こんにちは。エンタープライズ第三本部 マーケティングIT部の熊倉です。 このブログでは、高速に動作する分散処理エンジン「Apache Spark」とオープンテーブルフォーマット「Delta Lake」を基盤としたレイクハウス環境を構築できるDatabricks上で管理しているデータセットに対して、名寄せ処理を行うアプローチについて紹介します。 実際のノートブックの処理についても紹介しようと思っていますが、想定よりも内容が多くなってしまったので、名寄せの概要を紹介する「概要編」、ソースコードなど具体的な名寄せ処理の具体的な内容を紹介する「決定論的マッチング編」「確率的マッチング編」の三部作にしよ…
こんにちは。エンタープライズ第三本部マーケティングIT部の熊倉です。 このブログでは、高速に動作する分散処理エンジン「Apache Spark」と オープンテーブルフォーマット「Delta Lake」を基盤としたレイクハウス環境を構築できるDatabricks上で管理しているデータセットに対して、名寄せ処理を行うアプローチについて紹介します。 実際のノートブックの処理についても紹介しようと思っていますが、想定よりも内容が多くなってしまったので、名寄せの概要を紹介する「概要編」、ソースコードなど具体的な名寄せ処理の具体的な内容を紹介する「決定論的マッチング編」「確率的マッチング編」の三部作にしよ…
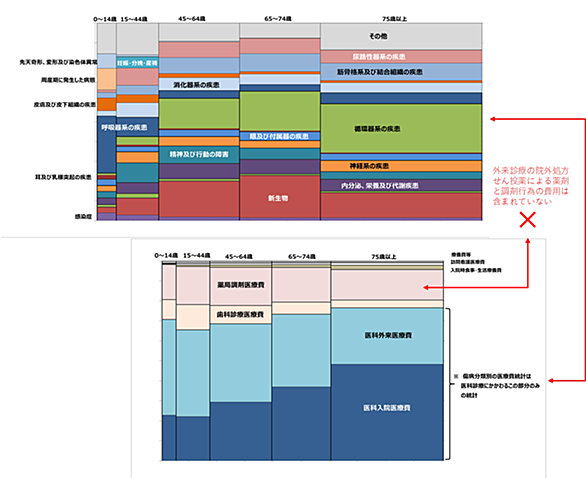
以前の記事で、国民医療費は右肩上がりで増えており、「高齢化要因」と技術進歩等による医療の高度化・質的向上などによる「その他の要因」がその主因となっていることを取り上げた。 人口が減少する中で、「高齢化要因」や「その他の要因」によって医療費が増加している実態とそのメカニズムを捉えることが重要となる。そのために必要なのは、保険診療にかかる費用の実態を多面的に捉えた統計データである。 例えば、前回の記事で触れた傷病別医療費。「国民医療費」、「社会医療診療行為別調査」、「医療給付実態調査」などの厚生労働省の既存統計にも、傷病分類別の医療計の集計結果が収載されている。 生活習慣病予防を推進する政策によっ…
みなさん、こんにちは。マーケティング担当の石田です。 早いもので今年もあっという間に終わりそうですね。 弊社も年末に向けて、毎日、営業活動やマーケティング活動に追われており、 皆さんの会社も同様な動きをされているんではないかと思います。 今回は、M365 Copilotを活用した、「データの名寄せ作業」についての活用例をご紹介したいと思います。 そもそも名寄せ作業とは? 名寄せ(データクレンジング)とは、複数のデータベースやリストに存在する同一または類似の企業・取引先情報を整理・統合して、重複や不整合を解消する作業を指します。このプロセスは、企業のマーケティングや営業活動を効率化し、正確なデー…
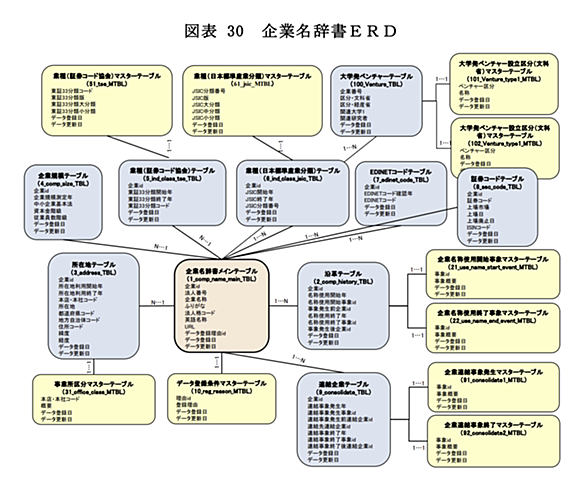
特許・契約書・有価証券報告書・企業関連ニュースなど、実応用上の自然言語処理では、会社名を認識したいという場面に非常に多く出くわす。 会社名らしい文字列をテキストから抽出することは、形態素解析器の辞書を用いたり固有表現抽出モデルを学習することである程度実現される一方で、抽出した会社名をレコード化して分析などに用いる際には、いわゆる名寄せの問題が発生する。 自然言語処理における名寄せに似た問題は、エンティティリンキングや共参照解析といったアプローチで探求されており、実応用上は前者のアプローチが採られることが多い印象がある。*1 名寄せタスクをエンティティリンキング的に解くためには、帰着先の知識ベー…
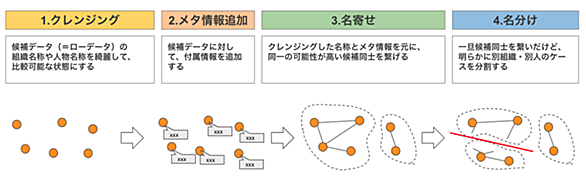
この記事は 自然言語処理 Advent Calendar 2020 の25日目の記事です。 こんにちは、rinoguchi です。今年の4月に こちらの記事 を書いて以来、半年ぶりの投稿になります。 当社では、特許・研究課題・論文など多くの知的財産データを保持しています。これらのデータを活用するには、データに含まれる同一組織・同一人物に対して同一IDを付与してデータをグルーピングすることが必要であり、この作業のことを名寄せと呼んでいます。 今回はこの名寄せの仕組みについて紹介したいと思います。 大まかな処理フロー 当社では名寄せ処理を、まずそれぞれのデータソース(例えば特許や論文など)の中で実…





 note.com
note.com
 www.slideshare.net
www.slideshare.net
 xtech.nikkei.com
xtech.nikkei.com
 enterprisezine.jp
enterprisezine.jp
 xtech.nikkei.com
xtech.nikkei.com markezine.jp
markezine.jp
 www.itmedia.co.jp
www.itmedia.co.jp
 gendai.media
gendai.media
 nov1975.hatenablog.com
nov1975.hatenablog.com