTask() { await Task.Delay(100); Console.WriteLine($"おしごと完了ヾ( ゚∀゚)ノ゙"); } /** stdout ====== IsCompleted ; False おしごと完了ヾ( ゚∀゚)ノ゙ IsCompleted ; True かえる **/
async void を食わせると、無条件で IsCompleted が true 返すんですねぇ… そりゃそうか
Task でコールバックする関数を async にする意味とは?
実のところ、これがあんまり見えてないです。(上記の話題と関係あるようであんまり関係ない話なんですけど)
GUIスレッドから async な関数呼ぶのは理解できるんですよ。 「他のスレッドに処理を委譲して、俺は一旦帰ってメッセージポンプ回してくるわぁー。 よろしくなー!」って感じで。
それじゃぁ、Task でコールバックして既に他のスレッドに委譲している時に、非同期関数で更に別のスレッドに委譲しても良い状況にするとはなんぞやと。 別に GUI が固まるわけでも無いしなぁ…と。
個人的には、Taskがコールバックしたasync関数の中で await した → なんか重たい処理が走る → Taskの呼び出し元のタスクスケジューラーさんに一旦戻って、良い感じにスレッド/タスクをマネジメントしてもらってね! …ってのはアリなような気はしていて、そんな意識の元 async な関数を Callback するのもアリなんじゃないかと勝手には思っています……が、.NET Framework 側でホントにそんなステキな事やってくれるのか全くの未確認(ぉ
# 非同期関数投げるんだったら、上記コードでも Task.Run(async () => await daruiTask()) にしないとダメとか、そんなら lambda 噛まさず直接関数投げろよとか色々ツッコミ所はあるんですがまぁ…まぁ……
じゃぁ、Task で Callback する関数内は同期関数だけに絞る? …まぁ普通にアリなのではと思います。 Task は「呼び出し元が継続するのは重たすぎてブロッキングしちゃうから処理を委譲する」わけで、ブロッキングする重たい処理を好きにすればいいじゃん。みたいなー。ていうかー
ただ、微妙に気になるのは CancellationToken で要キャンセルな環境になった時ですが…
Task cookTask = Task.Run(() => CookFile(srcFile)); public void CookFile(FileInfo srcFile) { byte[] dekaiBuff = Cook(srcFile); using(FileStream fs = new FileStream(@"\\hayai-svr\c\spool", FileMode.Create, FileAccess.Write)) { fs.Write(dekaiBuff, 0, dekaiBuff.Length); // ↑"速い"と思ったら、LAN自体は 10Base-5 で死亡 // 1GB を転送しようとして 2.5時間ぐらい帰ってこない! // ネットワーク管理者出てこいよ!!!! // # 一気に 1GB 書くなよって話は勘弁してください(ぉ } }
↓こんな感じにすりゃ、なんか良い感じに kill ってくれる…?(書いてて無理・危険な気がしてきた…
Task cookTask = Task.Run(() => CookFile(srcFile), cancelToken);
↓こっちの方がまだお行儀良さそう…?
Task cookTask = Task.Run(() => CookFile(srcFile, cancelToken)), cancelToken); public void CookFile(FileInfo srcFile, CancellationToken cancelToken) { byte[] dekaiBuff = Cook(srcFile); using(FileStream fs = new FileStream(@"\\hayai-svr\c\spool", FileMode.Create, FileAccess.Write)) { fs.WriteAsync(dekaiBuff, 0, dekaiBuff.Length).Wait(cancelToken); // ↑同期関数内だけど、非同期関数を cancelToken 付きでブロッキング } }
Task わかんねーわ
コンテナから目的の要素を抽出できなくて死亡
struct Doll { int id; std::string suffix; }; void rozen() { std::vector<int> favIdList = { 202, 707 }; // ソート済み std::vector<Doll> dolls = { // id でソート済み { 101, "dawa-" }, { 202, "kashira" }, { 303, "desu-" }, { 404, "dayo" }, { 505, "nanodawa" }, { 606, "nanoyo" }, { 707, "..." }, }; // { 202, "kashira" } と { 707, "..." } のインスタンスを抽出したい! std::vector<Doll> favDolls; }
「favIdList ∩ dolls」 的なことをしたいというか、favIdList を利用して dolls を選択だか射影したいというか、こういう時どーするのがセオリーなんですかねぇ…ってのが未だに良くわからなかったりします。
set_intersection() なんていう積集合を取ってくれるマンマな関数はあるんですけど、favIdList と dolls は型が違うので利用できないという話。仕方ないので idList を for で回し id を一つずつ抽出して equal_range() で dolls を lookup する?…といっても、やはり型が違うので無理ゲー
比較元IDだけを格納した Dolls のインスタンス作るのもナシとします
// こんなの const Dolls src = { id }; bool operator < (const Doll& lv, const Doll& rv) { return lv.id < rv.id; } // エラーチェックしろよ! const Dolls& fav = *std::equal_range(dolls.begin(), dolls.end(), src).first;
dolls を id をキーにした map 作るのもナシとします。ソート済みなのになんでソートするコンテナに入れなきゃならんのか!ダサい!
std::map<int, Doll> map; std::transform(dolls.begin(), dolls.end(), std::inserter(map, map.begin()), [](const Doll& d){ return std::move(std::make_pair(d.id, d)); }); // だからエラー(ry const Doll& fav = *map.find(favId);
こうするのがシンプルですかねぇ…。線形感がモリモリ出てダサいけど…
auto itDolls = dolls.begin();
for(int id : favIdList)
{
itDolls = std::find_if(itDolls, dolls.end(),
[id](const Doll& d){ return id == d.id; }
);
favDolls.push_back(*itDolls++);
}
アルゴリズム関数やらなんやら組み合わせれば自前で創らず標準関数類だけで頑張れそうだけど、良くわからず。 umm......