リファクタリングの事象の地平線
これは経験則なのですが、ある程度を超えたスパゲッティコードはリファクタリングを試みても状況が改善しなくなります。
— なぎせ ゆうき (@nagise) 2023年6月27日
ブラックホールから光が脱出できない事象の地平線になぞらえ、これをソフトウェア品質における事象の地平線と言い(ません
リファクタリングの事象の地平線という比喩について解説をしておきます。
前提知識として リファクタリングの価値の考察 - プログラマーの脳みそ での議論を参照していただけるとありがたいです。
事象の地平線とは
事象の地平線というのは天文学用語でシュバルツシルト面などとも呼ばれます。超大雑把にいえば、ブラックホールのまわりのここから中に入ると光でさえも出ることはできないぞ、というラインです。
つまり、比喩としてはこの中に落ち込むと二度と脱出できないぞ、ということです。リファクタリングの力ではどうやってもソフトウェアの保守性を上げられない状態に陥って脱出できないという主張です。
リファクタリングのおさらい
リファクタリングの原義について再確認しておきましょう。バイブルとされるマーチン・ファウラー著「リファクタリング」では次のように書かれています。
リファクタリングとは、ソフトウェアの外部的振る舞いを保ったままで、内部の構造を改善していく作業を指します。
原義としてリファクタリングは外部的な振る舞い、つまるところ挙動を変えてはいけません。ソフトウェアというものは、プログラムというものは、同じような挙動をするものであっても様々な書き方ができるものです。その多数の選択肢の中から、いまのコードとは別の選択肢に切り替えるという捉え方もできるでしょう。より現在の状況に即したコードに切り替える。
単にコードを書き直すことは「リライト」です。外的振舞いを保って初めて「リファクタリング」と言える。そうした「リライト」と「リファクタリング」を本稿では区別します。
リファクタリングをする動機は、単にコードが稚拙だったからとは限りません。ソフトウェアの機能拡張をしたいとなったとき、今まではなんら問題なかったソースコードが、突如、都合の悪いものになってしまうことがあります。そもそも機能拡張というのは今まではなかった話ですから、その存在しなかった拡張に備えた都合の良い設計になっていないことが往々にしてある。もし未来が予め見えていたなら、より都合の良い選択肢を取ることができたのに。そうした後悔を取り返すことがリファクタリングの動機のひとつとしてあります。
リファクタリングと自動テスト
書籍リファクタリングでは第4章にて自動テストについて解説がされています。JUnitについて取り上げられていますが、しかし、書籍リファクタリングではJUnitのテストコードを前提にリファクタリングの作業が書かれているわけではありません。
これは多分に時代背景によるもので、JUnitによる自動テストがまだ十分な市民権を得てはいなかったことが挙げられるでしょう。しかし、現代にリファクタリングをやるのであれば、JUnitなど自動テストツールによる補助を使わない手はない。およそ「必須」のツールと認識されているのではないでしょうか。
大きなステップ
なぜリファクタリングによって保守性を上げられなくなるのか。その主張の中心にあるのは「大きなステップ」です。
そもそもリファクタリングは「小さなステップ」で行います。書籍リファクタリングはIDEによる機械的なリファクタリングのサポートのない時代の想定で書かれており(原書は1999年。第14章にわずかばかりリファクタリングツールについて記載があります)手動でリファクタリングを行うためのかなり細かい手順が記載されています。
本来、リファクタリングというのは小さなステップで動作確認を行いながら慎重に進めるものなのです。そうでないと「外部的振る舞いを保」てないからです。現在の状況から、外部的振る舞いを保った最寄りの飛び石に飛び乗るように進めていきます。
データ構造や、クラス構造といったものや、根底のアーキテクチャのようなところに手を加えようとすると、外部的振る舞いを保った最寄りの飛び石が、とてもジャンプして届くような位置に存在しなくなることがあります。「ここに手を加えるには、参照箇所1000箇所を一斉に変更するしかないな」ということが生じます。こうした状況を「小さなステップ」に対して「大きなステップ」「ビッグステップ」などと表現しました。
この「大きなステップ」が人間の能力の限界を超えたとき、それはもはやリファクタリング不能な、改善不能なソースコードであると言えましょう。これが脱出できない事象の地平線とたとえられる代物です。
※この「大きなステップ」「ビッグステップ」という表現は、どこかで見たような気がしていて、私のオリジナルではないつもりなのですが、この語義での利用は出典を探してもうまく見つからないのです。情報があれば教えていただけると幸いです。
リファクタリングのコスト論
リファクタリングのコストとその採算性については リファクタリングの価値の考察 - プログラマーの脳みそ にて詳しく議論しています。端的には、リファクタリングは品質特性の「保守性(maintainability)」に作用し、保守性の価値は、そのビジネス規模に依存するというものです。
一般的に、リファクタリングするべきか、しないべきか、という議論はこうしたコスト論に基づいた判断の話をしているかと思います。本稿の主張はそうではない。
「大きなステップ」がある限界値を超えると、本質的にリファクタリングそのものが不可能になるのだ、という主張です。
判別困難
リファクタリング不可能なソースコードが存在するというのが本稿の論旨なのですが、しかしおそらくソースコードを表面的に見たときに、このソースコードはリファクタリング不可能な状態にあるかどうかは判別困難でしょう。
なので、事前の予測としてリファクタリングにこのぐらいのコストがかかりそうだ(≒労力がかかりそうだ)と見積もって、先に述べたような採算を考慮してGoサインが出ることがあります。しかし忘れないでください。リファクタリング不可能なソースコードというものが存在しうるということを。
もし、事前の予想に反して、リファクタリングが困難であるならば、進捗が思わしくないならば、このことを思い出してください。そして、目の前の「大きなステップ」があまりにも大きいのであれば、諦めて撤退することを考えてください。損切りすることを選択肢として考えてください。もう少し粘ればいける、などと考えると被害は広がるばかりです。顧客からは噓つき呼ばわりされることすらあります。
大きなステップを乗り越えるもの
大きなステップは、その大きさによっては人間には克服不可能なものであると主張しました。もしこれを乗り越える可能性があるとすれば、それは機械によるパワーでしょう。
例えば、大量に参照されている、そして同名の別の変数も存在するような変数のリネームなんてリファクタリングは、およそ昔は不可能でした。しかし、現代のIDEなどの機械補助は、こうした人間には困難なリネームのリファクタリングをいともたやすく行ってくれます。
膨大な量を、漏れなく、正確に処理をするという、およそ人間には不得意な作業ですが、機械がそれを可能にしてくれるかもしれません。現代ではデータ構造や、クラス構造といったものや、根底のアーキテクチャのようなところに手を加えようとするならば、それぞれの箇所で個別に人間の判断を要するため、機械的な一括処理は困難ですが、そうした判断をも未来のAIはうまく処理してくれるかもしれません。
Project Valhalla 2023
2023/03/30 にやったJava仕様勉強会の動画が公開されました。当日はJavaのマスコットDuke風の服で臨みました(どうでもいい裏情報)
セッション資料もアップロードしたので参考にしてください。
いずれも 2023年3月時点での情報です。JEPもドラフト版だったりするので、将来的に変更が入る可能性が高いことをお断りしておきます。本稿では勉強会のセッション内容に加えて、セッション時点で追従できていなかった変更点や、勉強会での指摘を踏まえてフォローアップした内容を含みます。
もしもValhalla世界でJava入門したら
