BERTによる自然言語処理入門 Transformersを使った実践プログラミング [ ストックマーク株式会社 ]価格:2,970円(税込、送料無料) (2024/10/1時点) 楽天で購入 今回は、自然言語処理の最新モデルであるBERTを実践的に学べる一冊、『BERTによる自然言語処理入門: Transformersを使った実践プログラミング』をご紹介します。 項目 情報 分野 自然言語処理 出版社 オーム社 目的 BERTを用いた自然言語処理の実践的なプログラミング方法を学ぶ 発売日 2021/6/28 難易度 中級者向け(Pythonと機械学習の基礎知識が必要) 分量 200ページ 使用…





 qiita.com
qiita.com
 blog.takuya-andou.com
blog.takuya-andou.com
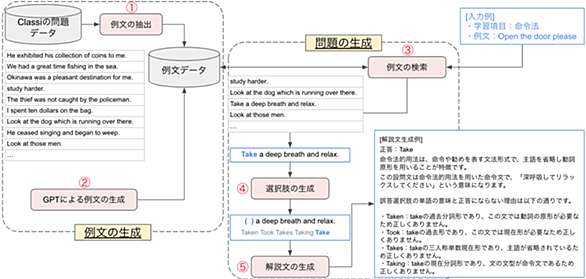
 nmoriyama.hatenablog.com
nmoriyama.hatenablog.com
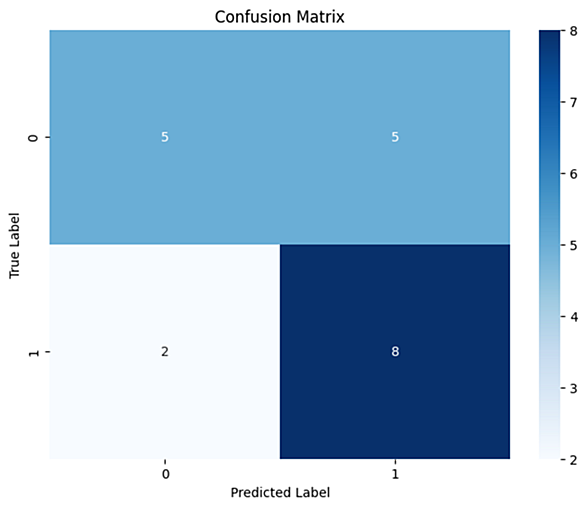
 qiita.com
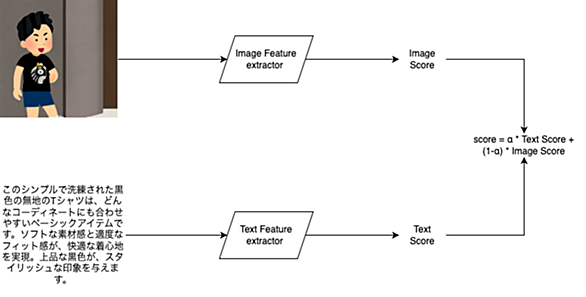
qiita.com ai-scholar.tech
ai-scholar.tech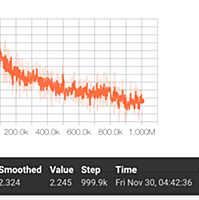
 techlife.cookpad.com
techlife.cookpad.com
 ledge.ai
ledge.ai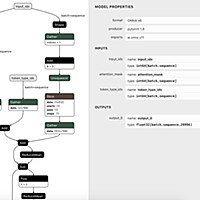
 tech-blog.optim.co.jp
tech-blog.optim.co.jp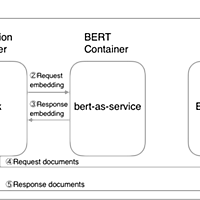
 hironsan.hatenablog.com
hironsan.hatenablog.com