TsurugiとRSA
TsurugiとRSA
2023/12現在、Tsurugiは単ノード稼働の制約があるので、次のフェーズとして複数ノードでの稼働を目指しています。Tsurugiは直接の操作対象データのindex treeをメモリーにもつRDBであり、単ノードでのメモリー限界がパフォーマンス限界になります。複数ノードにまたがるメモリー・クラスターでの透過的な稼働をTsurugiの次の目標としています。想定されているアーキテクチャはRack Scale Architecture(以下RSA)になります。
RSAについては、まずこのポストがスタート地点。
https://okachimachiorz.hatenablog.com/entry/20151225/1451028992
これは2015年なので、8年前のエントリーになります。概ねコンセプトは変わっていません。(8年前は誰かがつくるだろうとおもっていたけど、まさか自分がやる羽目になるとは思いませんでした。)
まずはこのポストのreviewからですが・・・現在でもそれほど変わっていないところもあれば、変わっている部分もあります。
1.対象データサイズ
それほどの大規模クラスターは日本企業では必要ない、という8年前に比べてどうか現在はどうか?というと、たしかにPBサイズのクラスターは珍しくはなくなりました。とはいえ、一般的な企業でそのサイズのデータを保持・運用している企業はやはり現在でも少数派です。特に、ここ数年はクラウドもかなりの高コストになりつつあり、PBクラスの大規模データをクラウドで運用し、コストメリットを取るのは国内企業では簡単ではありません。
実際、ユーザベースで見た時に取り扱うデータサイズは増加したのか?という点では、おそらくちゃんとしたデータありませんが、体感としては、分析系については普通に5-10倍程度には増えた感じです。一方で、基幹系・勘定系については、1.2-1.5倍程度で、倍にもなっていない、という印象です。
概ね、一般的な企業のシステムのデータサイズは、100GBから10Tの間ぐらいで、さすがに単ノードでは足らないがハーフラック程度のサーバ数でそこそこに収まる、という状況に見えます。
2.H/Wのスペックから
RSAの定義については、「複数のノードを“高密度”にRack内部で組み上げて凝縮性をあげて、ラックベースの一つのコンピュータと見なすアーキテクチャ」で変わっていません。100コアマシーンがそれほど珍しくない現状では、“Rack内部で、総計1000コア+10TB-DRAMのサーバ・クラスター”はそれほど特殊でもないH/W環境と言えるでしょう。この8年でRSAの環境は身近になったとはいえます。
3.RSAの内部構造について
8年前のポストでは、RSAの特長として、RDMAとNVMを挙げています。まず、NVMですが、残念ながら普及の見通しは立たない状態になってしまいました。NVMは、やはり遅延がDRAMに足らず、またbyte単価がSSDには勝てない、という中途半端な状況だったのが最後まで普及に影響したというところでしょう。Intelの撤収はほぼ全面的なギブアップに見えます。
一方のRDMAですが、この8年で一般的になった、というところではないでしょうか。DCによってはかなり導入実績も出ているようです。特にHPCではもうかなり一般的なようですね。
下回りはEtherかIBで、直接のバス結合はちょっと下火感があって、まぁ割と一般的なバスで利用しましょう、ということになり、プロトコルはRoceV2か、iWARPかに現時点では収斂しつつあります。結局のところは、NIC経由はいいとして、カーネル・バイパスをするか?しないか?というところに還元されそうな気配です。
普通に考えればSoCでCPUから処理をオフロードしたほうが、圧倒的にコストが安いはずですが、豈図らんや、特にヘテロなワークロードではRoce等の設定やらドライバーの出来やらで、なんやら奇々怪々な不安定さがでる一方で、普通にスタック通したほうがクリーンで、存外パフォーマンスが出てしまう現状もあるようです。導入期あるあるではあるのですが、この辺どーにかならないのでしょうか・・・
DB陣営としては「透過的であることは正義」とばかりに、できるだけ論理層は分離するが吉、のデザインで、とりあえず低遅延なら下はなんでもよいですの強行突破ということになりそうな気配です。
また一方で、ここにきて、CXLが本命とばかりにドヤ顔状態でして、PCIe5の登場で出たばっかりのPCIe4があっという間に陳腐化の憂き目と、煽りをくらって「やっとできたもんねスマートNIC」が、これまたすごい勢いで次世代に移行とか、・・・いや、つくる方は投資回収できないのでは?という懸念もありますが。
総じて「低遅延でのRack内部・Rack間でのサーバ接続」は、ものすごく進歩しつつある、現在もっともホットなインフラの焦点の一つであることは間違いないでしょう。その意味でRSAをS/Wスタックとして、どうしていくか?を掘り下げるにはちょうどいい時期です。この辺りは、ミドルがなんとかするのが筋でしょう。選択肢は異様にあるように見えて、実は使えるのは2-3しかない、なんてのは日常茶飯事なんで。
◆TsurugiではRSAで何をするつもりなのか?
大きくは二つになります。replication/partitioningと分散トランザクションです。両者の違いはserialization spaceが単一かどうかです。前者では単一で、後者では複数になります。
1. replication/partitioning
replicationとpartitioning(disjoint replication)は、A) 同じデータをもつreplicationと、B) 同じデータを持たないpartitioningと、C) その混合のpartial replicationの3種類を想定しています。これら三つの違いはデータを各ノードに分散させる際の「重なり度合い」の違いになります。
A) replication

同じデータを複数の物理ノードにもつことで、可用性を確保します。複数ノードのメモリー・クラスターで同じデータを持ち、処理はすべてtransactionとします。すなわち、partial writeは発生させません。クラスター内で単一のserialization spaceを持ちます。commit levelはpropagatedになり、クライアントに対しては“必ず所定の複数のノードで同じデータが存在できた”場合にcommitが返ります。
必要な合意メカニズムは単純に静的なノード構成についてのみとし、log replicaについては考慮しません。シンプルかつ高速なアルゴリズムを利用します。(できれば作りたくないけど、たぶん作る羽目になりそう。極低遅延での余計なことを一切しないクラスターノード管理ミドルは実はありそうでないようです。大抵は余計なことをやる上に高遅延前提に見えます)
まったく同じデータを複数ノードのメモリー上に常にもち、サーバダウン時の可用性確保を極めて高速に行うことを企図しています。
B) partitioning
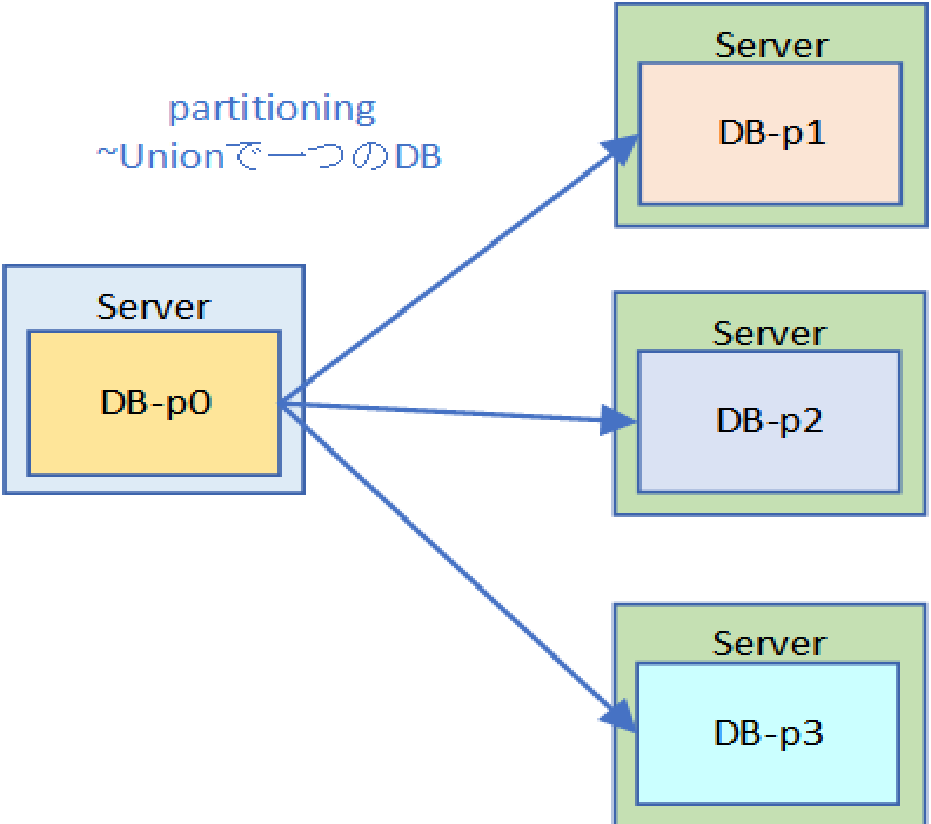
個々のデータを複数の物理ノードに分散させて、スケールアウトを確保します。複数ノードで同じデータを持つことはなく、複数ノードのデータのユニオンがDBそのものになります。当然ですが、A)と同様に処理はすべてtransactionになり、クラスター内部で単一のserialization spaceを持ちます。
取り扱うデータ量が増加した場合に、そのまま物理ノードを追加することで対応できることを企図しています。ただし、replicationがないので、単一ノードへの書き込みが失敗した段階で、DBへの書き込み失敗となります。すなわち、追加ノード分だけSPoFが増えることになります。
C) partial replication

partitioningとreplicationの「合わせ技」になります。各partitionの単位で、replicationを行います。replicaが存在するため、partitioningを行いながら高可用性を確保することが可能になります。B)だけでは可用性に難がある一方で、A)だけではスケールアウトに問題があります。したがって理想はその組み合わせということになります。
2.分散トランザクション
これは“複数”の”単一のTsurugi”にまたがって処理を行うときに、globalにserialization orderをとるという処理になります。この時の“単一のTsurugi”は物理サーバ数は限定しません。単一サーバであったり、複数サーバであっても構いませんが、いずれにしろserialization spaceは単一とします(なお、この時の論理境界をSphere of Control (SoC)と呼んでいます。要するに複数のSoCを処理するということです)。
この単一のserialization spaceを複数にまたがって、transactionを実行することをTsurugiでは分散トランザクションと定義しています。(すなわちTsurugiでは分散トランザクションは物理的なものではありません。)この辺りを目指していきます。
◆道具立てについて
replication/partitioningにしろ、分散トランザクションにしろ、いずれしても「高密度低遅延分散システム」です。この分散システムの論理インフラとして、Epoch based synchronizationをレイヤーとして作成し、同期インフラとします。時刻同期はH/W(物理time server)で行う予定です。いまのところの利用プロトコルはPTPっぽいです。
そもそもTsurugiは分散DBを企図してつくられています。Tsurugi自体がEpochベースなので、Epoch based synchronizationは、この延長線で行けますし、transaction処理はread-lock free / write lock-freeなので、各ノードでlockを取らずに処理を“渡り歩く”ことができます。このアーキテクチャは低遅延分散DBには極めて有利です。
リリース順としては、今のところはreplicationがもっとも先にプロダクションでリリースされ、次にpartitionが試験的に、プロダクションとしてはC)の混合を一緒にリリースされると思います、というか、この辺はもう想像ですね。分散トランザクションについては、現時点ではあくまでプロトタイプを想定しています。
また、partitioningについては分散Index treeを想定しています。DHTでは低遅延要求環境では、特にrange scanやfull scanで簡単にN/Wが(最適化を行っても)飽和する可能性が高いので、今のところは考えていません。
◆雑感
RSAという言い方自体は、多分に物理的な制約の話(Rack内部=低遅延)でしかないので、これを論理的な枠組として捉え直した場合は、最後は遅延限界の話に還元されるような気もしています。あくまでTsurugi、というよりもECCベースでの分散クラスター、が前提の話ではありますが。
仮にRackを跨いだN/W構成の遅延が、Rack内部と変わらないのであれば、複数のRackから構成されるRSAというのも勿論可能です。これはおそらく今後はDC内部・DC間にまで拡大することが可能で、この場合はDC間を跨いだ「RSA」ということになり、Rackの意味はあまりないですね。では、どこまで拡大するの?って話はあって・・・
https://dsstation.sakura.ne.jp/report/misc/chien_nw.html
なんてので計算すると(合ってんのかこれ)1000kmで片側6.5msです。すでにepoch=3msとして、物理的に成立しません。epoch=3~1msとすれば、往復で考えれば、100kmというのは一つの「カテゴリー」になるでしょう。その意味ではTsurugiが参加するPETRAにしろ、NTTのIOWNしろ、あるいは都市OS的なものを含めて100km圏というのは、すくなくともRSA的なアーキテクチャから見た場合は、一つの基準になると見ています。Tsurugiとしてはこの辺は真っ向勝負にいくもんね、ということで。
なお、100km以下であれば、サーバ内部の話になるので、これはIntel規格のバスの勝負の話でTsurugiとしては単ノードでどこまで切り詰めるか?という話題になり、逆に100km超であれば、どう転んでもGAFAMをはじめとするビッククラウドベンダーのDBの方が最適のはずなので、Tsurugiとしてはやるだけ無駄、という意識でござる。やったところで非同期のlog-shipになるので、普通に分散合意の悪夢再びかと。この辺は遅延とのトレードオフの選択か、または適当にRaftっぽいいつものヤツでお茶を濁すということになる気もします。個人的にいずれにしてもメンバーシップ管理とpartial writeの問題は「べつべつに」片付けた方がイイと思ってはいます。
そんな感じでございます。
本当にtransactionは必要なのか?
前提
前提ですが。
transaction=Consistency/Isolationを担保する仕組みの話とする。
一般にtransactionが持つべき属性はACIDと言われる。C/Iに比べて、A/Dが“わかりやすい”のでAtomic/Durableの属性の方が人口に膾炙しているが、現在のtransactionではA/Dネタはあまり話題にならない。A/Dネタはローカルだけで見るのであれば普通にfile system /storageの話になる。元来Atomic/Durableはtransactionのコンテクストでは専らlogging / recoveryの話だった。そして、これは非同期のepoch-basedになるとそれ自体の取り扱い優先度が下がる。現代的なtransactionでは、「現時点ではread committedが保証されているFS/storageでA/Dの問題は(ある程度)解決しましょう」ということになっている。
なのでtransactionといった場合はC/Iの話が普通にメインになる。実際、現状では、MVCCでインメモリー主軸でepochベースだと、よほど細かくepochを切らない限りは問題にはならない。version pressure が強いので、log以前に不要なversionを消す方で頭に血が上っているのが現実だ。
という前提で、
さて「本当にTransactionは必要なのか?」
DBにかかわる人間のほぼ100%が疑問に思うことではある。
大体理由は以下だ。
・そもそも難しい。理解している人間は圧倒的にすくない。
・パフォーマンス優先のためにぬるいisolationレベルで平気で運用している。
・なんだかんだで、結局DBの使い方は高機能ファイルサーバ。
よって、「別になくてもいんじゃね?」ということになる。
まず個人的な印象から言っていくと、たいていの場合は、
1.「あったほうがよいに決まっているが、今の実装は使いものにならない」派
2.「serializableでしょ?別にそこまでの一貫性はいらないよ」派
の2通りが多い。さすがに頭から「そんなモノイラナイ」という人は「あまり」いない。ときどき居るけど例外に近い。
1の場合は、transactionの必要性は認めているが、現状のままでは使えないというスタンス。transactionに相当する手当てをなんらかの形で行うか、または回避策をとっているケースが多い。
2の場合は、高機能ファイルサーバ的にRDBを使っている分には問題ない。そうではなくて、それなりに更新処理があるにもかかわらず、ぬるいisolationレベルで運用していることが、ままある。この場合、「serializableではない」とどういう問題がおきるか?ということがよくわかっていないことが多い。
transactionがまともに働かないときのバグ(ではないです。仕様なのです。)というかエラー(anomaly)はなにかと言えばviewの異常だ。ところが残念ながら教科書的な記述はanomalyはlost updateとinconsistent readだったりする。lost updateは特定のレコードのread modify writeが重ねるという特殊なケースだし、inconsistent readはread committedであれば回避できる。この二つでanomalyを代表させるのは無理がある。(phantom readは実は一番not -serializableの例としては良いのだが、この場合はキーの存在・不存在が話題になっているので論点が変わってしまい適切ではない)
もっとも典型的なanomalyはread skewの類いになる。読んではいけないデータセットをそのまま読んでいる可能性が高い。この手のanomalyが起きると、間違った計算結果が正常処理で返ることがあり、かつ再現しない。これは実は検出することが非常に困難だ。DBMS的には正常処理で“異常”なデータを返すので、エラー処理にはひっかからない。(なお補足しておくと、lost updateの排除のようなwrite abortは、これは単純にそのまま書き込むと”その結果“をどう読んでもviewがぶっ壊れているので、write側をabortしますって話になる。)
経験的には「serializableでしょ?別にそこまでの一貫性はいらないよ」派の人も、read skewの類いの面倒さがわかれば一概に「transactionは不要」とは言えないと思う。
なので、まともに個々人でtransactionの要不要の話をすると大抵は、「あったほうがよいよね」という話になってしまう。これはこれで、もやもやがやはり残る。
実証的な意味合いから
「たぶんtransactionはいらない。まともに設定されてなくても社会は動いているから。誰も困ってない。」こっちから考えたほうがよい。たぶん、実務面からみるとこれはこれで正解だと思う。実際なくてもなんとかなるなら、別段必要ではない。(もっとも、これは実はtransactionの話にとどまらない。IT全般にもあり得る話で、たとえば「ITなんかいらん。紙・Fax・判子で十分」という文化は未だにここらそこらにある。)
んでviewがぶっ壊れるのはまずくないか?って話で、これが普通にtransactionの要・不要につながる。
viewが壊れてまずいのか?