ここでは、Valhalla導入後のJava世界だと入門者視点でどのように変わるのかというアプローチをしています。まず、Javaのデータ型は大きくふたつに分類できて、Identity Objects と Value Objects です。
| nullの使用 | 不変性 | 同値判定 | ||
| Identity Objects | Record | 可 | 不変 | equals |
| Class | 可 | 可変 | equals | |
| Interface | 可 | 可変 | equals | |
| Array | 可 | 可変 | Arrays.deepEquals | |
| Enum* | 可 | 不変 | == | |
| Value Objects | Record | 可 | 不変 | == |
| Class | 可 | 不変 | == | |
| Primitive | 不可 | 不変 | == |
どう違うの?というと割と難しくて、パッと見は大きな違いを感じないかもしれません。
言語的な定義を言ってしまえば、 class宣言で identity class と宣言されていればそのインスタンスは Identity Objects ですし、value class と宣言されていればそのインスタンスは Value Objects です。でも、そんな説明では納得されないことでしょう。
Value Objects はメモリ上に直接展開可能なデータで、メモリレイアウトを効率化することができます。

しかしこれは、あくまでJavaVMの中の話で、プログラミング言語Javaを扱うプログラマー視点で見た場合、オブジェクトの可変性 / 不変性という特性や、同値判定をする際に equalsメソッドを使うか、==演算子を使うかという形でしか実感しにくいものであろうと思います。
Valhallaのスローガンとして出てくる
Codes like a class, works like an int.
クラスのように書き、intのように動く、という標語は、反面、その違いを分かりにくいものとしています。
まあ、ライトユースでは雰囲気でコードを書いてもだいたいいい感じになるんじゃないかな。
プリミティブ型の位置づけ
プリミティブ型は Value Objectsの一部という位置づけになります。
プリミティブ型については JEP 402: Enhanced Primitive Boxing (Preview) にて検討されています。このJEP 402で目を引くのは以下の部分でしょうか。
int i = 12; int iSize = i.SIZE; double iAsDouble = i.doubleValue(); Supplier<String> iSupp = i::toString;
int 型変数に対して、あたかも普通の参照型のようにメソッド呼び出しをしているかのように記述することができます。これは、裏の仕組みとしてはラッパー型のIntegerの該当メソッドを呼ぶような仕組みを想定しているようですが、これにより言語の表面上はプリミティブ型も参照型も同じように扱えるように見えるのではないでしょうか。
まあ演算子で操作できるのはプリミティブ型(と一部のクラス)の特権という感じでしょうけども。
ジェネリクスでも List<int>という記述が可能なように拡張しようとしています。こちらの裏の仕組みは後述します。
JavaVM の大改造
Valhalla後のJavaを表層的に見れば、言語がリファクタリングされて綺麗になったね、めでたしめでたしといったところなのですが、その裏方は地獄です。
Project Valhalla は 2014年に発表されました。Java8がリリースされた後のJavaOne 2014 San Franciscoが舞台です。当時の様子は櫻庭さんの記事を参照してください。
2023年4月現在参照可能な JavaVM の Valhalla での変更点の解説セッションは JVM Language Summit 2019 のものが分かりやすいでしょうか。
2014年に発表されてすでに2023年ですから随分と時間がかかっていますね。たくさんのプロトタイピングとたくさんの教訓から掘り下げているといったことが語られています。
Early Access Release
Valhalla の Java VM のプロトタイプ版がリリースされています。2023年4月現在のバージョンはLW-4 となっています。ダウンロードして動かすこともできますが、主にJava VM側の実証プロトタイプで、プログラミング言語側のUniversal Genericsといった面白い部分は未実装です。jshellも制限があるようなので、機能を確認したい場合はjavacでコンパイルしてjavaで実行した方が良さそうです。
JavaVM のプロトタイピング
Valhalla は既存の JavaVM に対して大きなインパクトの修正を加える必要が生じます。そのため、まずプロトタイプを開発して検証を行いました。最初のプロトタイプが "Q-World" と呼ばれるものです。この"Q"とはValue型だけを表す型のことで、既存のプリミティブ型や参照型とは別に独立のValue型を作るという方針のものでした。これは言わば「ユーザー定義のプリミティブ型を作る」といったアプローチです。
このプロトタイプは機能することはしたのですが、プロトタイプを実装することで問題もまた見えてきました。Q-Worldの問題点として
- プリミティブ型と参照型の分断をさらに大きくする
- 加えて更なるボクシングも必要になる
- 苦痛を伴うマイグレーション
- 苦痛を伴う特殊化。配列は特に痛い
といったものが挙げられています。
そこで方針を転換して作られたプロトタイプが "L-World" というものです。この"L"とは既存の参照型のことで、しばしばスタックトレースなどで見かける LJava/lang/Object といった型表現の先頭の"L"です。つまり、Value型をjava.lang.Objectを継承した型として扱うアプローチです。
- バイトコードは既存の a* を用いる (これはaload, astore といったバイトコードを指しています)
- java.lang.Objectを継承した型として扱う
- Value型の配列は Object[] の継承型として扱う
- プログラム言語のモデルはよりよくなるが、VMへのインパクトはより大きくなる
といったことが先の動画で解説されています。
互換性
Project Valhalla では既存のJavaとの互換性を維持する方針が示されています。この背景については Background: How We Got the Generics We Have という文章があります。これは2004年にリリースされたJava5のときに、いかにして互換性を保ちながらジェネリクスを導入したのか?ということについて書かれています。この文章はとてもエモいと私は思っていて、機会を改めて解説したいところですが、要点を超訳すると
Goal: Gradual migration compatibility
ゴール: 段階的な移行の互換性
ということになります。つまり、バイナリ互換性のない分断された言語仕様追加では、その断絶の前後で、ソースコードになんの変更がなくとも、すべてのクラスを一斉に再コンパイルする「フラグの日」が必要になります。
java.util.ArrayListのようなコアAPIのクラスを変更するならば、世界中全てのJavaコードを一斉に再コンパイルする必要があります。あるいは、Java 1.4 まで用のクラスとして永遠にとどめおく必要があります。
Javaは動的リンク、つまり実行時にJavaVMによって外部のjarファイルが読み込まれたりする動きをしますから、この「フラグの日」というのはより強い嫌悪感をもたらしました。(補足するなら当時はまだJava Appletが活きていましたし、Java VM 間のRMIによる呼び出しのようなものも活きていてネットワークを介して複数のJavaVMが協調動作するような想定も強く存在していました)
そうした20年前の事例を踏まえて、Valhallaでも互換性を保ちながら、徐々に移行する道が選ばれたのです。
Valhalla のJEPs
Project Valhallaの中核となるJEPは4つあります。
