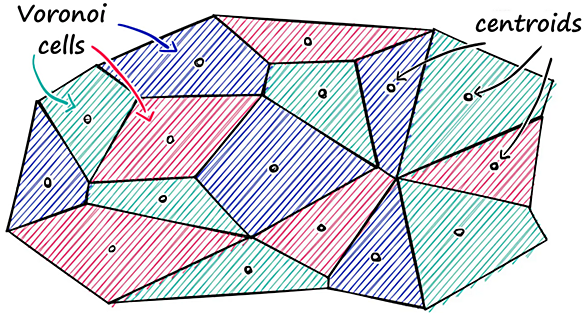
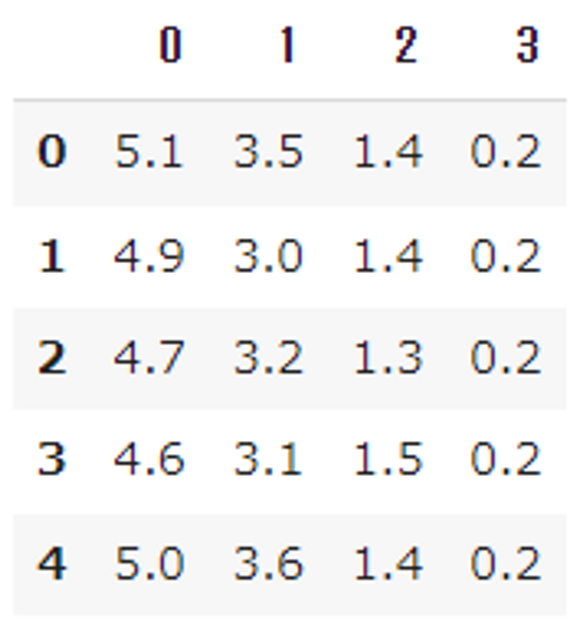
前回の記事の続きです。code-memorandum.hatenablog.com前回はサンプルデータをインポート、グラフ化するところまでをおこないました。 ■サンプルデータを取得、グラフ化 サンプルデータを取得できることは分かりましたが、 自分でランダムなデータを作成し、解析に使用する手法もありましたのでご紹介します。 from sklearn.datasets import make_blobs # ランダムの種が「0」で、特徴量は2つ、塊数は2つ、ばらつき1の、300個のデータセット X, y = make_blobs( random_state=0, n_features=2, cen…





 dev.classmethod.jp
dev.classmethod.jp
 qiita.com
qiita.com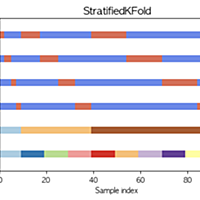
 upura.hatenablog.com
upura.hatenablog.com
 www.procrasist.com
www.procrasist.com own-search-and-study.xyz
own-search-and-study.xyz
 akiniwa.hatenablog.jp
akiniwa.hatenablog.jp
 tekenuko.hatenablog.com
tekenuko.hatenablog.com
 github.com
github.com
 qiita.com
qiita.com