1.別にときどきぶっ壊れてもまずくないですよ。
まぁこういう話はどこまでいっても必ず起きる。対処は大抵の場合、あれなんかおかしいなと思ってもリロードしておしまいで、問題なしで片付く。まぁ現実の大半はこれだったりする。DBを高機能ファイルサーバ的に使うのであれば、まったく問題ない。確かにtransactionはイラナイ。単純に正規化して格納したデータセットに対してSQLでクエリーを発行できれば十分です、というものだ。更新はあっても頻繁じゃないし。
また、バッチでの洗い替えを定期的にいれて補正しているケースもviewが壊れても問題はとりあえずない。viewが壊れたままで書き込みを続行していくと、だんだんDB自体がぶっ壊れていくが、夜間バッチで全部洗い替えて整合性が取れるように「塗りなおす」ということであれば、特に問題もない。
実際、長期にわたって運用している業務システムでは、最初にバッチを組んだ人がリスクを見て意図的にデータのskewのクリーニングを(データ更新のタイムチャートを見て)入れていたりする。ただし、月日が経つとそーゆーのも忘れ去られて、「一貫性?必要ないんじゃない?」とまぁこういう感じになったりもするが・・・要は「運用でカバーしている」という場合になる。この場合もtransactionは必要ではない
上記の場合は、どうしてもデータはstaleになる。今の正確な値が欲しいというときには役に立たない。正確な現在の値は知りたいよね、という場合は当然あるし、そもそも普通はできればviewは壊れて欲しくない。ということで・・・
2.自分でアプリ側でlock制御するのでtransactionはイラナイよ
とまぁこういう理由が地味にアリガチだと思う。実際問題、isolationだけほしいのであれば、lockを使うことである程度保証はとることができる。「あったほうがよいに決まっているが、今の実装は使いものにならない」派の人は普通こちらだ。
ただし、この選択はトレードオフとして、自分での品質維持のコストとパフォーマンス劣化があからさまになる。なので、基本的になにも考えずに一方的にlockを利用するというのは、たいていの場合はコスト高になる。多少コストを払ってもよい、という位置づけであれば、アプリケーションレイヤーで、またはSQLレベルで明示的に、自分でlock制御をおこなえばいいので、transactionは必要ない。
要はtransactionが必要ではない、という実際的な面からみれば、上記の「それほどシステムは分離性・一貫性は“実は”必要とされていない」ということと「実際に必要な場合はコストをはらって自分で準備できる」ということに尽きるように見える。
まず「それほどシステムは分離性・一貫性は“実は”必要とされていない」ということは、ある程度は真実で、これは実際、一貫性が不要なケースで、不必要に過剰にRDBを使っているだけだろう。大抵の場合、しっかりしたfile systemかExcelあたりで十分なはずだ。(もちろんベースのデータサイズがExcelでは上限を超えるということはあるので、その場合はRDBを使うというケースもあるが、これはデータの取り回しの話で、普通にCSVあたりでちゃんと処理ができれば、わざわざRDBでの処理も必要もないことが多い)
ここでは、「多少コストを払ってもよいので、アプリケーションレイヤーで、またはSQLレベルで明示的に、自分でlock制御をおこなえばいいので、transactionは必要ない。」ということがあり得るかどうか?である。
lock制御での回避
これは実は二点論点があって
1.そもそもちゃんと制御できているのか?という話、と
2.仮に出来ていたとしてそれは今後も可能なのか?という話
になる。
1については、まさにDBAの腕次第というところだ。2PL-CSRの理屈がわかっているのであれば、ある程度の並行性を保ちながら、整合性をもったまま着地させられる。ただ大方は、排他制御によるsingle versionでのserial 実行の担保が現実だろう。この場合は工夫がなければスケールアウトどころかスケールアップすら難しい。その上、lock-releaseの管理をきっちり行わないと無用のトラブルも巻き込みかねない。出来なくはないがハイコスト、というところだろう。
lockの原則論から言えば、これは簡単で「読むべきもの全部(predicate)」にコンバージョンできないread lockを取る、でよい。これで普通にread fromが保護されるので、以上おしまいになる(ただし自分だけではなく、自分がoverwriteするconcurrentなtx全部にも同じことをやる必要がある)。なのだが、predicate lockは言うほど簡単ではないので、いろいろ面倒な場合は一気にtable lockやgiant lockを取りまくることが多い。それだとやりすぎるとほぼDB全体がほぼ線形実行になって使い物にならない。なので、conflictの範囲/タイミング/CRUDの依存等々をみながら、single versionであれば、lockとreleaseのタイミングを合わせながら、また、MVであれば必ずanti-dependencyのchainが切れるようにover-writerへの制約をかけるように、慎重に設計していくというのが普通だと思う。まぁ腕と経験は要る。ただ可能であるし、実際そういうSIはいくらでもある。現実のたいていのDBのserializableのisolationレベルが使い物にならないのであれば、そういう選択をせざるを得ないという事情もある。
確かにこれができるならtransactionはイラナイ、という考え方はその通りだと思う。同じ一貫性の担保をアプリで実装できるわけだから、別段にDB/ミドルで制御してもらう必要はない。とはいえ、これ完ぺきにやるには相応の技術と経験が必要で、そういうDBAがごろごろ転がっているわけでもなく、よってちょいちょい具合が悪いことになるが、その辺は例外処理+エラートラップの鬼守備SIとの合わせ技で乗りきる、というのが相場には見える。
それでこの「職人芸的なlockコントロール」がどこまで持つか?という話で、これが今後も可能なのか?という話、になる。
今後のアーキテクチャの変更と、lockとtransactionの位置づけの変化
この10-20年ぐらいのコンピューティングの変化では、まずやはり分散処理が大小さまざまに普及しつつあることだろう。小はNUMAから大は大規模分散ストレージまで、ムーアの限界/単ノードの限界からのスケールアウト戦略は、従前の単ノード/Diskベース/少量コア/少ないDRAMの状況を一変させている。
この状況下での一貫性担保のためにlockコントロールは極めて旗色が悪い。大規模クラスターでの分散lockは2PCの時代から「やったら負け」の代名詞のままだし、大規模サーバのrack scale構成もSOA/microserviceのかけ声はいいが、一貫性担保のための分散Txはlock取ったとたんにパフォーマンス劣化が激しい。さらにそもそもの足下のサーバのメニーコア/大容量メモリーですら、既存の2PL-CSRのDBではコアスケールすらできない始末になっている。明確になっているのは、この分散環境下では「lockのコスト」が想定以上に大きくなっているという現実だろう。
lockはある意味で分かりやすい。たとえば、CCの意味論とresource managementを区別しなくてもよい。特にcritical sectionの管理としてのlock制御は鉄板の手法であり、その延長線としてのread保護は実装容易性(ただし運用が容易かどうかは別)から、慣れていればいくらでも利用できる。その弊害としてはserializableの確保のためのlockなのか、serial実行のためのlockなのかの区別がつかない、ということになるが、パフォーマンス劣化が許容範囲に収まるのであれば、実装容易性に勝るものはないだろう。
このlock制御による一貫性担保は、centralizedな仕組みであれば非常にうまく機能する。コア数・メモリーが少ない環境下では目端の利く手元での自分制御が、杓子定規のアルゴリズム制御よりも効率的であることは言うまでもない。ただ、残念ながら分散環境下ではそうはいかない。lock制御で管理工数が嵩む上に、そもそものlock-releaseのturn aroundのコストが支配的になり始める。これはlockベースの本質的なものなので、いかんともしがたい。
こういったことを背景に技術的に最新のtransaction実装は、ほぼすべてtime stamp(TS)ベースになってる。TSとlockベースは実は論理的には同じことだが、実装がまるで異なる。アルゴリズムは(大抵の場合は)別物と言って良い。2PL-CSRの牧歌的な理論/実装に比べれば、次元の異なる難易度になってしまっている。これをスクラッチのハンドメイドで作り上げるのは至難の業だ。端的に言えば、lock/releaseの手順を、timestampをよりどころにしたアルゴリズムで解決する(lockであれば「見ればわかる」ところを「計算する必要」になる)必要がある。計算のためのデータ構造は用意する必要があるし、オーバーヘッドもかかる。そもそも計算コストを見積もる必要もある。
・・・・というわけで
「自分でアプリ側でlock制御するのでtransactionはイラナイ」というのは今まではよいが、今後は通用しない。なので、「transactionはイラナイ」というのは、「DB=高機能ファイルサーバ」に使っているケースや、「今の値は要りませんOLAP」だろう。たしかにそれは「transactionはイラナイ」。ただし、今後、今現時点の正しい値を知りたいということであれば、従前の自分lock制御ではおそらく抑えが効かなくなりつつなる。よってRDBでtransaction機能を提供する、ということは必要不可欠になる。まぁそんな感じだ。
・・・だからlockベースでできたから、このままいけるぜ、とかって無理だと思うよ。
個人的には、遠い将来には(近い未来では無理だと思う)TSベースでの制御アルゴリズムを各自がバリバリ実装していく時代にはなると思うけど、僕が生きている間には無理だと思う。
補足:TSベースで制御アルゴリズムを作るには
現状の実践の延長線では、OCCとかMVTOライクな形で行くのは手だと思う。この場合TSベースの仕組みはlockと違って、どうしても楽観になる。よって長いtxはほぼ確実に死ぬ。なので、単純なアルゴリズムではうまくいかない。ただ、すべてを悲観ベースでやる場合は、どうしても分散処理との相性は悪い。よって、TSベースの良さを生かすのであれば、OCC/MVTO/MVSGライクなアルゴリズム・コンポネントを下位に、またより上位にセミカスタムなアルゴリズムをワークロードに合わせて自分で開発して、楽観と悲観の間ぐらいの仕組みに「仕上げていく」ことが必要になる。データ構造・ワークロード・アプリケーションを睨みながら、この手のアルゴリズムまで作り上げることはlockベース実装とは次元が異なる難しさだろう。これはうまく組み上げた時の爽快感はなにものにも代えがたいが、うまくいかない場合は延々と悶絶してメンタルにくるので、おすすめはしない。が、腕に覚えのあるミドルウェア・エンジニアであればぜひ挑戦してほしい未開の地ではある。
AsakusaとTsurugiとバッチ処理(昨年に引き続き)
[昨年に引き続き]
Tsurugiについて
詳細は以下
・これは前回の繰り言
要するにRDBを作りましょう、という話。いろいろインメモリーでメニーコアとか、ECC(Epoch-based Concurrency Control)とか、いろいろ特長はあるけど、目標としている機能の一つに「writeバッチ処理に強い」というものがある。
■バッチ処理の困難さ
このあたりも繰り言にもなる。基本的にまず、そもそも論としてwrite処理は既存RDBとは相性が良くない。これは単純に整合性を持たせる(serializable)ためのコストが大きいことによる。そもそも相性の良くないwriteをさらに大量に、かつ一度に書き込むバッチはさらに重ねて相性が良くない。
以下、今年一年の進捗的な話
■Tsurugiの現状として
現在、Tsurugiでは本格的にバッチ処理対応に入っている。上記の通りの困難さが常につきまとうので、今後の具体的な方策は常に変更されるというか、試行錯誤しながらになる。
現在の見通しでは、個人的には
1.そもそもバッチ処理の整理
2.ベンチマークの作成
3.処理方式の検討
4.実装と実行結果の検証・ベンチマーク
5. 3-4の周回
6.目処がついた段階でその他ツールの整備
7.時間切れタイムアウト
の順で開発をしていくものになると思う。現状では、ベンチマークの作成が「大体こんな感じかな」で終了し、処理方式の具体的な検討に入ってる段階になる。
■バッチ処理の整理
去年の段階ではまだまだ整理はついていないよーん、という話だったけど、現時点は徐々に整理がつきつつある。まず前提としてのバッチ処理とは何者か、という話になるが、端的に言えば「いわゆる業務系の複雑な処理で、特に大量のread/writeを含むtransaction群をまとめて実行する処理」ということでいい。これも前のエントリーの繰り言になるが、Tx業界用語ではlong transactionという言い方が一般的で、いわゆる“バッチ処理”という言い方は日本固有だ。「まとめて処理する」ということでは、普通はbulkという表現の方がよい。
bulk処理の場合は複数transactionをまとめて、というニュアンスがあり、long transactionでは単一のtxで処理が長い、という意味の方が強い。日本的な「バッチ処理」という意味ではbulkの方が本来的な意味に近い。
その「バッチ処理」だが、今のところは、具体的には以下の二つのカテゴリーが検討されている。それぞれプロトタイプのベンチマークもできつつある。
1.Read&Write back
処理すべきデータの塊をまず一斉に抜きだしておいて、しかるべき処理を施したのちに、一斉に書き戻す。大きなIPO(input-process-output)の流れで処理を行うスタイル。旧来型の汎用機バッチからの、特にファイルベースでの処理からの、伝統的なバッチ処理。事前にある程度設計をしておいて開発されることが多い。バッチ処理対象と対象以外のデータの分離がしやすいのと、処理失敗時のデータのリカバリーや障害対策時の切り分けがしやすい。
2.Bulk long transaction
一つ一つの長い処理を、そのまままとめて固まりとして流す。そこそこの規模の(しかし、大抵は謎に巨大な)SQLを準備して、でかいLoopで全部一斉に(かつ、順に)処理をするスタイル。どちらかというとRDBでのSQLベースでなんとかします、というオープン系のバッチ処理によく見られるタイプ。バッチ処理対象と対象外のデータの分離がしづらい、オンラインバッチ処理で使われることが多い。個々のレコードをどかどか更新・参照をしながら、同時にある程度規模で定期的に集計・締め処理をリアルタイムで行い、速やかに上書き更新の必要がある時の処理。処理失敗時・障害発生時の対応手段がDBの機能に強く依存するため、小規模なものであれば、お手軽に開発できる一方で、巨大化したときのコスト(処理時間・開発メンテ工数)が(大抵のユーザが事前に見積もったコストより)大きく跳ね上がることが多い。
■現在のエンジンとバッチ処理
現在、Tsurugiの処理エンジンについては、2つを検討している。あくまで検討で本当にどうなるかわからない。・・・本来ならあまり公にすべきものではなく、もっと鉄板になってから書いた方がいいのだけど、NEDOプロなんで多少ふわふわでも開示すべき、という話。
Sirakami(白神)
SILOベース。ある程度の実装も行いつつある。こちらは多分ファーストチョイスとして提供されると思う。
OCCベースになるので、普通にwriteは不利になる。read heavyで writeは少々、というワークロードでは現時点では一貫性を担保(serializable)した世界最強プロトコルの一つ。シンプルでかつ強靱。ただしwriteについては、激しく不利である。
OCCの性格上、Bulk long transactionは向いていない。なにも考えずに細かい短い処理とwrite heavyなbatch処理を混在させた場合、場合によっては(back-offどれだけやろうが)終了しない処理が発生する可能性がある。よって、バッチ処理を実装するのであれば、普通にRead and write-backスタイルになり、OCCになんらかの手当をし、かつそれをtransparentになるような形にする必要がある。
Oze(尾瀬)
MVSRベース。こちらはまだ設計の試行錯誤段階。SirakamiがTSベースのOCCであるのに対して、こちらは今現在はTSベースでもlockベースでもない特殊なプロトコル。おそらく単独のエンジンとしてはTsurigiの最初のリリースでは製品化は時間的に無理だと思う。プロトタイプとして提供される可能性がある、というレベル。
MVSRベースなので当然serialization空間は広い(non-deterministicであれば理論上もっとも広い)。その分だけwriteには有利にはなる。ただし、メカニズムが複雑になるので、OCCに比べて、特に単純なワークロードが頻発するような場合は不利になる。
バッチ処理について言えば、Read&Write back / Bulk long transactionのどちらも可能になる。別段特別な追加的なアーキテクチャは必要ない。
■SirakamiとOzeの比較について
Ozeはまだ、検討段階でしかないので、比較云々は当然時期尚早ではあるけれど、デザイン的には別ものであることは明らか。Read主体であれば、ほぼぶっちぎりにSirakamiになるし、大量のWrite主体であれば、Ozeの圧勝だと思う。・・・まぁ要するに真ん中がベストって話になるが、そんな最強なものがあっさりできれば世話はない、という話でしかない。Write heavy batchに関して言えば、当然Ozeに軍配があがるはず。Sirakamiでも当然対応はするが、制約がつくと思う。
あとは第三案として、Sirakamiがベースで、一部Ozeのコンセプトを限定的に入れたものという技巧的な手がある。が、複数のCCを混在させたRDBは普通はない。とはいえ、バッチ処理を(あるいはタイムアウトしたwrite系の処理とかretryさせるときに)一種のプロテクトモードで実行すりゃいいだけだと個人的には思っているので、これだけリソースがある時代なら普通にアリだとは思っている。そもそも相性が壮絶に悪いなら適当にIsolateしてやればいいでしょう?という話は、理屈だけなら通るわけで・・・。この手の仕組みはRDBのど真ん中から作らないと絶対に無理なので、今回はいい機会なので、検討ぐらいはやってみるつもり。そもそも僕の担当でもあるし。普通にダメ元ではある。
以上はTsurugiの話。んで以下からAsakusa。
■Asakusaの処理
前回のエントリーでAsakusa=BatchTxの設計そのもの的な側面があるよ、という話だけど、これは整理をすると、Asakusaの処理が総じて、Read&Write back型に属するというところに落ち着く。Asakusaはもともと旧来型の大規模バッチ処理の分散処理での高速化というのが目的であるし、現在の使われた方もいわゆる基幹系のバッチに使われているのが大半。なので、どちらかといえば伝統的なバッチ処理への対応のためのスタイルになっている。また、加えて、処理自体をRDBから分離して分散処理し、RDBに書き戻す、というアーキテクチャをもっているため、形としてはRead&Write backを採用せざるを得ない側面もある。
SirakamiはRead&Write backでの対応になると思うので、Asakusa的な発想・ノウハウはそのまま利用できる。逆にOzeベースのものはAsakusa的ではないので、どうなのよ?というところもある。
ではAsakusaとTsurugiをどーするのか?という話にはなるが・・・
■Tsurugiのバッチ処理DSLとしてのAsakusaについて
これも前回のエントリーと同様。まず、前提として、Nautilusとしては、当然AsakusaはTsurugiの対象として考慮されるべきものだし、会社のポリシーとして顧客サポートをきっちり行うことが企業活動のベースになっているので、検討はする。
他方、Tsurugiは公金プロジェクトであり、Nautilusの私物ではない。よって、ユーザにAsakusaを強制することはそもそも論になる。よってTsurugiでのバッチ処理の「窓口」は一義的な提供は、当然より間口の広いものになる。
とはいえ、個人的には「業務プロセスを考慮した、複雑なフロー制御を旨とした、SI前提のバッチ処理DSL」では現在、Asakusaを越えるものはないと思うし、今後OSSでは永久に出る気がしない。RDB上でAsakusaが直接動いて、通常のSQLの実行のパフォーマンスにまったく影響せず、シームレスに相互が利用できるのであれば、Tsurugiの使い勝手については確実にプラスにはなると思う。
なので、検討はするが、NEDOプロの範囲ではやらない。あくまでNautilusの責任の範囲において行うし、結果どうであれ、必ず検討は行う。ここは変わらない。
その上で、DSLとしてどうみるか?という点だけど。
■AsakusaとTsurugiの組み合わせについてなにがうれしいか?