- JEP draft: Value Objects (Preview)
- JEP 401: Implicit Value Object Creation (Preview) 旧 User-defined Primitives
- JEP 402: Enhanced Primitive Boxing (Preview)
- JEP draft: Universal Generics (Preview) 旧 Specialized Generics
セッションをやった当日(2023年3月30日)の朝に参照していたJEPのタイトルが変更になるハプニングがありました。本稿執筆時点で再度確認しているのですが、また名前が変わっている……。現時点で活発に更新がされていることの証左でもありましょう。過去の資料を照会する時には名称変更にお気を付けください。
JEP401, JEP402 は既にJEPの番号がついていますが、 Value Objects や Universal Generics はまだドラフト版で正式なJEPが発番されていません。Java VM 部分が固まってきたため、ようやく上モノの言語仕様が進むようになってきたと見るべきでしょうか。
また、関連JEPとして以下のものがValhalla公式ページには挙げられています。
- JEP 181: Nest-Based Access Control (delivered in 11)
- JEP 309: Dynamic Class-File Constants (delivered in 11)
- JEP 334: JVM Constants API (delivered in 12)
- JEP 371: Hidden Classes (delivered in 15)
- JEP 390: Warnings for Value-Based Classes (delivered in 16)
- Better-defined JVM class file validation (draft)
これらはリリース済みのものが多くあります。こうした部分でも徐々に進んでいることが伺えるでしょう。
型の再整理
Valhalla では既存のプリミティブ型と参照型という枠組みを、再整理してJava言語をリファクタリングしようという試みをしています。


この図は The Language Model というBackground Documentsで出てくるのですが、上の図の既存のJavaのデータ型をValhallaでは下の図のようにしますよ、という話です。
先に挙げた表を再掲しますが
| nullの使用 | 不変性 | 同値判定 | ||
| Identity Objects | Record | 可 | 不変 | equals |
| Class | 可 | 可変 | equals | |
| Interface | 可 | 可変 | equals | |
| Array | 可 | 可変 | Arrays.deepEquals | |
| Enum* | 可 | 不変 | == | |
| Value Objects | Record | 可 | 不変 | == |
| Class | 可 | 不変 | == | |
| Primitive | 不可 | 不変 | == |
既存の型を大きく Identity Objects と Value Objects に再分類しようとしています。なお、Enumについては理論的にはValue型にできるものですが、java.lang.Enumを継承する構成上、Identity Objects になっているという注釈がありました。
Record については Identity にも Value にもなれますが、いずれも不変です。フィールドにIdentity を含んでいると Identity にせざるを得ないといった面倒くさい考慮事項があります。
配列は "L-World" では既存の配列の性質を引き継いでいます。配列の仕様にまつわる型システム的な不都合がいろいろとあるのですが、そのあたりは互換を維持する方向で梃入れはしない方針のようです。
プリミティブ型は Value Objects のひとつという位置に据えられ、プリミティブ型と参照型の分断を軽減しようと試みられています。
Value Objects
クラス宣言に value 識別子を加えて宣言するとそのクラスのインスタンスは Value Objects になります。
クラス宣言に identity 識別子を加えて宣言するとそのクラスのインスタンスは Identity Objects になります。(既存の参照型を使いたい場合はこちら)
Value Objectの利点としては == で値比較ができるようになる点が挙げられます。
また、value 宣言した場合の主な制約は
- クラスは暗黙にfinalとなり継承できなくなります
- すべてのフィールドは暗黙にfinalとなり、コンストラクター(ないし初期化子)で1度だけ値を設定しなければなりません
- identityクラスを拡張またはidentity インターフェースを実装して Valueクラスを作ることはできません
- コンストラクターでthisやsuperを使うことはできません。インスタンスの作成は、スーパークラスの初期化コードを実行せずに行われます
- synchronized メソッドを宣言できません
- finalize() メソッドを宣言できません(おそらく)
- コンストラクタではthisを参照できません(例外事項があるがここでは省略)
といったものとなっています。これらは今後、言語仕様を詰めていく段階で変更になる可能性があります。
既存の value ないし identity 識別子のついていないコードは、およそ identity クラスになると思ってよいようです。(例外事例があるようなのですが複雑でよくわかりません……)
このあたりは言語仕様の差分に詳細な記載があります。the specification changes がリンク切れなので少し古い版へのリンクを貼っておきます。 8.1.1.5 identity and value Classes
JEP 401: Implicit Value Object Creation
- JEP 401: Implicit Value Object Creation (Preview) 旧 User-defined Primitives
"Q-World"のような古いValhallaの提案では、ユーザー定義のプリミティブ型を作成できるような提案となっていました。現在の "L-World" になってこの提案は大きく修正されたように思います。
JEP 401 はざっくりいえば、Value型のデフォルト値の動きを規定するようなJEPで、
public implicit Range();
といったように implicit キーワードをつけたデフォルトコンストラクタを記述することで、各フィールドをデフォルト値としたValue型のインスタンスを生成します。(構文はあくまで仮のものです)
また、 Null-Restricted and Nullable Types (Preview) に依存するのですが、nullを許容しない型についての検討があるようです。しかし、このJEPはドラフト 8303099 なのですがリンク切れになっており、おそらく再検討されているのではないかと思います。
JEPは消えていますが、何が書いてあったかというと ValhallaのML に記載があったので紹介しておきます。
'Foo!' refers to a non-null Foo, and 'Foo?' refers to a Foo or null
'Foo!' は nullではないFoo を参照し、'Foo?' は Foo または null を参照します。
Type variable types have nullness, too. Besides 'T!' and 'T?', there's also a "parametric" 'T*' that represents "whatever nullness is provided by the type argument".
