MeCab
(コンピュータ)
【めかぶ】
日本語の形態素解析器。
同機能を持つChaSenの3-4倍はやい。
また、はてなキーワードの抽出をTRIE を使って1600倍早くするPerl(&C++)スクリプトを公開している。
http://chasen.org/~taku/blog/archives/2005/09/post_812.html
近頃ではMysqlの全文検索ソフトSennaへの組み込みや、
作者の工藤氏によるAJAXによる日本語変換など、何かと話題になることが多い。
日本語の形態素解析器。
同機能を持つChaSenの3-4倍はやい。
また、はてなキーワードの抽出をTRIE を使って1600倍早くするPerl(&C++)スクリプトを公開している。
http://chasen.org/~taku/blog/archives/2005/09/post_812.html
近頃ではMysqlの全文検索ソフトSennaへの組み込みや、
作者の工藤氏によるAJAXによる日本語変換など、何かと話題になることが多い。


 techlife.cookpad.com
techlife.cookpad.com mecab.sourceforge.net
mecab.sourceforge.net
 inaniwa3.hatenablog.com
inaniwa3.hatenablog.com
 qiita.com
qiita.com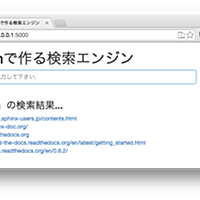
 nwpct1.hatenablog.com
nwpct1.hatenablog.com chasen.org
chasen.org
 code46.hatenablog.com
code46.hatenablog.com diary.overlasting.net
diary.overlasting.net
 ledge.ai
ledge.ai