このあたりの議論は、現時点では整理も特にしていない。自分の個人のぱっとした思いつきでは大体以下3点。
1.SQLのハーネスとして
普通に複数のSQLの制御ハーネスとして欲しいというところはある。単純なSQLで処理が済むのであれば、それをUDFとしてAsakusaでコールして済ませたい。簡単なSQLをシンプルに書いて単純実行する内容をAsakusaで記述するとなかなかに面倒ではある。そういう場合は普通にSQLで簡単に処理したい。
2.Asakusaからのダイレクトの実行エンジンへのエントリーポイントの確保
SQLのハンドラーとしてではなく、普通のjoin処理での例外や泣き別れ・分岐処理については、そもそもSQLで記述するのは無理があるので、これらの複雑なjoinについてはAsakusaでハンドルしたい。簡単な字義通りのクエリーであればSQLで、複雑怪奇なjoinであればAsakusaで、それぞれ記述して、proceduralな形でまとめてTxとして処理し、ついでに例外処理もうまいことやっておきたい、そんなところかと。SQLを介さず(別に介してもいいがもうさすがにSQL生成はないでしょ)に直接スケジュールを叩き込むスタイル。CC側は別に普通にハンドルするだけで「Txが来ました。了解、処理開始します」で問題ない。
3.設計・テスト等のsuitesとして
そもそもAsakusaの存在意義・メッセージとしては「設計は残るが、実装は腐る」ということに尽きる。ちゃんと設計すれば、その分払ったコストに見合うだけのメリットはある、ということである。
SQLバッチでも同じようにちゃんと設計→実装→テストの枠組みを踏襲する仕組みとしてAsakusaを利用したい。ストプロSQLでのCI的な話であれば普通にAsakusaを利用した方が確実に見通しが良い気がする。ストプロってなにげにテストがつらいというかできないので。
とまぁこんな感じではあるが、これだと普通にSQLをUDFとしてAsakusaでコールできればよい、という話になってそれでおしまいなのか?とちょっと思う。これでは身も蓋もない気がするが・・・普通にアリな気がする。
例えば、集計系の単純なSQLを書いて、レポート生成系の処理やら例外ハンドラーをAsakusaで記述・処理して、出力をexcelにしたりして、RDB→集計→エクセルの流れをSIすると、なにかと楽な気がする。分散処理もしてくれるわけで。BI系処理でExcelからダイレクトにSQLコールもありだけど、処理を複雑にするとか例外処理とかそもそも多段のjoinとかやるとあっという間に100億太陽質量くらいの暗黒ブラックホールに成長したりするし、そもそもテストとかできん。
重い業務処理はそもそももちろんだけど、「軽いところの、もしかして重めかコレ」のところでAsakusaが使えたらいいよねとは思う。とにかく自動的に仕様が残るのがよい。いや、まじで。
■proceduralなAsakusaをTsurugiのCCから見たときにどう見えるか?
CC屋としてはAsakusaでのSQLのコールのタイミングとか、そのあたりのCC処理の方式とかは、なにも考えずにOKというわけにはいかないようも気がする。以下気になる点を書いておく。ただ、これはAsakusa、というよりもストプロのホスト言語一般に要求される仕様だとは思うし、もっというとある程度の低レベルのserializability空間しか担保できない仕組みではあれば不要だが、ある程度の高機能なCCができる仕組みで必要なものではないかと思う。
・externalityの確保
連続でSQL(Tx)をなげた時の最低限確保しなければいけない順序の制約。あるTxがcommitされて、「それを確認して」から、別のTxが投げられたときは、必ず連続(logically serial)にならなければならない。コア数少な目なリソース制約が厳しい以前の環境であれば、ほぼ暗黙に守られるが、メニーコアや分散環境下では気をつけないとかなり怪しいことになる。
・明示的なparallelismの提示
このあたりは、前回のエントリーと同じ。ストプロでTxを仮にステートメント単位で区切って、並列的に処理が「必ずできる」場合や、「できそうなのでやってほしい」場合にハーネス側で、明示的に指示をだすということ。特にLoop処理では、「順に処理」と「並列に処理」は意味が違う。また明示的な並列処理でも、「必ずできるので後先考えなくてよい」と「できると思うのでやってほしい」ではこれまた意味が違う。
・transactionのcontrol境界の提供
どこまでのstatementを一括のTxにするか、という指示。一括にした場合普通にcommitの単位が単一になる。失敗時には全部roll backされる。基本的にはCC側が勝手に判断するので実は不要だけど、運用として必要な場合があるので。
CC側から見るとこんなところかな、とは思う。もちろんDSLとして必要なもの・あるとうれしいものは鬼のようにあるとは思うけど、普通に言語設計の話になるので、ここでは割愛。
そんな感じ
OceanVista 再読
OceanVista
http://www.vldb.org/pvldb/vol12/p1471-fan.pdf
基本的アーキテクチャは、DC間クラスターをインフラにおいて、高遅延・耐障害性を前提にした分散transactionの仕組みになっている。
どう見てもAlibabaのOceanBaseそのものではない。が、同じAlibabaグループでかつ、Oceanの名前をつけているので、関係はなくはないと思う。少なくとも同じグループまたは情報交換はしているのではないか。技術的な方向性を模索するプロトタイプに見える。
バックグラウンド的な与太話をすると、Alibabaは、というか中国的には、ITでの米国からの依存脱却(ポーズだけなのか、実際なのかは置いておいて)を目標として掲げているのは周知の通り。んで具体的な話としては、Alibaba的には脱Oracleが一つの目標になっている。この目線で見たときには、この手のコア技術としての、transaction技術の習熟度や練成度はDB技術の独自性のよいタッチストーンになる。そういう意味で眺めてみてもよい。・・・まぁ、あの、残念ながらすでに少なくとも極東の某国よりは全然上です。(遠い白目
このレベルであればまだまだ追いつけると個人的に思えるのですが、はぁ、なんというか、そんなに難しいことはやってないんですけどね。
DBについては、世界的には3極になっていて、Oracle・SAP・中国だと思う。GAFAはちょっとwhaleすぎて違う感じですね。面白いのは普通にMSです。ただ例のSQLServerが(ry
OceanVistaについての個人的なインプレッションは以下
1. まずatomicな単純な処理「のみ」について、一貫性を担保する分散transactionでは、相当優位だとは思う。quorumとMV組み合わせは「アリ」で、今後のこの手の話では普通に検討されるフレームだと思う。個人的には高く評価したい。アイデアの筋は悪くない。詳細は訳出の方を読んでもらうとして、ざっくり言うとMVで非同期に書き込んでいき、version orderを利用してviewの整合性(順序)を確保し、そのプロトコルに分散合意を利用している。このためcommit protocolとreplication protocolが統合されており、なにかと効率がよい。なお、合意はgossipの上で割とシンプルなfast paxosを利用している。
2. ベンチマークはほとんど参考にならない。単純なPoCレベルで特に問題がないという話でしかなく、そもそも環境がpoor過ぎるように見える。特にある程度分散合意が前提であるのであれば、もう少し障害よりに振らないと参考値にもならないだろう。ただし趣旨としてtransaction処理よりの話であればわからないでもない。
3. TPC-Cをやっていないのは理由は明確で、全然パフォーマンスが出ないからだと思われる。これは理由は簡単で、いわゆるACIDなtransactionではない。(ただ間違いなく本人はACIDって言い張ると思う。)ACID transactionの原理原則のview equivalent(を保証するHerbrand semantics)を意図的に無視している。言い訳的にdependent transactionという言い方をしているが・・・当然、TPC-C“ですら“結果がでないのは火を見るより明らかなので、当然ベンチマークはしない。同業的には、「まぁそうだよな~」という気もする。とはいえ、NoSQLのナントカ・コンシステンシーよりは全然ましですが。
4. 要するにdeterministicな仕組みであるので、通常のSQLは普通に難しい。OceanBase自体は楽勝でSQLは使えているはずなので、その意味でもOceanVistaとOceanBaseはまったくの別物だろう。
5. 技術的な発展性については、いろいろ意見はあるとは思うが、肯定的にみている。特に、今後はDBの“バックアップ”は、普通に分散クラスターを立てて、そのままActxNインスタンスですべてを進めるというのが基本になると個人的には思っている。従前のバックアップ・耐障害系と正常系を分けるアーキテクチャは存在意義がない。理論においても、たとえばTx処理は正常処理/リカバリーという図式は基本的にもうないと思う。その意味では、MV(というか分散処理でのorderingだよねこれ)+gossip+quorumは有望だ。
6.そもそも何ために大陸間の分散transactionが必要か?ということと、その結果どのようなプロトコルが必要なのか?という点は考慮する必要があるとは思う。グローバルにサービスを展開するところはいちいちローカルにやっていてはいろんなコストが高い(特にソフト)はずなので、その意味から考える必要がある。
ただ日本ローカルでみた場合はまちがいなくDRが大きいとは思う。要はサイトダウンなんだが、そのコンテクストでどのような分散transactionのプロトコルが必要かは、考える必要はある。その意味ではある程度の遅延前提でのDR的な高可用性の確保として、OceanVista的プロトコルを一部適当に利用するのはありではないかと思う。
まずは低遅延サイト内での分散処理が基本になるが、その組み合わせとして高可用性を考えるのであれば、おそらくはPrimary-BackupをDR的に構築するのではなく、普通にPartitioned-Master/Master構成で、Over-DCではX-HTAP的なものになると思う。この時のlog転送のcommit/replicaプロトコルはそのままOceanVista方式もありだと思う
7. 余談だけど、今のTsurugiのread-only -anomaly対策の実装にこれを組み合わせるのはとても「興味深い」
8. 今後の技術動向としては、transactionとdistributedは基本的な基礎技術としてmustだと思う。片手落ちはだめで、両者をマスターすることがインフラ・ミドルウェア・エンジニアとしては必須になりつつある。これはなかなかハードルが高い。(・・・クラウドは使う分には便利だが、この辺は完全に隠蔽されるので、まったくわからないし、ノウハウもたまらない気がする。)
以下、ベンチは除いた本論の全訳になる。いろいろ微妙なニュアンスや表現の違いはあると思うが、原則として本論文の方が正しいので、そちらを参照のこと。もともと以下は自分用のものなので。
Ocean Vista
http://www.vldb.org/pvldb/vol12/p1471-fan.pdf
ABSTRACT
グローバルな分散データについて、conflict下でのACID transactionの提供は、transaction処理プロトコルのエベレストといえる。このシナリオでの、transaction処理では、concurrency control(以下CC)とレプリケーションのオーバーヘッドを増大させる大陸間ネットワークの高遅延が特に高くつく。この問題を緩和するために、OceanVista(以下OV)を導入する、これはすなわち、最新の分散プロトコルであり、strict serializabilityを保証する。
CCとレプリケーションはtransactionのvisibilityの問題を様々な側面から解決する、すなわちversionのwater markを利用してvisibilityを管理するmulti-version(以下MV)プロトコルと、効率的な(efficient)なgossipを利用した適切なviewの決定の配布を利用して、これらの問題を解決する。
watermarkのgossipはバッチ単位での非同期transaction処理とtransactionのvisibilityの通知を可能にする。また、このCCとレプリケーション・プロトコルによりデータセンター間の高遅延ネットワーク下での効率性が改善される。特にOceanVistaはconflictを起こして並列競合しているtransactionを処理することができ、効率的なwrite-quorum / read-oneなアクセスをサポートして、たいていのケースで、1 roundトリップで処理を完了する。実証実験ではマルチDCのクラウド環境で、現状最速の分散TxエンジンのTAPIRの、ピーク・スループットで10倍のパフォーマンスをgossipの追加的な遅延コストだけで実現した。追加の遅延コストはWANでのRTTの1ラウンド分で、ワークロードが低い最良条件の場合はその一ラウンドでTAPIRとほとんど同じ性能でtransactionがコミットできる。
1. INTRODUCTION
クラウドにより、耐障害性保証、スケーラビリティ、サービスのローカライゼーション、コスト効率性のために、アプリケーションとデータを地理的な分散DCにわたって配備することがより簡単になっている。そのようなインフラにより、中小規模の企業が世界中の顧客に対してグローバルな分散ストレージシステムを構築することも可能になっている。地理的に分散したデータベースシステムにおける分散Transactionは、ACIDセマンティクスを利用することによりアプリケーションを便利にする一方で、そのオーバーヘッド、特にグローバルな分散データに対すると高いコンテンションに対する、高いオーバヘッドが悪名名高い。
地理分散transactionのオーバーヘッドは、異なったシャードに対する単一性と分離性のコーディネートを行うコミットと同時性制御のプロトコルからだけではなく、単一シャードでの複数レプリカの状態をコーディネートする(たとえばPaxosのような)レプリケーション・プロトコルからも発生する。地理分散transactionでのネットワーク遅延の増大は、ローカルでの処理よりもよりずっと高いコンテンションをもたらす。たとえば、分散DBのベンチマークのワークロード(キー空間やターゲットスループットの固定)は単一リージョンで多数のサーバ下での分散DBでは低いコンテンションが低くなることがあるが、逆にデータセットがグローバルに分散した場合は高いコンテンションになることもある。[注:要するに、うまく分散させれば効率がいいこと当然あるが、そのままそれを地理分散にもっていくと崩壊するということ]
伝統的なCCメカニズム(たとえばOCCとか2PL)は分散transactionを同期的に処理する。transactionのロジックの実行中にtransaction orderを決定し、そのtransactionが排他的に最新のversionにアクセスできる時間の間だけデータオブジェクトの更新ができる。そのような排他アクセスは悲観ロックや楽観的な後追いでのvalidationの利用により保証され、結果、大抵の場合はすべてのread-write transactionにおいて、すくなくともWANでのRTT一回分の時間がかかる。ここでは、この排他的アクセスの時間をtransactionのserialization windowと呼ぶ。長いserialization windowはconflictしているtransaction並列実行の妨げになり、ハイパフォーマンスなCCプロトコル設計の大きな課題になっている。
他方、WANで接続されたシステムでのレプリケーション・プロトコルの設計は特に困難であり、これは地理的に分散したDC間を結合するN/Wが遅く(遅延は数百msecになる)かつ予測不能であることによる。結果として、Write-All(WA)はアプローチは、遅延するwriteの競合が厳しい。他方、Write-Quorum(WQ)のアプリーチは普通、専用のleaderか、またはquorumから読み込むを行うが、これは別の問題を引き起こす。leaderは潜在的にパフォーマンス・ボトルネックになるし、Reading-Quorum(RQ)は大抵のリードドミナントなワークロードでは、Reading-One(RO)よりもずっとコスト[注:workだが、quorum的な言い方だと多分load]がかかる。
TAPIRとかMDCCのような以前の研究は、CCとレプリケーションを効率のために単一のプロトコルにまとめている。TAPIRはWQROを許容し、結果inconsistent-readが起きる。が、これはCCとレプリケーションの両者のために、レプリカのquorumに対して”アプリケーションレイヤーでのvalidation”を利用することで対応している。結果、validation済みのリードは基本的にRQに一致することになる、とはいえconflictがないという特殊なケースにおいてCCプロトコルに部分的にそのオーバーヘッドが隠されるということになるが。それ以上に、TAPIRとMDCCプロトコルにおいては、conflictはより早いパスから実行を遠ざけ、別のより遅いパスにより、メッセージのラウンドを追加的に増えることになってしまう。[注:早いパス・遅いパス(fast path / slow path)というのはもうちょっと他の言い方があるとは思うが、単純にturn aroundとか実行stepでの想定実行時間のことでいいかと]
この論文では、OceanVistaと呼ばれる、最新のプロトコルを提案する。これにより、地理分散下のtransaction処理について、strictly serializableな分離レベルを提供する。OVはCCとtransactionコミットとレプリケーションを単一のプロトコルに統合し、その機能はviewのコントロール(visibility control)として見なすことができる。我々の考えでは他のtransactionに対するあるtransactionのvisibilityを維持することが一貫した分散transactionの主たるミッションである。multi-versioning(MV)に基づいて、OVは、version watermarkを利用することでvisibilityのトラッキングを、そして、効率的なgossipを利用することで適切なviewの決定の配付(到着か)(arrives at correct visibility decisions)を行う。watermarkはvisibilityのバウンダリーである:watermarkより下(below the watermark)のversionのtransactionは可読であり、watermarkより上(above the watermark)のversionのtransactionは読むことができない。OVは非同期かつ分散的に、集権的なleaderノードを“介さずに”watermarkを生成・gossipさせる。[注:このwatermarkの上下(above/below)ってのは、たいていの場合は単調増加なので、前・後(before/after)でいいのだけど、多軸・多層で判断しないといけないときに不便なのでabove/belowを使うという感じか。または単純にboundaryとして使っているので、そういう言い方になっているかもしれない。わかりづらいときには普通にbelow=before / above=afterで順序として理解してもいいと思う。]
visibilityコントロールはwatermarkを利用し、conflictするtransactionを並列処理することができる最新の非同期CC(Asynchronous CC=ACC)スキームを可能にする。ACCはtransactionの実行ロジックからtransaction orderを分離する:transactionは同期クロックに基づいて生成されたグローバルなversionによりtotal orderになる。並列性を最適化するために、ACCはread-write transactionを以下の三つの処理に変形する。
-write-onlyの処理 MVストレージのプレイス・ホルダー(すなわちファンクタ(注というかどう見てもFutureです。))のwrite
-read-onlyの処理
-特定versionの非同期書き込み
[注:ということで普通にHerbrand sematics的なアレは、実は後述のDependent transactionになっていて、ネタをバラすとこれは件のdeterministic DBの流儀。この辺で読む気力がなくなりますが、まぁCommitプロトコルとReplicationプロトコルの統合はそれなりに見事なので、言いたいことは一旦留保して読み続けるのが吉かと。]
visibilityのwatermark(Vwatermark)は特別なversion numberで、それより下のすべてのtransactionはそのwrite-onlyの処理は完了していなければならない(S-phase)。OVではVisibilityコントロールとMVにより、この処理の大半はたとえconflict transactionであっても並列実行できる。加えて、watermarkのgossipはtransactionのvisibilityをバッチ的に通知することができ、write-onlyの処理に対する効率的なatomicな複合キーでの書き込みにつながる。というのは、Vwatermarkよりも下のすべてのversionはすべてのキーがvisibleになるからだ [注:キー云々の話は、要はPhantomがない、という話だと思われる。]