型変数の型にも nullness があります。 「T!」のほかに および「T?」、「型引数によって提供される nullness が何であれ」を表す「パラメトリックな」「T*」もあります。
Kotlinの構文に雰囲気は似ているでしょうか。このあたりはおそらく大きく変更が入ることでしょう。あまり期待しすぎずに様子を見ましょう。
JEP 401 でもうひとつ触れられていることは non-atomic についてで、背景を説明するのが難しいのですが、端的に言えばマルチスレッド下で同時にValue型の値を作成するようなケースで、“Atomicity”(原子性/不可分性)を犠牲にしてパフォーマンスを出すオプションを用意しようというテーマです。本稿では深入りしません。
JEP 402: Enhanced Primitive Boxing
プリミティブ型を参照型のようにあつかう言語拡張です。プリミティブ型変数に対して、"."でメソッド呼び出しを行ったり、メソッド参照を用いたりすることができます。
int i = 12; int iSize = i.SIZE; double iAsDouble = i.doubleValue(); Supplier<String> iSupp = i::toString;
これにより、プリミティブ型と参照型の分断を軽減しようという試みのようです。仕組みとしては、ラッパー型のメソッドを呼び出すようです。
また、ジェネリクスの型変数に対してもプリミティブ型を用いれるようにします。この仕組みとしては、int を Integer! 型 にボクシングします。この ! は先に照会した Null-Restricted and Nullable Types (Preview) での null を許容しない型のことです。
この辺は個人的には好きなジャンルなのですが、深入りすると複雑になるので割愛します。
Universal Generics
- JEP draft: Universal Generics (Preview) 旧 Specialized Generics
端的に言えば、Value型と従来の参照型にまたがるユニバーサルなジェネリクスという内容です。
このへんのジャンルは私の好物なのですが、しかし具体的なところに踏み込むととにかく複雑かつマニアックになるので本稿では割愛します。
このJEPドラフトでは Collection<Point.ref> といったnull許容型の型変数を表す記法が暫定的に用いられています。ここでは Null-Restricted and Nullable Types (Preview) が参照されておらず、このあたりの統一的な方向性をどうするかといった部分はまだまだこれからなのでしょう。
null 許容型、非許容型が扱えるようになると型システムマニアの人達は狂喜するところなのですが。
マウンティングの語源調査の仕方
前回、思い出話として
を書いたのだが、その中でネットスラングの「マウンティング」について、初出が
であるということを書いた。この記事は 2008年9月20日で、以下の用例が見られる。
そんなテクニックはいかに相手のニホンザルを押さえ込んでマウンティングを成功させるかというテクニックでしかない。そんなことをやったところで疑問はなんら解決しないし、誤った意見をこうした手法で押し通しでもした日には、後で大きな惨劇が起こりかねない。勝った負けたなどと言っていても議論は進展しないのである。
これは明確なエビデンスで、この時点でこのような用例があった、というのはひとつの道標となる。
ここで、「筆者が発案したというのは本当か?」「より古い用例はないか?」という疑問が生じることだろう。では、そうした疑問が生じたときにどのように対処すればよいか。
書籍での用例
書籍では 瀧波ユカリ・犬山紙子(2014)『女は笑顔で殴りあう : マウンティング女子の実態』筑摩書房 が最古とされており、インターネット上のネットスラングが先行して用いられていることは既知の通りである。この書籍を筆者が読んで着想を得て2008年に上述の記述をするにはタイムマシンが必要になる。
簡易検索結果|「マウンティング」に一致する資料: 4件中1から3件目|国立国会図書館サーチ
国会図書館の検索では出版年別のカテゴリがあるので、古い時代の検索結果を確認していただきたい。上述の2008年のネットスラングより前に先行の用例があれば、それを見て剽窃したのだろうというシナリオもあるいは考えられることになる。
注意しなくてはならないのは、2008年より前に生物学的な「マウンティング」という用語が既にあったことは周知の事実であり前提である。なので、それを人と人との間の関係性として用いた用例を見出さなければならないという点である。
※注 追記参照。より古い用例の情報を頂いた。まさに「マウンティング」というテーマそのものについて記述した本というわけではないが、用例として利用がある本が見つかったというのは特記するべきことだろう。
プログラマーの脳みそでの用例
ブログ「プログラマーの脳みそ」では2008年9月20日の初出からその時期に集中的に利用が見られる。ここでは日付とタイトルのみを挙げる。
- 2008年9月20日
- 2008年9月22日
- 2008年9月23日
- 2008年9月25日 不良がいいことをすると凄くいい奴に見えるメソッド - プログラマーの脳みそ
- 2008年9月26日 人間考の難しさ - プログラマーの脳みそ
思いつきで単一使用したわけでなく、ここで考察がされ人間関係におけるマウンティングという概念を見出したことが伺える。
検索エンジンで古い用例を探す
例えばGoogleだと、「ツール」から検索対象となる年月日を指定することができる。

インターネット上の用例を探す場合はこの機能が便利だが、時折、新しい記事が古い時期の記事と誤認されることがある点に注意。該当サイトは実際に2006年に書かれたものではない。

技術的には、ページを表示しようとHTTPリクエストを送った際の応答にこのコンテンツは何月何日のものです、という日時が入っているのだが、Googleのロボットがサーバーに情報収集に赴いた時に変な値がかえるようになっていたのだと思われる。
ときどきこうした事例もあるので、検索でみつけた各ページを実際に確認して用例としても合致しているかを確認していく。
2010年以前の用例を探すと分かるが、犬のマウンティングや、猿のマウンティングについての用例ばかりで、現代のネットスラングの人が人に対して優位をアピールする行為を指して「マウンティング」を用いている例は見られない。先の2008年の用例ぐらいである。候補を見つけたらぜひブログを書くなりして発表して欲しい。(注:情報をいただいた。追記参照)
2008年以後、初期のネットスラングとしての「マウンティング」の用例としては、2011年7月5日の内田樹氏による 暴言と知性について - 内田樹の研究室 などが挙げられる。
今回彼が辞職することになったのは、政府と自治体の相互的な信頼関係を構築するための場で、彼が「マウンティング」にその有限な資源を優先的に割いたという政治判断の誤りによる。
こうした初期の用例は、ネットスラングとしての「マウンティング」の黎明期を捉える上では貴重な資料となるだろう。
格闘技用語について
現代ではネットスラングの「マウンティング」の類語として「マウントをとる」という言葉がある。こちらの用例はどうか。
格闘技用語としての「マウントをとる」についてはネット上での検索では用例を遡ることが案外難しく、国会図書館の検索ではなかなか用例を見出せない。
2002年の書籍で「マウントポジション」の用例があることはみつけることができた
中井祐樹柔術バイブル (クエスト): 2002|書誌詳細|国立国会図書館サーチ
筆者の調べでは1995年のヒクソン・グレイシーの試合についての記述でマウントポジション、マウントという表現がある。この記述が当時近くに書かれたものなのか、後に書かれたものなのかは少し判別しにくい。
静寂なる戦い【中井祐樹vsヒクソン・グレイシー】 両者は何を想う!?
