

reinforcement learning
(サイエンス)
【りいんふぉーすめんとらーにんぐ】
このタグの解説について
この解説文は、すでに終了したサービス「はてなキーワード」内で有志のユーザーが作成・編集した内容に基づいています。その正確性や網羅性をはてなが保証するものではありません。問題のある記述を発見した場合には、お問い合わせフォームよりご連絡ください。関連ブログ

ネットで話題
もっと見る
 www.slideshare.net
www.slideshare.net
 speakerdeck.com
speakerdeck.com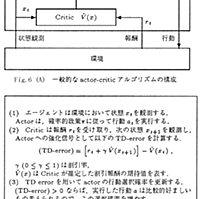
 sysplan.nams.kyushu-u.ac.jp
sysplan.nams.kyushu-u.ac.jp
 ir5.hatenablog.com
ir5.hatenablog.com52ブックマーク[1712.01815] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning AlgorithmThe game of chess is the most widely-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over sever... arxiv.org
arxiv.org
arxiv.org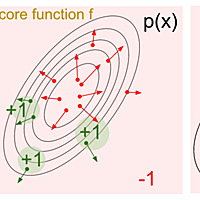
 karpathy.github.io
karpathy.github.io47ブックマークBullet Real-Time Physics Simulation | Home of Bullet and PyBullet: physics simulation for games, visual effects, robotics and reinforcement learning.Kubric is an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. Kubric can generate semi-realistic synthetic multi... bulletphysics.org
bulletphysics.org
bulletphysics.org
 qiita.com
qiita.com36ブックマークLearning Reinforcement LearningGithub Repo with code and exercises Why Study Reinforcement Learning #Reinforcement Learning is one of the fields I’m most excited about. Over the past few years amazing results like learning to play Atari Games from raw pixels and Mastering the Game of Go have gotten a lot of attention, but RL i... dennybritz.com
dennybritz.com
dennybritz.com