レプリカ watermark(Rwatermark)、これより下のtransactionのversionは完全に対応するレプリカにコピーされているが、(このwatermark)は効率的なquorumレプリケーションを可能にする。OVでは書き込みはノードの競合と失敗を自動的に回避するためにWQ(それから非同期のWA)を利用する。書き込みはconflictがあっても早いパスでの1ラウンドトリップで行うことができる。あまりの大量のノードで失敗したときは遅いパスで2ラウンドトリップが必要になる。OVは大抵の場合、Rwatermarkより低いtransactionに対してRO(すなわちどのレプリカから読んでもよい)を利用することで一貫性のあるリードを提供することができる。読み込むversionは、完全にレプリケーションされていないものでvisibleな場合でのみ、RQを要求する。
OVプロトコルは分散transactionの通常ケース、すなわちストプロとキーがわかっているwrite-setを想定している。このtransactionモデルはいくつかの先行事例(16:H-store 24: Janus 29: Calvin)で使われている。
加えて、事前に宣言のwrite-setなしでのtransactionを、よく知られたテクニック、すなわちreconnaissance query (Sec 3.4)を利用することでサポートしている。注:要するにdeterministicな話なんだが・・・OceanVistaがOceanBaseで採用されていないだろうという理由がこれである。普通に考えてnon-deterministicでないとアプリケーションに著しく不便をかけることになる。Alibabaの基幹であるのであれば、ちょっとありえないのでは。他方、スケールさせて、ある程度の大陸間ベースを考えるのであれば、ブリッジ的なアプリを別途かまして、deterministicに処理するというのは可能で、その限りでこの種のアイデアが使われていてもおかしくはないと思う。)
OVはOV-DBと呼ばれるストレージシステム上で実装されておりAWSのEC2上でグローバルに分散transactionを評価している。OV-DBと地理分散transactionプロトコルのTAPIRを比較したところ、結果、OV-DBは中盤から高いコンテンション・同時性においてスループットでTAPIRを凌駕し、一方でwatermarkのgossipについては高い遅延を引き起こすことになった。特に、OV-DBは低いpairwiseなconflict rateですら一桁高いピークパフォーマンスを達成し、そしてgossipプロトコルは総じて追加的な一回のWAN-RTTの遅延コストがかかった。実証実験はOVが一回のWAN-RTTというもっともよいケースを達成したことを示す。これはTAPIRと同等である。
2. ARCHITECTURE
 Fig1にOV-DBのアーキテクチャを示す。それぞれのDCに少なくとも一つのgossiperがあり、複数ある場合は単にFTのためであり、よって独立かつredundantに働く。
Fig1にOV-DBのアーキテクチャを示す。それぞれのDCに少なくとも一つのgossiperがあり、複数ある場合は単にFTのためであり、よって独立かつredundantに働く。
Gossiper
gossiperはDC内のvisibilityの情報をwatermarkの形で集め、他の gossipersとそのwatermarkを交換する。グローバルなvisibilityの状態のviewから、gossiperはそのDC内部のwatermarkを生成し配布する。
DB Server
OV-DBはシャードにパーティショニングされている。各シャードはDBサーバのレプリカのグループ単位で管理されている。DBサーバは以下の三つの機能の責任をもつ
1. Transaction coordinator
クライアントからtransaction要求を受けたときに、各サーバはグローバルなユニークversion:tsをローカルクロック(注:たぶんロジカル)に基づいて、その要求に割り当てる。(例えば、timestampとサーバIDと単調増加のカウンターの組み合わせとか)サーバはそのtsに紐づいたtransactionを各participantにレプリケーションする。それから、transactionの結果(decide)を最初のサーバが返した段階で、クライアントに通知し、値を返す。
2. Multi-version(MV)ストレージ
各サーバはMVストレージのシャードのデータを保持する。各シャードは複製され、consistent hashingでアクセスされる。
3. Transaction execution
transaction ロジックは、各transactionのversion numberであるtsがVwatermarkを下回ったとき(when below)に実行される、各DBのストプロで実行される。
OVプロトコルは以下の原則を実行(enforce)する
P1 transactionはそのversionのorderに従ってeffectする
P2 各coordinatorは単調増加のversion numberのtsをそれぞれのtransactionに割り当て、visibleであるべきでないもっとも低いアサインされたversion number(すなわちSvw Sec3.3参照)を記録しておく
P3 VwatermarkはすべてのDbサーバの最小のSvwよりも大きくてはいけない(注?largeじゃなくてhigh?だと思う)
上記のプロパティが与えられると、Vwatermarkよりも下のすべてのtransactionは安全にvisibleにすることができる。かつ、より下のversionをもつtransactionが作られる恐れがないのでtransaction orderが固定できる。かように、OVはVwatermarkを利用することで、効率的に多数のtransactionのvisibilityをコントロールすることができる。
サーバのクロックは同期、たとえばNTPの利用、を想定している。クロックの異常はOVのパフォーマンスにのみ影響し、GoogleSpannerのTrueTimeサービスとは異なり、一貫性保証には影響しない。ネットワークはメッセージについて低品質、順序保証なし、遅延を想定するが、送り手が繰り返しリトライするのであれば結果として正常なサーバにはデリバリーされる。OVプロトコルはどのDC内でも完全な全部のレプリケーションは要求されない。ただし、この論文では分析を簡単にするために完全なレプリケーションを想定している。
3. CONCURRENCY CONTROL AND TRANSACTION COMMITMENT
OVにおけるtransaction visibilityの管理は非同期かつまとめた(batch)transaction処理を可能にする。ACCはconflictするtransactionを並列に処理するが可能であり、従来のシステムよりも高い並列性を提供することができ、abortまたはブロックによりconflictするtransactionを解決することができる。transaction commitmentはOVプロトコルのvisibility管理に統合され、2PCは必要ない。OVは多くのtransactionのvisibilityの情報を一つのwatermarkにまとめることが可能で、個々にtransactionのvisibilityを管理する(たとえば2PCのような)プロトコルよりも高い効率性を可能にする。プロトコルをより詳しく調べると、OVにおけるread-write transactionのもっともよいレイテンシーはTAPIRと同じということが分かる。すなわち1WAN-RTTになる。また、OVがstrict serializableを提供することの証明をスケッチすることにもなる。
3.1 Asynchronous Concurrency Control
最初に非同期並行性制御(ACC)の手法を提示する。事前にわかっているwrite-setに対するread-write transactionのテクニックになる。その他のtransactionのタイプについてSec3.4に詳細がある。OVは非同期にtransactionを処理する。すなわち:read-write transactionの処理をwrite-onlyとread-onlyと非同期のwriteのシーケンスに変形する。ACCはtransaction orderの決定をtransactionロジックから分離する、これはグローバルなwrite-setのキーの記録により達成される、その後でread-onlyの処理と非同期write-onlyが続く。
Write-only operation
ACCはversionがtsであるtransactionのwrite-setのキーを、Store-phase(S-phase)のversionの値にたいするプレース・ホルダーを利用して記録する。プレース・ホルダーはfunctorであり(注:何度も言うけど普通にFutureだと思う)transaction全体を処理するために必要とされる全部の情報をもつ(たとえば、read-set全体・write-set、パラメータ等)そのようなfunctorが、一般的なマルチ・パーティションのtransaction、当該transactionにおいて、あるパーティションから読まれる値が別のパーティションに書かれる値に影響するようなtransactionをサポートする。S-phaseのtransactionはvisibleでなく、かつそれぞれが別のversionを書き込む、そしてアトミックなマルチキーへのCCを単純化する。MVを利用することで、各transactionはユニークなversionを書き込み、Vwatermarkをgossipすることでvisibleになり、これは2PCでの2round目のメッセージをまとめることと似たような効果がある。
Read-only operationと非同期書き込み
ACCではtransactionはそのversionがVwatermarkよりも下になったときにのみ実行される。これは、tsよりも下にあるversionのtransaction orderが決定されたあとで、Execution-phase(E-phase)で記録されたfunctorが実行されることにより達成される。version tsのfunctorの実行は、まずread-onlyのoperationがtsの直前のversionのread-setのキーを読み(注:そういうreadプロトコルになっているということ)、つぎにtransactionの決定を計算し、クライアントに値を返し、そののちwrite-setのキーに対する最終的な値を計算し、最後に、非同期書き込みで、S-phaseにストアされたfunctorをその最終の値でリプレースする。もし読まれたversionが(値ではなく)functorであれば、DBサーバは再帰的にfunctorを最初に計算し、それから、計算された最終の値を利用してread-onlyのoperationを解決する


Fig2がACCにおけるtransaction処理のメッセージフローになり、Algorithm1 が(疑似コードでの)手続きになる。ここでは丸でマークされた数字(①)をメッセージフローと疑似コードを結びつけるために利用している。
まず、transactionがどこかのDbサーバ(ローカルなDCなものがあればそれ)にクライアントから送り付けられる。んで、transaction coordinatorが起動。coordinatorがTidMgr(Tx_Id_manager)をつかって、自分のローカルクロックに基づいて、グローバルにユニークなversion number tsをアサインする。コードブロックだと①、coordinatorがtransactionをそのtransactionのすべてのparticipantシャードにWrite(Sec4.1)する。これを受けたレプリカは、transaction全体をplaceholder(functor)として、そのversion tsの値として保存する。(注:place_holderに値じゃなくて関数(transaction処理、そのもの)をセットする。値を呼び出すときに実行される) んでその“値”はE-phaseでwrite setの最終的な値にリプレースされる。DBサーバはtsの保存にMV(Sec3.2)を利用し、S-phaseではtransaction間での順序付けを強制はしない。ということで、S-phaseではconflictによるtransactionのabortは決して発生しない。tsがすべてのshardに保存したときにcoordinatorはTidMgrに保存されたtransactionにマークをつける、そうでなければ(注:すなわち「すべてのシャード」の保存できないとき、これはquorumがとれなかったときになるが、その時は要はその順序の場所の合意が取れなかったということになるが、そのときに)abortされる。AbortTxnについてはSec4.1参照のこと。Algorithm 1の9-11行目はレプリケーションの非同期処理になっている。これはnon-blocking(詳細はSec4.2)
各DBサーバは継続的に最新のVwatermarkをgossiperから受け取り続け、Vwatermarkよりも低いversionをもつtransactionはすべて実行可能な状態にある。transactionはversion番号で順序づけされる。functorの実行は②の、そのversion番号のtsの直前のversionのread-setのキーを読むことで始まる。それから読まれた値に基づいてtransactionが実行される。読み込みは、tsがRwatermark(Sec4.3参照)のよりも下にある場合はもっとも近いレプリカに排他的に行われるかもしれない。③において、実行結果はcoordinatorに送られる。そののち④で、write-setのすべてのレプリカに非同期に書き込まれる。OVは、ストプロのtransactionのロジックはdeterministicなものを想定している。
:すなわち 同じ値を読んだ場合、functorの実行の結果は、同じ結果を出す。また、version tsのfunctorの実行は並列かつ独立に行われる。リプレースされたfunctorの重複実行を避けるために、最初の実行でversion tsのそれぞれのfunctorを最終の値にリプレースする。determinismは同じtransactionの、functorの同時実行が同じ結果を出すことを保証する。なので、coordinatorはfunctor実行の最初レスポンスを受け取るや否やすぐにクライアントに完了を通知する。(注:ここで言っているdeterministicという言い方はもっぱら分散処理のコンテクストでの言い方で、Tx用語でのdeterministicという言い方ではない。ただしOceanVista自体はdeterministic DBに分類される。)
議論:並列性について
read-writeまたはwrite-writeのconflictがconcurrentなtransaction間で発生するときは常に、従来からの同期CC(たとえば2PLとかOCC)はconcurrentに実行することができない[注:かなり乱暴な議論です] このことは、conflictしているデータへのアクセスに対して、最低でも一回の1WAN-RTTの排他的な”serialize windows”につながる。対照的に、ACCはconflictしている大抵の処理を並列に実行することができる。

Table1で二つのconcurrentなtransactionのACCのステップの組み合わせに対する挙動、共通のキー上での二つの操作について、並列に実行可能かどうか、を記述している。
二つのtransactionのwrite(すなわち、write-onlyと非同期書き込み)のステップはwrite-setが被っていても並列に書き込むことができる。なぜなら異なったversionを書くことになるだけなので。同様に、write-onlyとread-onlyの並列処理も異なったversionをアクセスすることになる。すなわち、一つがVwatermarkの上であり、他方が下になる。
ACCの二つのステップが完全に平行に処理できない唯一のケースは、read-onlyオペレーションが、他のtransactionの非同期書き込みと、特定のversionへのconflict(すなわちread dependentな場合)を持つ場合になる。しかし、この場合はたいてい、同期CCのread-writeよりも“contention footprint”で小さいで、かつ持続時間は1-WAN RTTになる。これは以下による
1) 最初のreplicaが非同期書き込み経由で最後の値にリプレースされてしまえば、(たとえば、ローカルDCのレプリカからの読み込み)readは成功する
2) このconflictするversionは他のversionの実行を妨げない。たとえば、ACCは複数のそのような同じキーに対するread-dependentなconflictを異なったversionで同時に解決することができる。
議論:遅延について
TAPIRはWANにまたがるストリームラインのcoordinationに対するプロトコルを利用する。結果として、TAPIRは最良のケースで、(ローカルのメッセージRTTは無視するとして)DCローカルのレプリカを読み、かつ読みも書きもconflictがない場合、1回のWANRTTの遅延が起きる。この遅延は、conflictからのリトライによりcontentionが増加するにつれ、ずっと増加していく。にもかかわらず、この遅延はwriteをvisibleにする非同期のコミットメッセージを含まない。(注:つまりコミットのメッセージは別にまた必要になる) OVプロトコルでもまた、1WANRTTで最良の遅延を達成する。Fig2からわかるとおり、S-phaseはWANは一つあれば十分で、DC内でレプリカが利用可能な場合は、すべてのE-phaseのメッセージは非同期書き込み、これは遅延に含まれないが、を除き、DCローカルになる。gossipメッセージがDC間にわたりgossipされる。しかし、gossiper (たとえばGとすると)は、仮にGがすでにtsよりも高いwatermarkを受け取っているのであれば、リモートなgossiperからのメッセージを待つ必要はない。Fig2の例でいうと、クロックが同期しているとし、WAN-RTTをTwanとすると、時刻tにおいて、DC2は頻繁に活動しないcoordinatorをもっているとして、gossiper_dc2はgossiper_dc1にtに一致するDvwを送る。gossiper_dc1はgossipメッセージをt+Twan/2で受け取る。また時刻tにgossiper_dc1はtransaction txnに対してtを割り当てる。そのtransactionは時刻t+TwanにS-phaseを完了する。ここで、時刻t+Twanにはgossiper_dc1はすでにDC2のDvwを受け取っている。んで、これはtよりも大きい。結果、gossiper_dc1はgossiper_dc2とのラウンドトリップのメッセージ交換なしで、即時にversion tがvisibleであることが決定できる。
3.2 Multi-version Storage
DBサーバはMVを利用してデータベースのデータを格納する。APIは他のMVシステムと似ている。すなわちPut(key, version, value)でversionに対する値を保存し、Get(key, version)でversionよりも大きくない最新のversion番号と値を返す。Abort(key, version)はversionをリムーブし、同じversionを二度と受け取らないようにする。ACCで利用するために、我々のMVは二つの追加的な特徴をもっている。一つは、Putする値は、functorでも最終の値のどちらでもよい。保存される最終の値はimmutableで、保存されるfunctorはあとで、最終の値にリプレースされる。Getは常に最終の値を返す、というのはアクセスしたversionが最終の値ではなくfunctorだった場合は、まず、DBサーバはそのfunctorを解決し、それから値を返すから。もう一つは、ACCではGetはVwatermarkより低いversionのみを対象にし、versionの挿入はVwatermarkよりも高いversionを対象にする。我々のMVストレージでは、データをversionでソートして、Getでは素早くversionの取得ができるようにし、時刻の基準値よりも古い不要なversionをGCする。
3.3 Gossip of Visibility Watermarks

単純に、P3の属性を満たすために、全部のDBサーバにアクセスし、S-phaseにおける最小のversionによりVwatermarkを取得することができる。しかし、Algorithm 2にあるように、DC内部のメッセージ交換を行うサーバ-gossiperと、DC間のメッセージ交換を行うgossiper-gossiperを利用することで、より効率的で分散処理のVwatermarkを生成するプロトコルがある。