ちなみに日本のインターネットの普及は1995年末のWindows95発売からで、それ以前の時代のインターネットコンテンツはとても少ない。当時のコンテンツそのものではなくとも、ブログサービス移転などに伴い転記され残されているものである可能性もある。あるいは雑誌など紙媒体などに書かれたものがWeb公開されているようなケースもある。一概に言えないが、1995年当時に格闘技用語として「マウント」という概念があったことは筆者は疑っていない。エビデンスとしての傍証を出すのが難しいという話である。
うろ覚えではあるが、マウントポジションについては川原正敏(1987-1996)『修羅の門』で見た覚えがある。そのぐらいの時期には格闘技用語としての「マウントポジション」「マウントをとる」は認知されていたと言えるのではないか。
格闘技用語からの転用の可能性は?
さて、ここで重要なポイントとして格闘技用語では「マウントポジション」ないし「マウントをとる」といった表現である点。決して「マウンティング」という言い方ではないのだ。マウントポジションをとることを指して「マウンティング」と呼んでいる用例は少なくとも筆者が調査している間には見かけなかった。
ネットスラングの「マウンティング」の語源を格闘技用語の「マウント」とする説は、なぜ「マウント」ではなく「マウンティング」という表現で用いられるのか?という疑問に答えなくてはならない。
筆者の考えでは「マウンティング」という概念がスラングとして広まった際に、格闘技用語由来の「マウントポジション」や「マウントをとる」という表現と混用されるようになったのだとみている。初出の用例は明らかにニホンザルのマウンティングと表現されており、生物学的な用語としての「マウンティング」が由来であることは明らかである。
なんせ、「マウンティング」も格闘技用語の「マウント」も、語源としては当然に英語のmountが由来なのであるから、語形が似ているのも当然だし、混同されやすいのも当然であろう。どちらも上に乗るニュアンスの言葉である。
説を否定するには
以上が筆者の考察結果なのだが、異論がある人もいよう。
古い時代に用例が「ない」ことを証明することは難しく「まだ見つかっていないだけ」の可能性は否定できない。「マウンティング」の発案者がなんらかの既存の表現を剽窃したとするのであれば、その元になったであろう候補を提示しなければ始まらない。
それがみつからないことには、その初出を書いた人が発案者であろうとするのが自然な推定であろう。また、より古い用例が見つかったとして、剽窃があったのか、それぞれ独立に生じた表現なのかは検討が必要である。いずれも、より古い用例を挙げなければいけない。
例えば、2008年以前の「マウンティング」の用例を見つけ出すとか、あるいは2008年以前に格闘技用語の「マウントをとる」という表現を、対人関係で優位をアピールする意味で用いている用例を見つけ出すとか。(注:追記参照。古い用例が見つかった)
ここまで「マウンティング」の発案者は~と、さも他人事のように書いてきたが、当事者主観の証言をするならば、まさにニホンザルのマウンティングに着想してそれを人間関係に転用したものであり、既存の用例を剽窃したものではない。
まあ、私見を言えば独立に誰かがそのような表現を産みだしていても不思議はないと思っている。その時は先行事例こそが初出ということになり、当用例はあくまでも2008年時点でのいち用例という扱いになることだろう。(注:追記参照。古い用例があったようだ)
追記
元記事側ではてブで情報を頂いた
素晴らしい。古い用例を見事に見つけ出して頂いている。
いずれも未読の書である。独立に生じてなんら不思議のない用法であるから、そういう先行事例は筆者が見つけれられていないだけでありそうだなーと思っていた。謎がひとつとけて嬉しい。
筆者の用例はせいぜい「はてなダイアリーでの初出」とかそんなもんだろう。自分が考え付く程度のことは他の誰かも考え付くだろうということの証左になった。
話を少しでも盛るとこんなもんであるし、こうした新情報が得られたときに大事なのは、訂正することである。
諸君 - Google ブックス
1996年
「政界サル山の権力争奪戦で、小沢にマウンティングされた過去があるからだ。」
2005年
「小山の大将やボス猿になりたがるやつっているよね。
(中略)
サルと仕事をするかしないかは
マウンティングの例を書き込んでくれれば
あとは読んだ側が判断すればいいと思う。」
このあたりの用例はまさに猿のマウンティングの比喩であるとみて間違いないだろう。
参考資料
ゲームの歴史とハックルさんとの思い出
思い出話。今回はポエムと思って気楽に読んで欲しい。
インターネットの世界には情報が溢れかえっていて、やれ、なんやらが炎上しただのそんなニュースもありふれていて特に興味もわかない。ふーん、ゲームの歴史について書いた本が噓八百で炎上してんのか、まあ適当なことを書きならべる人がトンデモ本を書きましたなんてのは昔から枚挙に暇がない話だ。
その程度に思っていたのだけども、先日ようやくそのゲームの歴史なる本を書いた人が岩崎夏海氏であったことを認識した。

僕の古い古い記憶が、この人物を知っているぞ、と呼び掛けてきた。そう、あれは2008年のことだった。今から15年も前のことになるのか。
岩崎氏ははてなダイアリー(はてなブログの前身となるブログサービス)ではちょっとした有名人だった。彼はそのblogのタイトルから、ハックルさんと呼ばれていた。よく炎上していた人だったと記憶している。というのも、ハックル氏のblogははてなから消えてしまっていて、過去の経緯をエビデンスをもって示すことが困難になってしまっているからである。その後、ニコニコ公式ブロマガに移って、その際に過去のたくさんの名文を削除してしまった。
いやいや、ハックル氏にとってはエビデンスベースドでどうであったかなんてことを言おうなどというのは失礼か。そんなのはAIがすればよろしい。
歴史書としては偽書の謗りも免れない話だが「ゲームの歴史」という本では、実在人物が言ってもないことを言ったことにされたりしていたようだ。これこそエビデンスベースドの話が面白いエンタメになるわけではないという放送作家の感性なのだろう。そう、岩崎夏海氏は放送作家らしいのである。2008年当時の僕はそのようには認識していなかったけれども。
