こんにちは。エンジニアの浅見です。 今回は久しぶりに、社内のナレッジを公開いたします。 フレクトでは社内のナレッジを蓄積・共有するために「Fラボ」というツールを運用しており、以前にも「15分でわかる!Agentforce」や「15分でわかる!Salesforce で「生成AI」」を特別公開しております。 本記事では、社内のエンジニア向けに作成した AI 基礎トレーニング資料の中から「Vector Database(ベクトルデータベース)」の章を抜粋して公開します。 RAG システムを構築する上で欠かせない Vector DB の仕組みや実運用上の課題について、簡単な実験とともに解説したものとな…



 github.com
github.com www.tensorflow.org
www.tensorflow.org
 zenn.dev
zenn.dev
 speakerdeck.com
speakerdeck.com
 www.publickey1.jp
www.publickey1.jp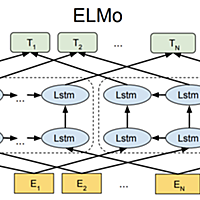
 yukoishizaki.hatenablog.com
yukoishizaki.hatenablog.com
 tech.mirrativ.stream
tech.mirrativ.stream
 zenn.dev
zenn.dev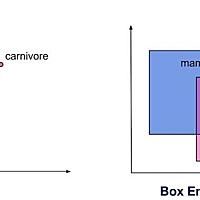
 ja.stateofaiguides.com
ja.stateofaiguides.com