Server visibility watermark (Svw)
SvwはあるDBサーバにおけるS-phaseでの最小のversion番号になる。それぞれのDBサーバは、S-phaseにおける全部のversionを記録することで、 TidMgrにおけるセット、すなわちTSsetとして、自分のSvwを保持している。TidMgrのcreateTS()が単調増加の番号tsを生成し(Algo1の2行目)、そのときにTidMgrはtsをTSsetに加える。transaction tsがTidMgr.store(ts)をコールし(Algo1の8行目)、自身のS-phaseを完了したときに、TidMgrはTSsetからtsを取り除く。もし仮にTSsetが空でなければ、セットの中の最小のversionがSvwになる。さもなければ、TidMgrがcreateTS()をコールしてtsをSvwtとして生成する。結果、先で生成されるversion番号はすべてより高いものになる。
DC visibility watermark (Dvw)
DvwはこのDCにおける最小のSvwに等しいversion番号になる。すなわちDCの内部ではDvwより低いversionはすべてS-phaseを完了している。おのおののgossiperはDC内部のすべてのDBサーバの最新のSvwのスナップショットを保持することでDvwを生成する。gossiperは継続的にSvwのためにDBサーバをポーリングし、一方、DC内のすべてのDBサーバに対して最新のVwatermarkを発行する。それぞれのDBサーバは減少しないVwatermarkを保持し、別のgossiperが発行した別のwatermarkを受け取った場合は一番高いwatermarkを常に採用する。
同様に、それぞれのgossiperもまたそれぞれのDCの最新のDvwのスナップショットを、他のgossiperと自分のDvwを定期的に交換する保持する。gossiperは常にそれぞれのDCでもっとも高いDvwを保持するが、これはSvwとDvwが減少しないことによる。Vwatermarkは単純にすべてのDCにわたる最小のDvwのスナップショットとして生成される。
3.4 Other Transactions
read-only transactionとwrite-only transactionはより一般的なread-write transactionに要求されるACCのいくつかのステップを飛ばすことができる。これによりパフォーマンスが向上する。また、事前にwrite-setがわからないdependent transactionの実行についてもこのサブセクションで説明する。
Read-only transaction
ACCはコンテンションにも関わらず、1ラウンドのメッセージにより read-only transactionのstrictly serializableを達成することができる。オーバーヘッドはスナップショットの読み込みに似ている。read-only transactionのプロトコルはread-write transactionのそれに似ているが、S-phaseにおいてDBサーバのcoordinatorにfunctorを保存するだけ、というところが異なる。ゆえに、S-phase全体とfunctor-to-coordinatorの通知はcoordinatorサーバのローカルな操作になる。E-phaseはtransactionにアサインされたtsについてread-only transactionを実行するだけである。特に、tsがRwatermarkよりも小さい場合は、read-only transactionを最寄りのレプリカに対して実行することができる。(Sec4.3参照)
Write-only transaction
write-only transactionのプロトコルはS-phaseで終わる。最終の値をMVストレージに書き込むだけである。coordinatorはクライアントにVwatermarkがtransactionのversionよりも高い限りは通知することが可能である。
Dependent transaction
すべてのread-set/write-setを決定するためにデータベースの値を読む必要のあるdependent transactionは基本的なプロトコルとしてはサポートされない。しかしながら、よく知られたテクニックである、認識クエリー(reconnaissance query)がこの種のtransactionをサポートできる。reconnaissance queryはdependent transactionのread-set/ write-setを一時的に見つけるために使われるread-only transactionである。dependent transactionはこの一時的なデータセットに基づいて実行されるが、E-phaseの最初にreconnaissance queryで生成された一時的なread-set/write-setがまだ有効かどうか値を再リードすることによって確認される。もしベリファイが失敗すれば、transactionの実行結果は”abort transaction”になる。そうでなければ当該transactionは基本的なプロトコルと同じように実行される。[注:ということで、RMWな処理が多発する大規模な書き込み処理を一斉に投げこむときわめてパフォーマンスが落ちる]
3.5 Strict Serializability
ここではOVがすべてのコミットされたtransactionについてstrict serializabilityを保証することの証明のスケッチを提示する。定式的でない言い方をすると、そのようなtransactionのスケジュールがserializableであるのは、そのスケジュールがいくつかのserialなスケジュールと等価であるときである。Strict serializabilityは、それに加えてserialization orderが、オーバーラップしない(注:Txの実行が重ならないという意味)transactionでのリアルタイム(実時間)での事前のorderと互換であることを要求する。[注:これは合ってます]後者の属性はconcurrent data structureの文脈ではlinearizabilityとして参照される。[注:これは言い方として不十分という意味で正確ではない。個人的にはこの手の言い方は背後にCSR・full-schedule前提のドグマがあるように見える。もちろん、その前提であればlinearizableとserializableのintersectとしてstrictは正しいとは思う。]
定式化せずに言うと、それぞれのtransactionが、実行と結果をかえすまでの間の、ある時点で効果を発現する(appear to take effect)のであれば(if)、コミットされたスケジュールがstrictly serializableとなる。このある時点をあるtransactionのserialization point(SP)と参照する。[注:この言い方だとtransactionごとにSPがあるということになる]
Serializability
OVで実行されるtransactionはP1の原則によりversion番号の順に効果を発現する。transactionは常に自身のversionの直前versionのキーを読む(Algo1 16行目)かつその更新はより高いversionのtransactionにしか見ることができない。
Strict ordering
それぞれのtransactionのSPを以下のように組みあげる:version tsをもつ、あるtransactionのSP(以下sp_i)はシステム内の最初のレプリカサーバがts_iよりも大きいVwatermark を受け取ったその時間になる。別の言い方をすると、sp_iはTiが別のサーバから見えるもっとも早い時間になる。我々は、ある一つの時刻で一つのtransactionだけが見えるようになる、ことを想定している、すなわち、SPは二つのtransactionについて同一であることはない。また、sp_iがtransaction Tiの実行開始と結果返却(invocation / response)の間にあることも簡単にわかる。というのはsp_iはTiのE-phaseの中になければならないから。また、OVにおけるTiの実行はsp_iで効果(take effect)を現す、以下。
1.Tiの更新はsp_iよりも前にはvisibleではない。これはsp_iより前にはどのサーバもts_iよりも大きなVwatermarkを持たないからだ。さもなければsp_iの定義に矛盾する。
2.Tiの更新はsp_i以降、他のtransactionに対してvisibleになる。Algo1により、sp_i以降、より高いversion番号をもつtransaction Tj (ts_j > ts_i)のみがTjのE-phaseにおいてVwatermarkがts_iよりも大きい、すなわちTiがvisibleであるとき、そのときにTiの更新を読むことができる。
Serializable order matches strict order
OVのスケジュールにおいて、どのふたつのコミットされたtransaction TjとTiについても、そのversion 番号がts_j>ts_i(serializable order)を満たすのであれば、sp_j>sp_i(strict order)であることの証明を簡単に示す。これはtransactionがSPとまったく同じようにversion番号によって順序されるということを意味する。これは背理法で証明できる。
sp_jにおいて、レプリカRはVwatermark>ts_jなるVwatermarkをsp_jの定義よりもたなければならない。議論のために、sp_i>sp_jか、さもなければsp_j>sp_iとし、strict orderはserializable orderと一致するとする。これはレプリカRにおいてはTiはvisibleではないということを意味する。よって、Vwatermark<=ts_iとなる。よって、ts_i>=Vwatermark>ts_jであり、これはts_j>ts_iに矛盾する。よって、OVはstrict serializabilityを保証する。(注:特に異論はないと思う)
3.6 On Clock Skew
coordinatorは同期のとれた(NTP)ローカルクロックからのtimestampを利用して、グローバルなユニークtransaction versionを生成する。SvwとDvwが単調増加する限り、我々のプロトコルではtimestampと実時間との乖離については、なんら要求はない。よってクロック異常はACCの正しさには影響を及ぼさない。
クロック異常にもかかわらずwatermarkの単調性属性を保証するには、プロトコルで以下のルールを適用する。まず第一に、coordinatorはもっとも高い割り当てられたtimestampすなわち lastTSを記録し、生成されたtimestampがlastTSよりも低いときは常に再生成するようにする。次に、初期化中は、coordinatorはDCのすべてのgossiperで新しいcoordinatorがアクセプトされるまで(後述)、クライアントの要求は受け付けない。最後にDvwの単調性属性を強制するために、gossiperはcoordinatorからのSvwがDvwよりも高いときに限り、新しいcoordinatorを受け入れる。
しかしながら、クロック異常はシステムのパフォーマンスに影響を与える。transactionはそのversion番号で順序付けられるので、より“早い時計”で割り当てられたtransaction番号は、transaction処理が不当に遅らせられ、遅延ペナルティを引きおこす。この副作用は以下の戦略により軽減することができる。まず、同じDC内部のサーバはLANで接続された同一のローカルタイムソースを利用し、単一のDC内部でのクロック異常を小さくする。次に、coordinatorは新しいクライアントの要求を、自身のクロックが異常な場合は、受け付けない。クロック異常はいくつかの方法により検出される、すなわち、タイムソースや対になっている(たとえば、他のDBサーバやgossiper)の時刻と大きな差を検出したり、または、ローカルクロックとVwatermarkとの大きな時刻ギャップを検出したりする方法による。
4. REPLICATION PROTOCOL
OVはCCとレプリケーションを単一のgossipベースのvisibilityコントロールに統合している。統合プロトコルのアイデアは以前研究([18/24/25])から借りてきたものだ、とはいえ、我々のgossipベースの、watermarkを利用することでコンパクトに表現されるvisibility情報を利用するアプローチは、地理分散データにより効率的なレプリケーションを可能にしている。我々のレプリケーションスキーマは、レプリカのスーパー・クオーラム(super quorum:Fast paxosで定義されているもの [注:しかしながらFastPaxosでは”super quorum”という言い方はない。後述にあるように|2/3f|+1)のことだと思われる。そもそもFastPaxos自体が複数のquorumを利用するスタイルなので、そういうやり方をしているよ、という程度の意味しかないような気がする]が利用できる限りにおいて、conflictにかかわらず、書き込みは1RTTで成功し、また、ひとたびmajority quorumが利用できれば、2RTTで完了する。これはどちらが先にきてもよい。read-onlyの操作に関しては、ACCにおいてこれらは常に対象versionにタグ付けされる。
watermarkのgossipにより、読み込みは常に対象versionがRwatermarkよりも低い時はどのレプリカからも行うことができる。これは通常の要求に対するWQRO(Write-quorum, read-one)を達成している。対象のversionがRwatermarkとVwatermarkの間にあるときは、読み込みは適合するversionのquorumを見つけために追加的レプリカにアクセスする必要がある。
4.1 Write-Only Operations
S-phaseでのtransactionは排他的にwrite-onlyの操作を行う。すなわちWriteとAbortTxnである。Fast PaxosとTAPIRの合意手順をまねて(inspired)Writeは特定のversionが保存されたかどうかについて合意をとる。これは早い手順(fast path)の場合は1RTTで十分で、遅い手順(slow path)の場合は2RTTが必要になる。Fast PaxosやTAPIRと違って、これらはconflictが検出された場合は遅い手順になるというパフォーマンスペナルティがあるが、OVでのWriteはほとんどconflictフリーであり、これはMVを利用して単にグローバルなユニークversionを挿入するだけ(S-phaseではリードしていないことを思いだすこと)だから。我々の場合で遅い手順が必要な場合は、障害(failure)と調停が必要な場合(stragglers)の時のみである。2f+1レプリカ配下でのfのレプリカ障害を許容するために、FastPaxosと同様に、早い手順では利用可能なレプリカのsuper quorum(3/2f+1)が必要になる。また、遅い手順では単に利用可能レプリカのmajority quorum(f+1)が必要になる。単純に比較するために、TAPIRでの用語を利用して以下にプロトコルを説明する。
1.coordinatorが[key,ts,value]をシャード内部の全部のレプリカに送る。んで、一時データとしてそれぞれのレプリカが保存する。んで、まずはレプリカは成功を返す
2.Fast path(早い手順)
タイムアウト前にレプリカのsuper quorumが返れば、coordinatorにはfast pathを選択して、呼び出し側に成功を通知する。それから、非同期にすべてのレプリカに[FINALIZE, ts]を送る。
3.そうでない場合は、すなわちmajority quorumが返ってきた場合、slow pathをとる。coordinatorはすべてのレプリカに[FINALIZE, ts]を送る
4.FINALIZEを受け取った場合、各レプリカはversionにFINALIZEDをマークして、CONFIRMをcoordinatorに返す。
5.Slow path(遅い手順)
coordinatorはf+1のCONFIRMが返ってきたときに呼び出し側に成功を返す。そうでない場合、もしレプリカのmajorityが利用できない場合はfailを返す
AbortTxnはそれぞれのシャード上で、(abort)判断がフォールトトレーランスにレプリケートされた時に成功する。シャードはそれぞれレプリカのmajority quorumが返る限り成功する、というのは、Writeの一時的な状態とは異なり、abort判断は決して再実行されないからだ。AbortTxnのプロトコルは以下になる
1.coordinatorは参加しているシャードのすべてのレプリカに[ABORT, key, ts]を送る。それぞれのシャードからレプリカのmajority quorumがひとたび返れば、呼び出し側に通知する。
2.リクエストを受けたときに、シャードはそれぞれAbort(key, ts)をコールして、coordinatorに成功を返す。
AbortTxnはalgo1の9-11行目にあるような非同期実行を必要とし、これはすべてのレプリカがabortに成功したことを示すために利用される。
4.2 Replica Watermarks: Rwatermark
replica watermark (Rwatermark)は特殊なversion番号で、それ以下のtransactionはすべての参加しているレプリカにwrite-onlyの処理はリプレケートを完了して居なければならない。Rwatermark以下のversionへのread-onlyの処理はすべてのレプリカ(例えばローカルのDCのレプリカ)の値に直接アクセスできる。Rwatermarkのgossipプロトコルは単純にSec3.3になるVwatermarkの生成プロトコルを拡張したもので、追加的なフィールドすなわち、server replica watermark(Srw), DC replica watermark(Drw), Rwatermearkを加えている。
gossipされた情報は以下にように利用される。Vwatermarkは、transactionのversionがほかのtransactionにvisibleかどうかを決定するCCとコミットに利用され、Rwatermarkは、レプリケーション・プロトコルにおいて、どのレプリカ(たとえばもっとも近いレプリカ)でも読めるように設計されている。特に、gossiperは最小のDCワイドのSrw利用してDrwを生成し、すべてのDCのなかの最小のDrwを利用してRwatermarkを生成する。それぞれのDBサーバでは、TidMgrが、完全にレプリケートされていないwrite-onlyの操作のすべてのversion番号を記録することでSrwを保持する。また、DBサーバでは自動的にRwatermark以下のすべてのversionをFINALIZEDとしてセットする。Alog1の9行目で、tsの完全なレプリケーションについての通知をTidMgrに行う非同期の手続きを開始することに留意すること。この手続きはwrite-onlyの操作(WriteとAbortTxn)が全部のレスポンスが返った段階で実行され、trasactionのE-phaseの最中かその終了後に行われる。Rwatermarkのgossipのプロトコルの詳細はVwatermarkのそれと似ているので、ここでは省略する。
Rwatermarkのプロトコルはシャード・Rwatermarkやホスト・Rwatermarkに拡張できる。言い方を変えると、gossiperとDBサーバは、シャードやホストについてのSrw・Drw・Rwatermarkをそれぞれ別の塊として持つことできる。
4.3 The Read-Only Operation
Read-onlyの処理、すなわちRead(key, ts)(ただし、ts<Vwatermark)は、keyについてts以下の最新のversionを取得する。ts<Vwatermarkの場合は、ReadはGet(key,ts)をどのレプリカに対しても直接コールすることができる。ということで、以下はRwatermarkとVwatermarkの間にあるversionのリードについて集中して述べる。
Get(key,ts)はSec3.2にあるように、versionと値を返すだけではなく、レプリケーションのタグであるTENTATIVEかFINALIZED (Sec4.1参照)も返す。シャードにおいて2f+1のレプリカを想定するのであれば、
versionがtsであるtransactionでVwatermarkよりも低いものは以下のふたつのケースのどちらかでなければならない。さもなければ、visibleではない。
1. tsのWriteが成功している。すなわち、少なくともf+1のFINALIZEDなレプリカか、または、3/2fを越える最小の整数+1のTENTATIVEかFINALIZEDなレプリカがある