2008年当時、彼はミリオンセラー作家というわけでもなく、僕にしてみればよく炎上するブロガーという認識だった。炎上でもなんでも話題になれば露出が増えるもので、はてなダイアリーやはてなブックマークをよく使っていた僕は度々彼を、彼の書いたblogを目にすることがあった。僕と彼はその程度の関係でしかなかった。
15年前のその日、僕はblogを書いていた。
《「意見が違うということ」=「喧嘩」という捕らえ方をされた》という話から、議論のあり方とは……といった内容に切り込んでいく。そこで僕はなんのけなしに悪い例として彼のblogを引用したのだった
どちらが勝ったか負けたかということを意識しているのだとしたら、それは議論ではない。だが、世間的には「言い合い」はみんな議論だと思っているふしがある。最近見かけたblogから例を挙げよう。
例えば議論に勝つための初歩的なテクニックというのがある。それは相手のプライドを刺激することだ。人間誰しも矜持というものがある。例えばぼくなら「面白い」ということについては一家言ある。あるいは「言葉」についても並々ならぬこだわりがあったりする。そういうぼくに向かって、「おまえの言ってることは正しいかも知れないけど面白くないよね」とか、「言わんとしていることは分からなくもないけど言葉の使い方を間違ってるから分かりにくいんだ」とか言うともうとたんにカーッとくる。それでペースを乱されて以降の物言いがはちゃめちゃになって結局議論に負けるというのもある。
http://d.hatena.ne.jp/aureliano/20080919/1221753236そんなテクニックはいかに相手のニホンザルを押さえ込んでマウンティングを成功させるかというテクニックでしかない。そんなことをやったところで疑問はなんら解決しないし、誤った意見をこうした手法で押し通しでもした日には、後で大きな惨劇が起こりかねない。勝った負けたなどと言っていても議論は進展しないのである。
議論に勝つテクニックだって?そもそも議論を勝ち負けだと思ってるのかこの人は。そして挙げているテクニックがまた酷い。相手がカーッとなって物言いがはちゃめちゃになって自滅するだって?まさにダメな議論の好例みたいな文章だ!と僕は嬉々として引用した。はてなダイアリーというのはトラックバックという機能があって、平たく言えば引用をすると相手に通知が行く機能と思えば分かりやすいだろうか。
僕のblogに引用されたことはトラックバックによって氏の知るところになったのだろう。氏の反応は素早かった。僕がblogを書いた9月20日その日のうちにアンサーエントリが書かれたのだった。(当時のはてなダイアリーが残っていないのでweb archiveを載せておく)
氏によれば、僕は、《噛ませ犬のように誰かを引き立たせるために、あるいは闘牛のように誰かに屠られるためだけに生まれてきた者》なのだそうだ。
自重した方が良い。本当に自重した方が。ここは誰が見ているかも分からないインターネットなのだ。id:Nagiseがこれまで浸かってきた生ぬるいサークル内での議論ごっこではないのである。
(中略)
ぼくには見える。id:Nagiseが会社の中で、あるいはそれ以外のコミュニティでも、良いようにこき使われているのを。そうして、もう使い物にならなくなった時には、ボロ雑巾のようにポイとお払い箱にされてしまうだろうことを。
しかしそれでも良いのかも知れない。身も蓋もないが、人間社会には、そうした生け贄が必要なのだ。
このエントリは名文だと僕は思う。この文章はなかなかAIでは書けない、魂の叫びのような文章だ。
この人は議論というものを無闇に信用し過ぎている。疑うことを知らないのだ。
なぜ疑うことを知らないか?
それは、自分で考えることを放棄しているからだ。楽をしようとしているのである。「議論」というものの存在価値を無闇に信奉し、そこに寄っかかることで楽をしようとしているのだ。「自分で考える」「責任を持つ」ということから逃げているのである。
議論を信用するからには一般論として当然自ら議論をすることを前提としていることだろう。自ら議論に身を投じることを《疑うことを知らない》《自分で考えることを放棄》《「自分で考える」「責任を持つ」ということから逃げている》と断じるこの論理展開!凄い!
何が彼にこのような支離滅裂な理屈を書かせるに至ったのだろう?当時の僕は気付かなかったけども、ハックル氏によって未来を予言するように書かれていた。
例えば議論に勝つための初歩的なテクニックというのがある。それは相手のプライドを刺激することだ
(中略)
もうとたんにカーッとくる。それでペースを乱されて以降の物言いがはちゃめちゃになって結局議論に負ける
なるほど、プライドが刺激されてカーッときてはちゃめちゃな物言いになったということか。ともあれ、氏のこのアンサーエントリでは結局そもそもの議題であるところの「議論の意義」はなんら進展しなかった。まさに僕が述べたように
そんなことをやったところで疑問はなんら解決しないし、誤った意見をこうした手法で押し通しでもした日には、後で大きな惨劇が起こりかねない。勝った負けたなどと言っていても議論は進展しないのである。
嘆かわしいばかりである。
僕とハックル氏の邂逅は衝撃的なものだった。この邂逅の後、ハックル氏は2009年に「もしドラ」(もし高校野球の女子マネージャーがドラッカーの『マネジメント』を読んだら)をヒットさせ有名作家となる。一方の僕は、この邂逅が大ヒットネットスラングを産むことになるとは想像だにしていなかった。
僕はハックル氏のテクニックとやらを
そんなテクニックはいかに相手のニホンザルを押さえ込んでマウンティングを成功させるかというテクニックでしかない。
と評した。改めて言うが2008年のことである。僕は「マウンティング」というネットスラングの提唱をしたと自負しているが、今の今までそのスラングの産まれた瞬間のことをすっかり忘れていた。
僕が勝った負けたに終始して議論のできない人をニホンザルのマウンティングに例えて評したのは、その対象の第一号は、ハックル氏だったのか!ハックル氏こそ、日本で初めてその行動をマウンティングと評された人物だったのである!!
