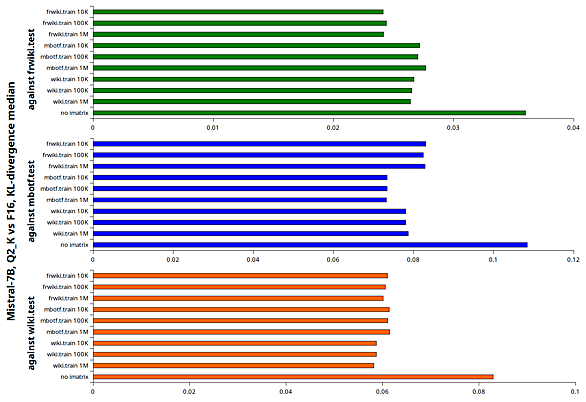
https://github.com/ggerganov/llama.cpp/pull/5747 llama.cpp では最近、ikawrakow氏による量子化手法のアップデートが熱心に行われています。 新しい量子化の実装が重なり個人的に分かりづらくなってきたので、簡単に整理しておこうと思います。 quantize.cppのオプションを参照すると、現在(2024.02)のGGUFバリエーションは以下のとおりです。 github.com 非量子化GGUF:"F32", "F16"。量子化していない巨大なGGUF。 旧量子化GGUF:"Q4_0"、"Q4_1"、"Q5_0"、"Q5_1"、"Q8_…



 developer.smartnews.com
developer.smartnews.com
 gigazine.net
gigazine.net
 zenn.dev
zenn.dev
 nmoriyama.hatenablog.com
nmoriyama.hatenablog.com
 secon.dev
secon.dev
 togetter.com
togetter.com
 qiita.com
qiita.com tkng.org
tkng.org blog.idein.jp
blog.idein.jp