2. tsのAbortTxnが成功している。すなわち、最大でもfのTENTATIVEなレプリカ、かつ、FINALIZEDなレプリカがない。
TENTATIVEまたはFINALIZEDな場合は、Writeが早い手順で成功した場合で、TEANTATIVEなレプリカのいくつかは非同期の確認(confirmation)でのFINALIZEDのタグを採用する場合になる。
ということで、read(key, ts)はすべてのレプリカに要求を送り、最速のsuper quorumが返る(またはタイムアウトでのリトライ)のを待つか、ts以下の最大のversionで最低でも一つのレプリカがFINALIZEDかまたはf+1のレプリカがTENTATIVEであるものを見つけることになる。これをreadのためのMATCH CONDITIONと呼び、最大のversionをMATACHED VERSIONと呼ぶ。アボートされたversionはMATCH CONDITIONは満たさない。最大のコミット済みのversionはレプリカのsuper quorumにあるのであればMATCH CONDITIONを満たす。このread(key,ts)のプロトコルはAlog3になる。

5. FAULT TOLERANCE
レプリケーションはOVに保存されたデータを恒久的な喪失から防ぐ。しかし、coordinatorとgossiperの失敗は、gossipベースのvisibilityコントロール・プロトコルのwatermarkの伝播を止めることになる。結果、可用性が損なわれる。この章では、サーバ・gossiper・DCワイドでの失敗からリカバリーのためのプロトコルを提示する。これらのプロトコルはデータベースがリカバブルであることを想定している。すなわち、2f+1までのレプリカでのfまでの失敗を許容するには、すくなくともすべてのシャードについてレプリカのsuper quorumが利用可能であるということを意味する。この前提において、リカバリープロトコルはSec4.3のreadを利用して、versionをリカバリーすべきか破棄するべきか決定することができる。
5.1 Membership Representation
シャードとサーバのロケーションを記録するために、OVはcoordinationサービスとして、RaftかZKを利用する。ぞれぞれのシャードは自分のメンバーシップを保持し、状態の変更(view)は単調増加の番号により区別さえる。それぞれのサーバはすべてのシャードの最新のviewをキャッシュしており、これはサーバ間の通信により、対象となるシャードのview番号が含まれている。サーバは通信によりそのviewが古いかどうか判断し、自身のviewを更新する。TAPIRと同じように、VIEW-CHAINGINGな状態にあるサーバは、リカバリーを除き新たな要求は処理しない。
Corfuのように、transaction versionのレンジにより異なったmembershipをもつことができる。たとえば、version[0, ∞]をカバーしているmembership<A,B,C>のシャードは、失敗したサーバCをversion1000から始まるサーバDに置き換えることが許される。すなわち、membershipの新しいviewは<A,B>で、[0,1000]をカバーし、かつ<A,B,D>で[1001, ∞]をカバーする。またその間、サーバDは1000以下のversionをリカバリーする。
5.2 Coordinator Failure
visibilityコントロールはcoordinatorからのwatermarkの集合に依存している。ということで、素早いcoordinatorの失敗の検出とリカバリーは重要である。coordinatorの失敗検出はgossiper-coordinatorの通信と統合されており、というのはすでにこれらがwatermarkを頻繁に発行・集約しているからである。それ以上に、gossiperとcoordinatorは常に同じDCにいるし、WANよりもネットワークの挙動が予測可能である。加えて、coordinatorは高負荷によるレスポンスの遅れを防ぐために、load shedding(高負荷時に新しいクライアントからの要求を撥ねる)や資源分離(CPUへの排他アクセス)を利用する。
各々のcoordinatorは自身の失敗のときに処理中のtransactionを完了させるために代替になるバックアップのcoordinatorをローカルのDC内部にもっている。なお、write-onlyの処理(WriteとAbort)の実行だけがgossiperのvisibilityコントロールに影響することに留意すること。ということで、coordinatorは(実行前の)writ-only処理と(実行後の)処理決定については、同期レプリケーションをバックアップcoordinatorと行う。これは、バックアップcoordinatorがすべての実行中のtransactionをもつことを保証する。gossiperが失敗したcoordinatorを疑って、リプレースを実行する場合は、バックアップcoordinatorにメッセージを送る。gossiperはwatermarkを生成するためにバックアップcoordinatorのステータスを利用する。フェイルオーバーの最中は、バックアップcoordinatorはオリジナルのcoordinatorからのレプリケーションのリクエストを受けることを停止する。これはオリジナルのcoordinatorは実際には失敗してなかった場合に(いったん)機能停止にしておくことによる。バックアップのcoordinatorは単純にすべての実行中のwrite-onlyの処理を再実行する。すでにabortされたすべてのtransactionは、abortされたversionをレプリカのmajorityが受け入れないように(promised)失敗しなければならない(Sec3.2参照)。coordinatorとそのバックアップの両者が失敗するような場合でも、いかなるコミットされたtransactionも失われない、というのは、どのtransactionもDCにわたってレプリケーションされるからだ。解決されないfunctorは次回アクセスされたときに最終の値にリプレースされるからだ。
5.3 Replica Node Failure
レプリカのノード失敗は、quorumが利用できる限り、シャードの機能を損なうものではない。というのは、レプリケーション・プロトコルがすでにフォールト・トレランスを提供しているからだ。ということで、レプリカノード失敗の検出と回復はより長い通信遅延を許容できる。メンバーシップ構成のプロトコルは、失敗したレプリカノードを新しいノードに置き換えるが、詳細は次に記述する。
シャード内のリーダ選出は手続きの再構成を行うためにRaftかZKでの利用を想定している。まず、リーダはVIEW-CHANGINGメッセージを全部のメンバーに送り、生き残っているメンバーは記録している最大のtransactionのversionを返す。次に、リーダは新しいメンバーシップに対して、新規にスタートするversionであるnewTSを選択する。これは生き残っているメンバーから返ってくる記録された最大のtransactionのversionになる。新しいメンバーシップは2つのレンジで構成される。一つはversion[0,newTS]でquorumサイズを変更せずに生き残っているメンバーで利用される。もう一つはversion[newTS, ∞]でこれは生き残ったメンバーに新しいノードを加えて利用される。リーダはメンバーシップのviewタグを更新して、新しいメンバーに送る。その次に、新しいノードは直ちにnewTSの上のversionを利用することを始め、newTSがVwatermarkよりも下にある場合は、newTSよりしたのversionをリカバリーする。versionのうちの失われた範囲については、生き残っているメンバーからバルクで引っ張ってくる。Sec4.3でのReadと同じように、MATCH CONDITIONを満たすversionはFINALIZEDとして保存されるべきで、そうでなければ破棄されるべきだ。最後に、新しいノードがnewTSに追いついたときに、リーダはメンバーシップを更新し、二つのversionのレンジ(<=newTSとnewTS<)を一つにマージする。
5.4 Gossiper Failure and Datacenter Failure
単一のgossiperの失敗はwatermarkの進行に影響はない、というのは、どのDCにも独立かつ冗長的に動く複数のgossiperがあるからだ。しかし、一つのDC全体から更新が失われた場合、watermarkの進展の妨げになる。というのはDCワイドのwatermarkが失敗したDCによりリフレッシュされないからだ。これは、あるDCのすべてのgossiperが、DSCワイドの災害により利用できないときに起こりうる。
プロトコルは、サーバがそれぞれのDCのメンバーシップのviewをキャッシュしていることを想定している。まず最初に、失敗したDCが取り除かれ、新しいメンバーシップがそれぞれのシャードの、失敗からのリカバリーリーダに送られ(Sec5.3の第二パラグラフ参照)、次に、それぞれのリーダが新しいメンバーシップをそれぞれのシャードレプリカに送り、レプリカは、失敗したDCからcoordinatedされたtransactionを受け入れないように、最大の記録されたtransaction versionを返す。それから、リカバリーのプロセスは、シャードの全部のリーダから最大の記録されたversion番号、maxRecordedTSを集計する。失敗したDCはVwatermwarkとmaxRecordedTSの間になるversionのvisibilityコントロールにのみ影響があることに留意すること。というのは、Vwatermarkより小さいversionはvisibleであることが確認されていて、maxRecordedTSよりも上のすべてのversionは失敗したDCからはcoordinateされていない。その後、リカバリープロセスはVwatermarkとmaxRecordedTSの間のtransactionの状態を収集し、Alog1になるCoordinateの手続きに従って、transactionの決定を計算する。最後に、maxRecordedTSより下位のversionの状態が解決されたあと、リカバリープロセルは新しいDCのメンバーシップとmaxRecordedTSを新しいVwatermarkとして、すべての残っているgossiperに送る。
Project Tsurugi(劔)とAsakusaについて
Project Tsurugi(劔)とAsakusaについて
ついでにAsakusa advent calendarの分も
■Tsurugiの特にNEDOプロ部分について
日経の記事はこちら
https://tech.nikkeibp.co.jp/atcl/nxt/column/18/00001/03044/
本紙はこちらからかな?
https://www.nikkei.com/article/DGXMZO51692890R01C19A1000000/
・NEDOのサイト
https://www.nedo.go.jp/content/100891996.pdf
・スライドはここ
・togetterはここ
https://togetter.com/li/1430683
本来であれば、あまり外向きに書く話ではないのですが、仮にも公金が入っていて、日経の方にも「親方日の丸」的は記事も出てしまっているので、当事者として「今の状況の感想」みたいなものを、外でしゃべった内容の補足として開示しておく感じになります。
ここに書いてる内容は基本的にNEDOで公開されている情報の解説なので、特に細かい情報が必要な人はそちらから取得してください。
・NEDOプロについて
TsurugiのNEDOに関わる部分は、きっちり公募に入札して、第三者の審査を通ったプロジェクトです。現在も監査を含めて、透明性・運用適正性が求められ、それに対応しつつ作業しています。尚、後述もしますが、Tsurugi自体はコミュニティベースの部分もあり、この部分についてはNEDOとは関係ありません。
・日経さんでの「親方日の丸」という言い方について
まず基本的に「親方日の丸」ではありません。そもそも「親方日の丸」が何かという話ですが・・・一円でも公的なお金が入ったら「親方日の丸」である、と言われると、その意味では「親方日の丸」になってしまいますが、そういう話でもないと思っています。(逆に公金が入らなくても「親方日の丸」なものはいくらでもあると思っています。)
おおむね個人的には、ITにおける「親方日の丸」は以下のスキームを指すと理解しています。
-霞が関が「これやるぞー!」と声上げて、
-適当なリーダーまたはコンサルっぽい人が意気投合して「やるぞー!」と呼応して、
-フォローの民間企業が「おー(震え声)!」、と続く、
というスキームで始まるプロジェクト的なナニカだと個人的には理解しています。
仮に「親方日の丸」が、この意味なのであれば、今回のTsurugiについては、まったく違います。
そもそもは有志で集まっていたDBやらTxやらの勉強会・コミュニティの延長線上で、「もう他に選択肢もないし、ちょっといろいろ自力でDBつくりますか?」という話で始まったのが事の起こりです。この勉強会・コミュニティは今も活動していますし、NEDOとは別に動いています。この流れの中で、国の支援を得るのはありではないか、どうなのか?という議論や紆余曲折があって、メンバーの中で支援を受けてもやぶさかではない、というメンバーがNEDOプロに参加している、という形になっています。よって、現在もNEDOには参加せずに、Tsurugiの活動に参加しているところは実際にあります。
よって、日経さんの「親方日の丸」の意味が、自分の理解している、また、おそらく多くのIT関係者が揶揄に利用する言葉としての「親方日の丸」ではあれば、事実と異なるし、逆に、1円でも公金が入れば「親方日の丸」である、という意味での「親方日の丸」であれば、その通りです。・・・なんでこんなこと言ってるかというと、単純に変なバイアスがかかるのがいやだからです。
・体制として船頭多くないか?という疑問について
体制図をご覧の通り、相当な企業・組織・大学が参加しています。実施する各自のタスクの割り当て/管理/成果物管理・NEDO完了後の普及へモチベーション/あり方は、参加者が連携を取りながら各自で進めています。
船頭的には三つあってそれぞれ役割が違います。学術的なとりまとめは東工大の横田先生にお願いしていて、全体の枠組・法的な対応・公的な対応はNECさんが担当、技術的な方向性やそもそものDBとしてのあり方のとりまとめはNautilusということで動いてます。それぞれの船頭がそれぞれの得意のところで水先案内をしているというところかと思います。なので、多分山に登ることはないですね。
なお、Tsurugiの特に技術的な方向性・勿論、枠組や全体の方向性としての合意は参加者全員で意思統一して上で進めています。その意味では船頭は多いとも言えますが、うまくバランスとってやっているというのが自分の感覚です。
・そもそも金が足らないんじゃないかという疑問について
まずDBとDBMSは違うので誤解のないように。今回作るのはDBであって、DBMSはPostgresの「外側」を利用する形になります。Management Systemレベルまでスクラッチで作るのであれば、たしかに全く金額が足りません。ただ、コアのDBだけを作るのであれば、金額として決して過小というわけではないです。
■Tsurugiの意義について
・そもそもなんでRDBなのか
そもそも今時RDBかよ、って言う人が多いかと思います。RDBなんてもう何十年も前の技術で、内容的は掘り尽くされているじゃないの?という印象はあると思います。実際、CPU・メモリーが貴重で、基本をDiskベースにした旧来のRDBの延長線上なのであればば、その通りでほぼ新規にやれることはあまりないと思います。
しかしながら、コア数と利用可能メモリーが文字通り桁違いに増えた現在のハードウェア環境では、旧来アーキテクチャのDiskベースのRDBでは残念ながら、前提がまったく異なるためパフォーマンスがでません。
メニーコア・大容量メモリーベースはそもそも考え方が旧来のDiskベースとは抜本的に異なるため、まったく新規に作っていく必要があります。この分野はまだまだ理論的にも未成熟でいくらでも研究・開発の余地があります。
・某商用ベンダーとあんた方まじめに勝負する気なのか
技術的にはまじめに勝負する気です。普通に勝算はあります。技術的にこれはいけるというものがなければそもそもRDBの開発などしません。
が、ビジネス的にどうかといえばその規模感は、アリと巨人ぐらいでしょうね。まぁそれはそうです。技術が秀でているからそれがそのまま普及してビジネスになるとはまったく思っていません。淡々と普通にやって、よりよい選択肢を提供していくことが目標になります。もちろん、公金が入る以上、普及や商用という話は出てきますが、なにより、まず自分たちでちゃんと使いたいというのが本音です。そもそも某商用ベンダーのアレはコストも含めて、ちょっとイマイチなんすよね。
・DBだけ作ったって誰も使わんでしょう
わかってます。普通にミドルはそんなもんです。なので、使いやすいように
1.OSSにした
2.外側は可能な限りPostgres
3.割と派手目の、毛色の違う3種類のプロトタイプアプリを準備する
と、ここまで準備します。それでも厳しいのは自覚しています。
・んで技術的にどうよってのは、端的に言えば
-低遅延分散環境を前提
-lockベースではなくtimestampベース
-order theoryとしてはPOSETのなかの特殊なサブタイプをバックボーンにもつ
-multi-versionな並行性制御を軸
-分散処理に最適な処理系/実行計画を装備するOLTP
-現状では最先端の最適化を指向したOLAP
-OLTPとOLAPをシームレスに統合したserializableなHTAPを視野にいれている
になります。なんかいろいろ難しそうなこと書いてますが、別にそれほど大したものではないです。今時であれば普通に考えるでしょう、というものをちゃんと入れているだけです。特段に奇をてらったというものは目指していませんが、次世代の標準の指針になるような意識はもっています。
■さて、ここからはAsakusa的な話です。
Asakusaの実行基盤としてTsurugiをどうとらえるか?は今のところは白紙です。もちろんNautilusのビジネスとしては、お客さんのことを考えるのであれば、一義的には考えるべきところではありますが、Tsurugiは別にNautilusが単社で全面主体でやっているプロジェクトではないし、公金も入っている以上、私物化的扱いは厳禁です。李下に冠をたださずが正しいスタンスでしょう。とまぁ倫理的な話はもちろん前提ですが・・・実際は技術的(どちらかというと理論的なフレームワーク)な話の方が問題です。
まず前提の確認ですが、メニーコア・大容量メモリー(NUMA)は基本的に分散システムです。なので、バッチ処理は、そのまま分散バッチ処理になります。よって・・・分散バッチ処理ではどのようなtransactionモデルを採用すべきか?ということになります。
グローバルなアカデミアでの「バッチ処理」の話をすると、まず日本的バッチ処理というのはわりとコンセプトとして二つの性格が整理されていない、ということが浮き彫りになります。
一般的にアカデミアでは、バルク処理としてのバッチ処理とlong transactionは別々にわけて考えます。バルク処理は複数のtransactionをまとめて処理とすることを指します。このときone-transaction(すなわちnested transaction)とするか、あくまで複数のtransactionかはケースバイケースです。現在のところは普通に複数のtransactionで処理という考え方が普通ですね。一方、long transactionはデカい処理が一つのtransactionとして処理され、他のtransactionと処理時間のスケールが合わないため、いろいろ厄介ごとがおきる、というものを指します。
それぞれ別のコンテキストで話をされるのが普通です。前者のバルク処理ではスループットの問題で、後者のlong transactionではlock制御の問題で、それぞれ専らに検討されます。日本固有(といってもいいかと思います)の「バッチ処理」では、普通に二者の話が混在します。整理されていません。
Asakusaでも、この混在の話は基本整理していません。まずもってtransactionがないので議論の無駄です。HadoopやらSparkやらでの処理は基本はisolationの保護は運用側のタスクになりますし、分散処理でlockとかスループット考えるとセンス悪すぎです。したがって、まずもってAsakusa→Tsurugiの筋道の前に「そもそもバッチ処理でのtrasactionをどう考えるかしっかり整理する必要」があります。
現状のTsurugiでは、やっとMCSRクラス相当のモデルが完成した段階で、その上のより高次のMVSRに近いモデルまでの定式化を進めている段階です。この定式化で分散処理・バッチ処理について目処を立てる予定です。バッチ処理的な分散transactionはまだ検討がついてません。なので、白紙ですというか、現時点では白紙にせざるを得ません。
とまぁこれだと身も蓋もないので、現在までの、自分個人の考え方を述べたmemoを置いておきます。これは個人のmemoに過ぎませんので、その辺の扱いでお願いします。
問題:
バッチ処理とtransaction処理での最大の課題は大量のwriteです。これはRDBがもっとも苦手とする処理であり、そもそも原理の問題になります。特にsingle versionのCSR前提の現在のRDBではlock制御が前提です。long transactionで大量にwriteをする場合は普通にDBが即死します。ハードがどんなに頑張ろうが、これはソフトウェアのアーキテクチャの問題でどうにもなりません。
どーするかって話ですが、原則論としては以下です。
-multiversionが前提。バッチ処理中とそれ以外の処理でversionをisolateする
要するにバッチ処理中のversionとそれ以外の処理を別versionとしてきっちり管理しきる。これにより、他のversionに対するtransactionを稼働させるということができ、バッチ処理中でも別の処理をconcurrentに走らせることが可能になります。もっともこれはそもそもMVの基本的な原理なので、これは“本来は”当たり前の話です。(というのは簡単ですが、なにも考えないと普通にNP完全で即死です。)
-メニーコアを利用して分散処理を原則として行う
要するにバラしてスループットを上げろ、ということです。もっと端的に言えば分散ノードではなく、メニーコア上でHadoopとかSparkっぽい処理をDB上で実行しろって話です。これも普通にスループットは上がります。このあたりはすでにAsakusa/M3BPで実績もあるので、勘所はある程度はわかっています。(というのは簡単ですが、なにも考えないと普通にbarrierで詰まりますね。)
以上をやるだけで、旧来のコア少なめのdiskベースのRDBよりも桁違いのスループットが出るのは確実です。というのは簡単ですが、この状況で「一貫性を担保する」方法は、2019年現在、世界中で解決案は出ていないレベルです。というか「そんなの無理だから検討するだけ無駄」ってのが世界の相場です。
まぁ、やりようはあるので頑張ります、ということになるかと思います。
それは追々説明するとして、(ちょっと面倒な数学/メカニズムを使う話になるのでここでは説明は省きます。)
まず、上記のMVCCと分散処理を前提として、いわゆる「バッチ処理のtransaction」をどう考えるか?のための整理のポイントをAsakusaの経験から以下に並べます。これは端的に言うと、並列処理ができる順でTx化した方がよいのではないかと思っています。要するに例えば・・・
[処理]
大量の在庫処理が前提で、ほぼ全在庫にアクセスして一斉に特定条件(相互に独立)に合った引き当てを行って、かつ伝発を行い、なんらかの総合計のレポートを算出する。
疑似フローは以下
-PlanA
TX-begin
LOOP
全在庫に順次アクセス:
アクセス順に条件にヒットした処理を実行:
各在庫別に伝票発行:
END_LOOP
レポート作成:
TX-commit
まぁ普通はないですけど、なにも考えないとやりそうではあります。1件でも失敗すれば最初から。実行計画的には一直線に順番に在庫処理をして、すべて完了したあとに集計して終了。失敗のroll backは最初から。
-PlanB
LOOP:parallel
TX-begin
全在庫に順次アクセス:
アクセス順に条件にヒットした処理を実行:
各在庫別に伝票発行:
TX-commit
END_LOOP
TX-begin
レポート作成
TX-commit
これが普通によくあるパターンの一つになると思います。これは実は伝票発行がストリクト・シーケンスなユニークナンバー要求だったりするとそこでつまります。ただし、そこ以外はconcurrencyが上がる。あとはなにか失敗した場合に、在庫→処理→伝票の単位でroll backできるので、全体の進捗が管理しやすい。伝票処理の業務例外を在庫関連に一部反映させたいときとか、いろいろ諸般の事情で「凝り固まっている」ときに有効。
-PlanC
LOOP : parallel
TX-begin
全在庫に順次アクセス:
アクセス順に条件にヒットした処理を実行:
TX-commit
END_LOOP
LOOP : non parallel / parallel
TX-begin
各在庫別に伝票発行:
TX-commit
END_LOOP
TX-begin
レポート作成
TX-commit
割と汎用機系バッチ処理では王道のバッチフロー。concurrencyの高い在庫処理のみを別Txにして、伝発とは別のTxにして可能であればparallelで処理。 ただしなにかの失敗が在庫管理と伝票管理の双方にまたがる場合は、ほぼ確実にroll backできないので、取り消しバッチを別に流す必要がある。
バッチ処理でTxを考えるのであれば、たぶんPlanBかCです。まぁ以前のRDBだと普通にPlanAとかやるので論外ですが・・・考え方としては、
1.DB側が勝手に判断して、BかCかを判断していい感じに実行する
2.バッチ設計者がBかCか判断してバッチを実装する
現実的には2でしょうね。
これとAsakusaがどういう関係か、という話ですが、Asakusaで開発をしたことがある人であれば、この設計はそのままAsakusaでの開発プロセスそのものだということがわかると思います。要するに「バッチ処理でTx処理をデザインする」ということは、そのまま「AasakusaにTxを導入する」という話とほぼ同じになります。その意味で、Tsurugiのバッチ処理とAsakusaは同じ路線の上にいるといっていいと思います。
そんな感じです。
以下、今までの印象とか感想ですが。
とにかくwrite intensiveなヘビーバッチ処理ってのと、現在のRDBのTx処理というのは、恐ろしく相性が悪いです。おそらくIT史上もっとも筋の悪い組み合わせの一つです。やればやるほど実感します。この問題はなかなか特級の厄ネタで、根っこにある数理モデルから根本的に再構成しないと手が打てません。
・・・しかしながら、普通に大量の書き込みやりながら、高スループット維持したままで、普通に単発のクエリーをどかどか打ち込んでも問題なく動いて、かつ一貫性を担保してほしいですよね。今時そんなこともできないのか?とか一般民間的には思うじゃないですか。世間は人工知能だ、シンギュラリティだとか、夢みたいなこと言ってるんすよ。その足下の基本のDBで、こんなことすら出来ていません。んで、簡単そうに見えて、これがまた想像を絶する難易度で・・・・。まぁ、なんとか頑張ります。
いずれにしろTsurugi頑張りますので、ちょっとでいいので応援お願いします。
とある魔術のMVCC入門(なんとなくわかりたいあなたのための)
・ご案内
MVCC=Multi Version Concurrency Controlは、DBのTx技術の中でも比較的上位魔法に属し、あまたのTx系統の魔術を学ぼうとする魔術師の挑戦を退けてきた。しかしながら時代はメニー・コア/大容量メモリーの時代に入り、MVCC系統の呪文を唱えるための触媒のコストが下がりつつある。
その簡単な解説を試みる。
-Tx系呪文について
Tx系のspellはDB界魔法の中では、いわゆる最高位の防御魔法に属する。言ってみれば多数の攻撃(これは物理攻撃はもちろん高度のSpell攻撃も含む)を捌き切ることがその特徴である。一般に最高位防御魔法は絶対防御系のものが多く、受ける攻撃をすべて無効化することが可能である代わりに術者側にも大きなペナルティを課すことが多い。この絶対防御系と異なりTx系は呪文発動中も術者も(余裕があれば)行動することが可能であり、そのアドバンテージは非常に大きい。
-MVCC系とOCC系
Tx系の呪文はその系統として大きく二つの系統に分けることができる。一つはMVCC系であり、もう一つはOCC系である。
OCC系は炎熱系の防御呪文であり、魔術構成はWall of Fireに近い。まぁ言ってみれば比較的シンプルな構成を旨として、敵の攻撃を端から焼く尽くす対応の呪文に近い。修行の結果ではわりと高火力にもっていきやすいので比較的人気がある。
これとは対照的なのが、MVCCである。
MVCC系統の呪文は、どちらかというと時空間系の魔術に属する。正直、MVCC系は技術的な習得が困難であり、加えて、術式構築の次元が高いため、詠唱にも手間がかかる。その割にはシチュエーションを選ぶことが多く、なかなかコスパを出しにくい呪文であった。
しかし相手が、かなりの大量のブレスや呪詛を一気に吐く高上位系ドラゴンだったり、分散混乱系のスペルを乱発する古代ビザンチン帝国のLichあたりだったりすると、一気に大量の負荷をかける攻撃(通称Bulk ATtacking Combination Hits)が主軸になり、OCCのMax火力で燃やしつくことができない。このような相手にはMVCC系のテクニカルな呪文を展開して総力戦を挑む必要がある。ボス対策には欠かせないのがMVCC系といえる。
MVCC系の真髄は、多数の触媒を利用した多次元多層的魔法結界(multiversion)構成にある。これはOCC系にくらべて触媒リソースをより広く利用することが可能であり、防御効果範囲(serialization space)が広いことが知られている。なお、完全な効果範囲の最適展開術式は理論上存在することはわかっているが、第7階位魔法(NP-Complete)に属すると言われており、その手法は未だ人類には未知である。
余談だが、2019/04/01現在では魔術師の世界大会の高火力コンテストではそこそこのMVCC系(筆者はMVCCと認めるには難があるとおもっているが、魔術師業界では一応MVCCとされているようだ)が炎術系OCCを抑え、みごと最高出力を記録している。その意味ではMVCC系統の呪文を極めてこそ真のTx魔術師のマスターと言える。
-MVCC詳細
以下の解題はMVCC系魔術の聖典と名高い三大古文書、すなわち”A Critique of ANSI SQL Isolation Levels[Hal Berenson, Phil Bernstein, Jim Gray, Jim Melton, Elizabeth O’Neil, Patrick O'Neil]”と “Concurrency Control and Recovery in Database Systems[Philip A. Bernstein, Vassos Hadzilacos, Nathan Goodman]”と”Transactional Information Systems: Theory, Algorithms, and the Practice of Concurrency Control and Recovery[Gerhard Weikum, Gottfried Vossen]”(実は”Theory of Database Concurrency Control[Christos Papadimitriou]”というものがあるがこれはちょっと次元が違うので)をベースに、ちょっくらMVCCの手引きを書いてみましょうというものだ。前提として、Tx魔術の初級であるIsolationの使い方ぐらいは理解しているという前提にたつ。
なお、以降は上記古文書の解読の結果に基づいて、筆者が勝手に自分の理解の手引きのために書いているので、ちゃんと勉強したいひとは海の向こうの魔術師協会で正式に秘蹟を受けることをオススメする。
-Tx系魔術の再考
まず、すでにご存知のようにTx系魔術の基本は攻性防壁を利用したカウンター攻撃による防御が原理となっている。一種のカウンタースペルになる。敵のアタックスペルや物理攻撃(一般にanomalyと称す)を端から撃破するわけだ。敵の攻撃の撃ち漏らしは、結果として本体に大きなダメージを受けることになり、最終的には戦闘不能になる。とくに一部の呪詛ダメージは原理的に事後的に観測することが困難であることが多く、周知のとおり、数多くの魔術師が「気がついたらとんでもないことになっていた」という状態で、討ち死にしている。
とくに対応魔術師が(Cloth armorを纏ったSkeltonとLichの区別がつかないぐらいの)norbの場合は、巻き添えをくらってほぼパーティが確実に全滅する。このあたりはエセ魔術師資格試験の”巫女資格”のゴールドとかシルバーとかを取得した魔術師風情によく見られるケースである。アレは個人的にはまずいと思う。特にパーティ募集の酒場での自己紹介履歴書で大きく書くのはどうかと思う。
んで、話を戻すと、MVCC系とOCC系ではこのanomalyの対処の根本的なロジックが実は異なる。もちろん、表面上は同じに見えるし、実際、古典的な入門魔道書のA Critique of ANSI SQL Isolation Levelsではanomalyは大きく三大要素に分類していているのみである。いわゆるDirty Read, Lost Update, Phantomになる。なお、実際はこれにくわえて中級魔法であるSnapshot Isolationでも防御不能のWrite Skewもあげている。
ただし、実際に一番やっかいなのはRead-only anomalyであり、これは「一見無害に見えるダメージゼロ攻撃」に対して、後述詠唱で遅効性の呪文をconcurrentに発動させ、一気に有毒化するタチの悪い攻撃になるというコンビネーション・ブローであり、正直対処が厳しい。
-ダメージ分解の基本原理
まずTx系魔法では撃退すべきダメージ(呪文であれ物理攻撃であれ)を単純な2要素、すなわちread属性とwrite属性に変換し魔術的に解釈する。(これに加えてcommit/abortを認識することもあるがこれは置いておく)。今更、Tx魔法の原理原則を言うのもアレではあるが、通常の属性であれば、単純魔法属性変換を行うことで、簡単に除去/dispel/de-curseできる。もちろん、攻撃側もそれは折り込み済みなので、実際は、それほど単純ではなく、この変換後のread/write属性の絡み合いでanomaly=ダメージが発生する魔術的なロジックボムが発動するように「組み上げてくる」のが通常である。つまり通常、問題となるanomalyはこの属性の特定の「絡み合い」すなわち一定のコンビネーションにより発生する。したがって、「特定のコンビネーション」を構成術式により順次認識し、dispelすることで一気に攻撃をパージすることが必要になる。
MVCCとOCCでは、この「Read属性とWrite属性の特定の「絡み合い」」の解釈の違いが大きい。これにより魔術のロジック構成が異なる。呪文の構成結果の効果としてダメージ発生(serializable effect)は、なるほど同じで、さらに構成手法の構築アーキテクチャも、利用される魔力の生成要素としての触媒も同じであるが、絡み合いの解釈での次元をさげて単純に力技にもっていくOCCと逆に次元を上げて処理をするのがMVCCで方法に大きな違いがある。以下個別に解説する。
-OCCでの魔術解釈
まず基本的にread属性/write属性を単純に三種類の組み合わせに還元する。すなわち
・write/read : 一番解釈しやすい。ある属性攻撃(write)に依存した属性攻撃(read)のコンビネーションになる。トラップとしては変換後に依存が発生するのを見越して仕掛けるタイプになる。割と簡単に見抜けるが、見逃すとイタイ。
・write/write:これも同じで、ある属性攻撃(write)の多重化。どちらかというとパラレルに来るコンビネーションで、変換後のコストを増大させる方向でのトラップになる。
・read/write:もっとも面倒で、属性攻撃に対してdelayさせて効果を変化させる特殊コンビ攻撃。delayのtimingの見極めがそれなりにかかるので、割と問題になる。
なお、read/readは独立性が高くそのままでダメージキャンセルができるので、普通は放っておく。
これらの攻撃を一定の順序に処理しながらパージしていく。このときに、パージする順序に魔術的不整合が起きないように、術式構成を動的に組み合わせて触媒がちゃんと働くようにしておく、ということが肝になる。この順序処理での不整合は簡単に魔法防壁を破綻せしめるため、特に注意が必要だ。
まず、このOCCについては、魔術構成の次元空間は単一であり、ここに押し込めることがまず基本になる。このときに若干(というか相当)無理があり、なるべく触媒の単位当たりの効率性をあげるために低コストで大量に「押し込む」ことが肝要になる。結果、本来であればパージしなくてもよいものもパージすることにするため、触媒の使い方としては無駄が発生する。しかし、シンプルな次元に押し込めることにより、単純魔術要素展開の魔力を効率よく注ぎ込むことができるため、多少の無駄があっても魔力で押し切るということが可能になる。
この時もっとも効率よい魔法元素が炎熱系であるので、魔法実行環境として炎熱系のロジックを転用して発動させることが多い。
-MVCCの魔術解釈
これに対して、MVCCはそもそものダメージ属性を多面的に捉えて次元数を上げ、一つの魔術的多様体として処理する。前述のr/w属性の絡みを以下に形で認識する。すなわち、
1) まず基本構成として、write-readのコンビネーションを認識し、一つの魔法次元空間を作成、この次元空間にコンビネーション要素をそのまま移管する
2) 移管したwrite-read空間に「同次元干渉」するwrite属性に変換された要素の認識した場合は、これを同じ次元空間に押し込める。問題がなければここでOCCと同じ単純なread-write処理を利用してパージする。
3) 2)が成立した時点でのwrite/read—writeの次元空間に、「別次元干渉」する「別のwrite属性に変換された要素」が認識されたとき(これは前述のOCCでのread-write / write-writeのコンビネーションをより高い次元で俯瞰したときの構造になる)には、前述の次元空間とはもう一つ別の”魔法次元数が同じ”次元空間を作成し、そこに当該write属性の要素を放り込む。
4) 次に、より高次元の魔法時空間を一つ作成し、そこに上記の二つの次元空間を移管する。この時に、移管されるべき次元空間の時間進行は外側から一時凍結する。つまり凍結時空とは別に術式を進行させるために高次の時空間を作り出すことになる。
5) 移管された高次元魔法空間で、魔術不整合が起きない次元空間連結を行い、その連結空間で一気にパージして、同時に放出される変換エネルギーで、作成された異次元空間をすべて吹き飛ばす
つまり、同時に三つの時空間(上位で一つ、下位で二つ。ただし下位についてはN個の制御をすることも可能)を制御する必要があり、かなりの高難度の魔術操作が要求される。このときに、次元数を一つ増やすか、増やさないか?で魔術のレベルがまったく異なる。すなわち、
5’) 4)の高次元魔術空間を召喚するのではなく、そのまま、単純に次元連結をしてしまう方法もある。この場合は、メタレベルの時間軸が与えられないため、自由に触媒を利用する時間が存在せず、そのままシーケントに連結することになる。これはよりレベルの低い方法になるが、次元負担が減る分だけ詠唱コストが低い(MCSR術式と言われている)。
現状の魔術の最高レベルでも実は後者の方が主流で、魔術レベル的には最高峰と言われている上記前述の(1+N)軸の世界線を自在に操る魔術師は、長い魔術の歴史の中でも、いまだ公式には確認されていない。
-MVCCの秘奥義
以上のこの状態でも現在のMVCCは十分に奥義と言えるが、特にこの上位でより高位の術式を実行できることが理論上は確認されている。この場合は、上記の1+Nの魔法次元空間のさらに上位の魔術時空間を作成し、もっとも下位に閉じ込めた時空間から適当な空間を選択し、上位の空間に転移させる。さらに転移時点でその特定時空間の時間遷移を凍結せずに進行させておく。その上で、時間軸自体を完全に偏向させて、その次元連結の自由度を上げるという術式になる。この場合は、制御時間軸が1+1+N軸になる。これは例えば、特に攻撃者のコンビネーション攻撃に対して、攻撃者の時空を一時的に凍結し、時間的に後からの攻撃を先に防御、その反動エネルギーを利用して、「先に来ている攻撃」を相殺するという術式が可能になる。要するに手元で簡単なタイムスリップさせるということになる。すなわち、意図的にタイムマシンパラドクスを発生させ、術式終了時に解消させる術式(厳密には違うが、こういう理解でいいと個人的には思っている)になる。たとえば、まだ現在の敵がemitしていない未来の攻撃(未来の敵はemitしている)を先取りして、現在の敵の攻撃に相殺させることができるということだ。
もちろん、前述の1+N軸でも、論理的にはタイムスリップになっているが、時間軸方向とスキップできるタイムスロットに制約がかかっているので、タイムスリップといっても非常に単純なものだ。後者の術式は自由度が圧倒的に高い。どんな攻撃がどう来ても関係ない。理論上は無敵である。(なお、筆者が探求しているのはこの2+N軸の魔術構成だが、わりと絶望的にわけがわからないというのが現状だったりする。)
なお、これを実次元にprojectionした場合は、まずone-shot requestを利用して、攻撃者の時間を一時的に凍結させ、実時間での挙動を制約し、同時にロジカルな別のミンコフスキー結界空間を構築し、そこで魔術処理を実行、group commitのタイミングで空間をパージして、実時間に「戻す」という複数の世界線を使い分ける呪文として発動する(より正確には発動しているように“見える”)。なお、このタイムスパンは現状で10-20msecが通常のスケールになっている。一般民間人からすると1/100秒程度だが、魔術的にはかなりの時間になる。
以上である。
ざっくりそんな感じなので、より詳細に知りたいかたは、上記の古文書の解読をおすすめする。なお、その際には独力での解読はかなり高いレベルでの魔術の素養がないと難航を極めるので、適切な魔術師の手ほどきを受けることをお勧めする。
日本社会はロボットによる労働力不足解消の夢をみるか?