翌9月21日、僕はblogを書いた。このハックル氏とのやり取りが僕にインスピレーションを与えてくれた。ホモサピエンスもニホンザルのようにマウンティングをする本能を生来、持っているんじゃないだろうか?(これを厳密に科学の俎上で論じるのは難しい。与太話程度に思っていただければ)
議論をしようとしたときに勝ち負けにこだわってしまうこの行為に名前を与えた僕は、それ以来、「マウンティングしてはならない」を議論する際の戒めとした。議論は議題を進展させたいからするのであって、マウンティングのためにやるんじゃないんだよ、そういう思想に行き着いたのだった。
このマウンティングというネットスラングはその後、2014年発行された瀧波ユカリ、犬山紙子著『女は笑顔で殴りあう:マウンティング女子の実態』
https://www.amazon.co.jp/dp/4480815198 によって広く周知された。今では辞書に載るほどである。
2023年3月18日追記
「マウンティング」の初出という話が気になる方が多いようだ。どのような調査をして検証すれば良いのかを記事にしたので、気になる方は検証に参加してみてもらいたい。
リファクタリングの価値の考察
リファクタリングには価値がある、とプログラマは確信していることだろう。しかし、その価値が何であるか?を上手く説明できるかというと難しいのではないだろうか。本稿ではリファクタリングの価値をテーマに筆者の説を提示していく。
品質特性の側面から
ソフトウェアの品質特性としてISO/IEC 9126が一般的に用いられている。大きく6つの特性と細分化された副特性からなり、ISO/IEC 9126 - Wikipedia から引用すると
- 機能性(functionality) - 機能とその特性に影響する特性群
- 信頼性(reliability) - ある状況がある時間続いたときにソフトウェアがどの程度機能するかに影響する特性群
- 使用性(usability) - 利用するのにかかる手間、個人の努力などに影響する特性群
- 効率性(efficiency) - ソフトウェアの性能やそれに要するリソース量に影響する特性群
- 保守性(maintainability) - 何らかの変更を加えるのにかかる手間に影響する特性群
- 移植性(portability) - 別の環境にソフトウェアを移行させる可能性に影響する特性群
となる。これらのうち、リファクタリングの影響を受けるのは主に保守性(maintainability)となるだろう。
ここで「リファクタリング」の定義について振り返っておきたい。リファクタリングのバイブルとされるマーチン・ファウラーの書籍「リファクタリング」からその定義を引用しよう。( ISBN4-89471-228-8 pp.53-54 )
リファクタリング(名詞):外部から見たときの振る舞いを保ちつつ、理解や修正が簡単になるように、ソフトウェアの内部構造を変更させること。
リファクタリング(動詞):一連のリファクタリングを行って、外部から見た振る舞いの変更なしに、ソフトウェアを再構築すること。
この定義からしても、品質特性の保守性をターゲットとしたものであることが分かるだろう。
保守性に含まれる副特性を以下に挙げておく。
- 解析性(analyzability)
- 変更性(changeability)
- 安定性(stability)
- 試験性(testability)
- 標準適合性(compliance)
引用元は旧版である。新装版が出ているので書籍の購入を検討している方は新装版を確認してみて欲しい。
補足 品質特性の相互作用
過去の記事で取り上げているのだが、 ソフトウェア要求 | Karl.E.Wiegers, 渡部 洋子 |本 | 通販 | Amazon という2003年の書籍では「品質属性の相互作用」についての記述があった。品質属性(この書籍は ISO 9126 準拠で記載されていないので用語が異なっているし特性の分類も異なっている点があるので注意)のうち、一方の属性を上げると、他の属性に+ないし-の変化をもたらすことが記載されていた。
この相互作用のISO 9126準拠版が欲しいのだが、ご存じの方がいれば教えて頂きたい。
この書籍の相互作用表では「保守性」と「試験性」が挙げられている。前述の ISO 9126 では「試験性」は「保守性」の副特性という形になっているので注意されたし。
「保守性」が向上した際の相互作用としては、「可用性」「柔軟性」「信頼性」「試験性」に+効果、「効率性」に-効果となっている。
「試験性」が向上した際の相互作用としては、「可用性」「柔軟性」「保守性」「信頼性」「使用性」に+効果、「効率性」に-効果となっている。
本稿では、リファクタリングは「保守性」(その副特性である「試験性」を含む)へと直接作用し、品質特性の相互作用によりその他の特性に間接的な影響を及ぼす、という立場をとる。
よって、間接的な影響を及ぼす「保守性」「試験性」以外の品質特性については本稿では扱わない。読者の方々から検討してくださる方が現れてくださるとうれしい。
リファクタリングの価値
リファクタリングの効果は品質特性でいうところの「保守性」であるということをまず述べた。これはつまり、作った後に「保守」が生じなければ価値がないということでもある。
これはきしださん @kis が
まず、リファクタリングはそれ自体では価値を示せません。人工衛星に搭載するプログラムで、動きだしたらメンテナンスできないようなコードを最後にリファクタリングしたとして、どのような価値を示せるかと考えると想像できるのではないかと思います。
と述べているが、こうした事情を鑑みたものだろう。
障害対応
「保守性」の副特性のうち「解析性(analyzability)」「安定性(stability)」は障害対応などに影響してくる。
ソフトウェアのビジネス的な価値というのは、そのビジネスがどれだけの金を産み出しているかに依存する。おなじ機能のソフトウェアだとしてもA社で使われるのとB社で使われるのでは価値が異なってくるということだ。
A社でそのソフトウェアが機能不全を起こして1日止まった場合、しかしその被害は1万円程度だったとしよう。対してB社ではそのソフトウェアに大きく依存しており1億円の被害となった。同じソフトウェアであるが、その運用保守にかけられるコストはA社とB社で異なってくるだろう。
リファクタリングのコスト < 障害時のダメージ軽減効果
と考えられるなら、リファクタリングを行う価値が十分にある。
障害というのはまず起こるかどうか?が未来の不確定要素であるわけだから、この確率をどうみるかが難しい。このあたりが判断を難しくする理由のひとつだろうか。
また、「解析性」「安定性」を高めて備えておいたことが、備えてなかった場合と比べてどれほどの価値を産んだか?というのも計測が困難である。こうした部分をどう価値判断するか、その価値判断をビジネスサイドとすり合わせることができるかが課題であろう。