どちらかと言うと関係者向け。
とある事情でロボットとかCVとか、いろいろAI系(の一歩手前)に関わることになっている。業務系IT屋と今後のマーケットの視点で書いておく。最初に断っておくが自分はロボットに関しては素人なのよ。なので、だからむしろこれから書くことは間違っている可能性もある。単純に「外側から見た考え方の一つ」だと思ってもらっていい。そのつもりで書いておく。
前提はNCやFAと言った工作機械の延長のものではなく、あくまで人手の代替を行える水準のものを想定する。ま、極論いうと「劣化版「鉄腕アトム」」だ。
現状全般
一般に言われていることであるが、日本は世界歴史上ないかつてないレベルの高齢化になっており、少子化対策の失敗からの労働力不足に思いっきり正面激突して半死半生である。こういう大惨事のさなかに、この労働力不足を真面目にロボットで補うという、まさかのSFチックなこれまた世界史上例のない試みに向かっている。というか向かわざるをえない。というかほかに選択肢があったら教えてほしい展開になっている。
たしかにそれは極端過ぎるだろう、という意見もあるとは思うが、そこまで追い込まれているところもあるのは事実だし、後から記述するようにそれほど条件が悪いというわけでもない。
通例的には、諸外国の例ではこういうケースは移民や外国人労働者で補う。たしかに現在の日本でも就学生や外国人労働者は多くはなった。現在は、なし崩し的に行っているケースが増えてきている。社会的なルール・整備も行わずに場当たり的な方向に進めている政策も出始めているし、実際に、なんの考えもなく「この手の話」に携わっている人も結構見る。
が、国民意識的には確実にこの手の「外国人の輸入」には「なんとなくノー」の方向になるだろう。隣近所で母語が通じない集団がやたらめったら増えた時の、既存社会の抵抗感やその結果の軋轢・社会問題化はすでに欧米で顕在化している。これは周知のとおりだ。その時の社会問題の深刻化は、「場当たり的な政策に安易に携わっている人」の想像を超える。特定のNative Japanese speakerに対してですらヘイトスピーチのような問題が発生する日本で、Non-native Japanese speakerに対してどんな動きになるかは簡単に想像できるはずだ。(個人的には日本の場合はまちがいなく、「福島」がまず最初に日本の“Ganz unten”になると思う。真面目に日本の恥になるので、この手の話はせめて福島のメドがついてからにしてほしい。)
現状のロボット導入論
さて、ロボットだ。・・・おいおい、ロボットかよ。というちょっと前ならば荒唐無稽にとられかねないぐらいの話が、無責任なAI論やシンギュラリティ論といった、現状の実装をみればどこでそういう妄想が沸くのか理解に苦しむレベルの言説に後押しされて、まじめに各所で語られ始めている。そして、残念ながら後先を考えないPoCや試験導入も散見されている。
具体的にどういうところでPoCとか導入論がささやかれているかというと、自分の見ている限り全日本労働力不足地獄の二大辺獄たる小売流通業と介護産業のケースが多い。若年層労働力不足はほぼ今後も解消される見込みがない中で、小売(流通・物流)/介護ともに一種の労働集約的な巨大B2C産業の代表選手であり、比較的抜群に「人手が足らない」。その意味では、ロボット的ななにかの導入は避けて通れない道、筆頭にいる。
幸か不幸か、仕事的に両業界には程度の差はあれ関わっているので、ある意味、ギャップが顕在化するその先鋭部分に立ち会っている感じになっている。一回整理しとく。
ロボットそれ自体の話
-デバイスとかのハードウェアの周り
デバイス周りといってもまさに多種多様で、それこそ「鉄腕アトム」の各パーツごとにまるで違うという状況。さまざまなハードウェアが必要になる。このハードウェア全般は、見ている限りではおそらく日本は世界的にかなりの高水準にある。ロボットでは基本的に精密動作が求められるため、制御が適当でよいというわけにはいかない。この点で日本企業とその技術は製造技術を含めて、トップエンドにある。
グローバルで見た時の優位性は、おそらく単一技術・単一企業での強みというよりも、「やっているところが多く、その幅も広い。自社製品や技術のどの辺が劣っているか?が、わりとわかりやすく、技術的な切磋琢磨がしやすい」という風に見える。割と「俺TUEEEE」やった途端に「オマエYOEEEE」の突っ込みが瞬間で入る業界に見える。ある意味ホントに凄い。
特定の企業の特定の技術にどっかのGoogleが金だしたからすげー、とかいうのは多分、根本的に間違っている。周りを含めた層の厚さが、日本のロボット産業の強みだと思う。
-制御システム
いわゆる組み込み系に属するところになる。OSSも含めて割と選択肢もそこそこ増えており、PoCレベルからある程度プロダクションレベルまでそろいつつあるように見える。特に決定的に足りないというものはないように見える。探すと「こんなものまであるのか」というぐらいまである。玉石混交という話をあるが、逆に玉も石もあるというのは強い。
-アプリケーション
残念ながら、ここが決定的にない。より正確な言い方をすると「ロボット業界の人が想定するアプリケーションと一定の業務で導入するために必要なアプリケーションに大きな溝がある」という言い方になる。今のロボット導入の考え方は簡単に言うと「超高機能な、移動する自動販売機」の延長線上にある。または、「頭のない鉄腕アトム」と言ってもよい。(まぁトレンドの自動運転も似たようなところがあるように見えるが・・・)
欠けている「インテグレーション」
まずもってロボットな現場では、我々の言うシステム・インテグレーションという考え方、それ自体がほぼ存在しない。「アプリケーション」という観点も「自動販売機の組み込み系制御ソフト的なもの」の思考の域を出ていない。要するに「複雑な業務例外処理」は考慮に入っていない。
(まずいきなり留保だが、ロボット業界にも「システム・インテグレーション」という言葉はあるが、それはSI業界がいうところのシステム・インテグレーションとは似て非なるものだ。後述するが、それがまたよろしくないギャップになる。)
インテグレーションの観点で見ると、経験的には、この例外処理はシステム全体のコストの70%~80%にもなることがあるが、現状の「ロボット業界」はこのコストまったく見ていない。というか「知らない」というまさにこの一言に尽きる感じだ。
いままでこの手の話は「制御系・実行系」とバックエンドまたは「業務系」と完全に分けてきた。特に制御系は場合によっては人の生死に関わることもあるので、できるだけ例外系は排除し品質に振るというのが筋で、その分、例外のしわ寄せは業務系+人手で吸収というのが王道だった。これは社会インフラにしろ、運輸交通にしろ、製造業にしろ、普通にある話だ。だから、業務例外的なものはロボット系では考慮の外です、は特別な話ではなく、普通だ。これは「それで世の中が回っていたから、こうなっている」という話でしかない。
現状のロボット関係の企業・人材は、どうしても制御・実行系に属することが多く、その意味で「業務系」については、考慮しないというか、わからんというか、要するに「なんとかなる」と思っているフシがある。この状況はデスマ経験者ならば筋肉反射で理解するレベルだが、この状態で介護なり流通の現場なりに放り込もうとするので、ほぼ100%使い物にならない。ほぼすべての案件で「とりあえず一回やってみて今後は要検討=お蔵入り」状態でスタックする。
「AI」という言葉による隠蔽
このインテグレーション、またはアプリケーション、設計・実装のところ都合よく隠蔽する言葉になったのが、実は『AI』だ。ロボットに限らず、今の現状の「AI」は都合よくインテグレーションコストを吸収してくれるものという「ぼんやりとした希望的観測」が根底にあり、たとえばRPAあたりはそういう雰囲気を醸し出すため、誤解しか発生せず、結果大体うまくいかない。
この意味ではAIという言葉は、非常にマイナスになっていると思う。やるべきことをやらなくてすむという非常に魅惑的な幻想を提供するからだ。翻って、これはIT業界ではよいことは何もない。炎上はもちろん、失望感が蔓延し、市場も広がらず、結果、本来であればユーザ・ベンダーともに享受できたはずのトータルメリットがなくなってしまう。
・・・よくバズワードで資金が集まり、IT市場が活性化するという意見も聞くが、不正確なバズワードのなれの果ては大きな失望と不信であり、結果としての市場の喪失だ。失敗までのタイムスパンが長ければ、時間差を利用して一種のバブルを稼ぐことも可能であろうが、情報伝達のスピードが速い現状ではそういう取り込み詐欺的な煽りは通用しない。バズワード歓迎なIT屋とマスコミは全力で反省してほしい。まじで。割とまじで。「ロボット+AI」はこのままでは不幸をまき散らすだけだ。期待が大きいだけに、これはむしろ犯罪的ともいえると思う。
いずれにしろ、真面目に考えると、この「インテグレーション」の部分をどうするか?が今後の焦点になる。これは今までのSIとは、おそらく似て非なるものになる気がする。
(なお、ここで最初の留保に戻るがロボット業界での「システム・インテグレーション」は「ロボットのシステム(これはロボットの対象領域に閉じた系のこと)」のインテグレーションになっており、前述のような「業務例外系」については考慮していないことが多い。)
そもそもどういうインテグレーションが必要なのか。
さっぱりわからない、というのが普通だと思う。
要件定義の最初の出だしの業務要件の洗い出しからして難航を極める。As-IsやTo-Beのような古典的な王道分析ですら、そもそも何がAs-Isかは相変わらず整理がやっかいだし、いわんやロボットを導入後にあるべき姿のTo-Beモデルを詳細に業務側から詰めろ、言われても「想像と妄想の産物」をTo-Beにしろ、という話にしかならない。
ソフトウェアのように軟性な仕組みであれば、アジャイル的な手法も有効だと思うが、いかんせんガチガチのハードだ。ちょっといろいろ変えてみましょうにも限界しかない。コストや時間もバカにならない。加えて、前述の通り、そもそもロボットの作り手にそういう経験が多くない上に、IT業界が「AIブーム」を造成したため、ユーザサイドも「いや、AIがなんとかしてくれるんでしょう?」という謎の期待もあり、期待ギャップは絶賛大拡大中だ。壁はエベレストより高く、溝はマリアナ海溝より深い。
さらに、そもそもインテグレーションコストがどのくらいで、どう吸収するかわからないという問題も発生する。これはバカにならない。しっかり要件定義から始めて運用まで考えると、案件あたりでSIコストは、数千万は普通だし、ちょっと間違ったらすぐに億は超えるだろう。
ということで。ロボット導入の話を流通と介護に限定して自分の考えを述べる。
まぁ普通に考えると「絶望的に打つ手がないので、どうしようもないですね」
で、おしまいです。だが、そうも言っていられないので、以下の自分のなりの解決案を「想像」してみる。なお、以下は僕の想像(というか目撃というかいろいろあってアレだ)であるけれども、現実にこの想像を実現しようしている人たちもいる。
現実の「ロボットとユーザ」のギャップの埋め方
-進め方の問題
普通のSIのやり方であれば、現状の業務分析を行い、問題点を洗い出し、課題を解決するようにITの技術を導入する、というのが通常の王道になる。現行の問題点を解決するようにロボットを導入すればよい、ということになる。それでは、ロボット導入のSIにおいて、流通の現場なり、介護の現場でこれをやってうまくいくか、というと多分うまくいかない。
理由はいろいろあるが、大きなものは、まず単純にロボットを導入すれば、「小売・介護の現場の問題点が解決するか?」というと「解決しない」からだ。業務分析をして、課題解決にロボットいれましょう、とやると多分、結論は「当面は入れない方がいいですね」ということになる。
いままでのITは、IT側を人間に寄せてきた。うまく現場を回すためには、想定外に発生するトラブルや問題点を人の創意工夫で解消する方が効率がよいからだ。その邪魔をしないようにITをうまくアジャストして導入するほうがトータルでのビジネスのスループットは出る。ありがちのERPのコンサルがいいそうな「業務をERPに寄せろ」というのは、正解ではないことは多くの人が知っている。品質とスループットの背反する要求を、多少コストかけてもいいから同時に解決するという方向に倒してきたのが日本企業のやり方だ。このために、SIの要件定義から実装・リリースまでの流れは、ITを業務に寄せる、という考えかたを根底に置いて進められている。
残念ながらこの方法は現状の解決にはならない。
理由は大きくふたつだ。ひとつはロボット系は言われているほど万能ではない。制約の方が多い。これは現状ではどんなに頑張ってもやれることに限界があるということだ。たとえば、一般には信じられないとおもうが「双腕でものをちゃんと掴んで運ぶ」ということですら現行の技術ではやっとこなんとかできるのが最近だったりする。それでも人間の水準には全然遠い。(多くのロボットが単腕であるのは、言われてみればそうだなと思い当たる人が多いと思う。んで、実は双腕の方が精度・効率がよい。無用の用とはよく言ったもので、局所的には無意味だが、対象領域の取りようによっては有意ということは普通に頻繁にある。)こんなことはいくらでもあって、現在の小売・介護の業務の問題点を解決するには、今の技術水準のロボットでは帯にも襷にも短い。ようするにITを人側に寄せる、ということが極端に困難ということだ。
もうひとつはそもそもロボットでサポートすれば、どうにかなるというレベルの人手不足の水準はとっくの昔に通り越しているということだ。現状では際限なく時給もあげても満足にアルバイトすら集まらないというのが現状になっている。ロボットで人手不足を補う、というのは補うべきベースがあるのが前提であり、そもそもその前提が崩れつつある。
つまり、既存のSIの方法で、業務(小売・介護の現場)とIT(ロボット)のギャップを埋めようとしても埋まらない、埋めようがない、のが現状だ。なので、普通は「ロボット云々の前にやることあるだろ」っていう結論になる。
で、どうするか?という話だが、これは本末転倒だが、「SIをロボットに合わせて」行う、という逆の発想に倒すしかない。要するにロボット様が働きやすいように環境をつくって、人様はそのサポートをせい、という方向に「業務側」をインテグレーションするということだ。もちろん、サポートの人員は可能な限りゼロにする。
要するにロボット前提で、ビジネス・フォーマットから作り直せ、そのフォーマットからは可能な限り人間は排除しろ、ということだ。小売でも介護でもだ。んで、人間はなにするの?という話だが、個人的には「物質的なハードウェアなサービス」ではなく「精神的・メンタル・気持ちとかそんな感じのソフトウェアなサービス」に徹底した方がいいと思っている。また、ロボットのサポートする人間は一部を除けばプロである必要もないと思う。
つまり、必要なSIは従来型のSIではなく、従来とはちがうフォーマットなりオペレーションを根本的に作り上げるSIが必要になる。要するに”暴論”を言えば、小売/介護で真面目にロボットとか入れるなら「可能な限り人がいない店舗・介護施設をつくれ」ってことです。中途半端にロボット的なものを入れたところで、余計なしわ寄せが業務側にきて、結局、「なんのためにいれたのかよくわからない」ということになる、というか、すでになりつつある。
結局のところの今の結論
今のロボット導入は基本線は「便利ツール」の延長でしかない。したがって人手のリプレースにはならないし、結局、業務からの組み上げがないので、コスト増+人件費増になり、時代の要請には逆行する。本格的に人手不足に対応させるには、フォーマットレベルからの業態変更が必須になる。
もっともこれは本来的にはそもそもロボット導入以前の話かもしれない。人手を減らして、ロボット的なものに移行するということは、俯瞰でみれば、労働集約的な産業構造を資本集約的な産業構造に大幅に変更しろ、という要請にも繋がるだろう。そこまで行かなければ、継続的に発生する、ロボットの導入費はもちろん、メンテナンスコスト・SIコストはペイしないだろう。確かに部分的には今後は、就労人口減から人員確保が頭打ちになるので、必然的にそうなるという側面はある。けれども、それ以上に経営主体・現場の意識を変化させないといけない。そうでなければ、人手減の中での無策という意味で、とどのつまりの「政策不在」というルサンチマン的な被害者意識が積み上がるだけだろう。
日本に産業史で、「労働集約的な産業構造を資本集約的な産業構造に変更」の代表例は、実は運輸・トランスポーテーションだ。要するに馬車馬・飛脚から車・鉄道になった。皮肉なことに象徴的なアナロジーにもなるが、すなわち、今の流通・介護業界は、「馬車馬・飛脚の時代」なんで、「車・鉄道の時代」にしないと無理よ、とまぁこんな感じなのかもしれない。
ロボット・AIでの「インテグレーションの不在」は、現場・経営・政策の同床異夢の成れの果てというよりは、置き去りになっていた流通・介護業界の産業構造の根源的な欠陥が、たまたま顕在化した「結果」だけかもしれない。これを奇貨にして、人口減の中での、自らのあり方そのものを既存の延長にすがるのではなく、新たに問い直すということが可能になるのであれば、その意味では「ロボット・AIでバラ色」という取り込み詐欺的なITマーケも多少の意味はあるのかもしれない。ま、そんな感じ。
本年もよろしく。でわでわ。