機能追加
「保守性」の副特性のうち「変更性」はまさに機能追加といった際のコストとなって現れる。逆説的には機能追加などせず外的要因で動かなくなったならば打ち捨てるという確たる信念で運用しているのであれば、「変更性」などどうでもよい。
筆者はしばしば「技術的負債の踏み倒し」という表現を用いるが、うまく打ち捨てて作り直しをするという戦略がちゃんと回るなら、それはそれで立派な戦略だと考えている。
打ち捨てて作り直しするつもりが、いざ作り直しが必要になったときに金銭的コストにびびって「既存のものの改造で済ませられないか?」と打診するようなのが一番ダサい。そうなった際のコストを度外視することでこれまでコストを削ってきたものを全て台無しにする戦略の一貫性のなさがデスマーチを産み出すのだ。言わんこっちゃない。
機能追加なり改修なりというのは、事前に予見できない性質のものである。あるいはほんのりと「こういうことがしたいなあ」という構想があって備えておくようなケースはあるが、詳細を詰めると事前の準備では不十分というのが通例である。また、構想が日の目を見ず、備えてあった拡張性が役立つことなく製品寿命を終えることも少なくはない。
ここでも確率論がでてくる。コスト算定がしにくい理由のひとつだ。ごく簡単には
リファクタリングのコスト < 機能追加のコスト軽減効果
ということになろうが、この「機能追加のコスト軽減効果」が容易に算出できない。
また、需要と供給の話で良く出てくる需要曲線・供給曲線とその交点の話があるが、システムの機能追加の話でも似たようなものがあり、品質特性「変更性」が高いとなると機能追加しようとしたときのコストが下がる。供給曲線そのものが全体に下にさがるわけで、ならば買おう、という判断になったりするわけである。
(この例えが微妙なところは横軸が需要曲線・供給曲線では数量であるところが、システムの話にしようとしたときに横軸はなんだっけ?となる点である。より工夫が求められる。何かアイデアがあればご提示いただきたい)

つまり、単に機能のビジネス的価値と、製造原価が折り合うか?という話から、そもそも製造原価そのものが下がっていたら?という話が混ざりこんでくるので複雑になる。
この製造原価を下げる効果、いろんな機能追加がビジネス的に採算に乗りやすくなってくるわけだから、ユーザー要望に対する即時性を備えたいならば必須となろう。逆に、10年以上の安定稼働を前提とした生活インフラ系の保守管理用のシステムのような機能追加・改修みたいなものをあまり求められないシステムのような例だと、こうした部分に言及してアピールしても顧客にはその価値が響かない。
これがB2Cシステム(Business to Customerの略で企業と一般消費者の取引のこと)だと、ユーザーの反応を見て素早い対応をすることが強く求められるので、最初からある程度の「変更性」を備えたプロジェクト運用をしていないとユーザー満足度を高められない。日頃からの不断のリファクタリングによって「変更性」をキープし続ける必要がある。
それでも劣化して「変更性」が失われてくると、ユーザー要望への追従が出来なくなり、そうしたサービス品質の低下がユーザー離れを加速し……といった負のスパイラルに入ることがある。資本力があれば、そうしたタイミングで抜本的な対策として大規模な作り直しが行われることがある。こうした「システムの製品寿命」がどれぐらいか?というところに「変更性」が関わってくる。
システムの製品寿命
システムというのは、初期に大きく資本を投じてわーっと作り、その後は細々と保守運用フェーズになるというライフサイクルが多い。
単純な例となるが、10億投じてシステムを作り、5年運用したところで「変更性」が失われビジネス要件の追従が限界であるとして新システムを作るという話になるのと、これが10年メンテしながら運用できるのでは、10年もった方がお得である。
イニシャルコスト(初期コスト)を運用年で割って、単年度あたりに慣らすと、5年運用なら年度あたり2億円だし、10年運用なら1億円だ。
このようにシステムの寿命を延ばすという点で「変更性」や「試験性」が効いてくるわけである。これらの価値がいかほどか?ということになると、結局のところそのシステムを使った場合のビジネスがどれほど金を産むかに依存する。
大金を産み出すシステムであれば、できるだけ長く運用し続けたい。しかし、システムと言うのは外的要因で使えなくなったりすることもある。例えば税制が変わったりとか、セキュリティ上の理由で採用していたプロトコルが使えなくなって新プロトコルに切り替えなくてはならないとか。PCが廃れてスマホに対応しないといけなくなった、なんてのは2010年代にあったムーブメントである。こうした世間の動向もシステムの寿命を縮める外的要因である。
しかし、十分に「変更性」が高ければこうした変更についていける。こうした事態のたびにシステムをいちから作り直すのに比べればコストは安く済むはずであるし、対応までのリードタイムも短くて済むことだろう。そうした「価値」に「保守性」はつながっているし、その「保守性」に「リファクタリング」は繋がっている。
まとめ
- リファクタリングは品質特性の「保守性(maintainability)」に作用する
- 保守性の価値は、システムのビジネス上の価値と関係している
- ビジネス上の価値や未来の可能性みたいなものが関連してくるので価値の算出は容易ではない
- 筆者の説は叩き台のようなものであるから、不備の指摘や異論を提示してもらえると、このテーマについてみんなの理解が深まるのではないか
なぜ自動テストの導入は失敗するのか?
開発室の雑談。営業側のマネージャが言うには
「今のプロジェクトで自動テストの導入を試みている話をしたら、XXXさんのところでも過去にいくつか導入を試みたけどもみんな上手くいかなかったって話になって」
なるほど?
まあ確かに自動テストはシステム開発にとって魅惑の技法ではあるものの、では導入がうまくいっているか? というと普及率は低いと言わざるを得ない。私がお手伝いしたプロジェクトでは、元請け側から自動テストをやるお達しが来たわけだが、紆余曲折あって掛け声倒れのような状態になってしまった。
ビジネス書の煽りタイトルのような本件だが、古式ゆかしき受注生産の業務システム開発プロジェクトに自動テストを導入しようとして失敗する事例を聞いたので、僕なりに分析して見出した要素を挙げておこうと思う。
V字モデル
ソフトウェア開発の手法としてV字モデルというものがある。
オーダーメイドでシステムを作るにあたって、どのような要求があるか、どう設計すればよいか、それを段階を踏んで細分化・詳細化していき、プログラムのコーディングに至り、そして単体テスト、結合テスト、とパーツ単位の検品からその組み合わせとしての試験、といったように進めて成果を上げていくわけである。
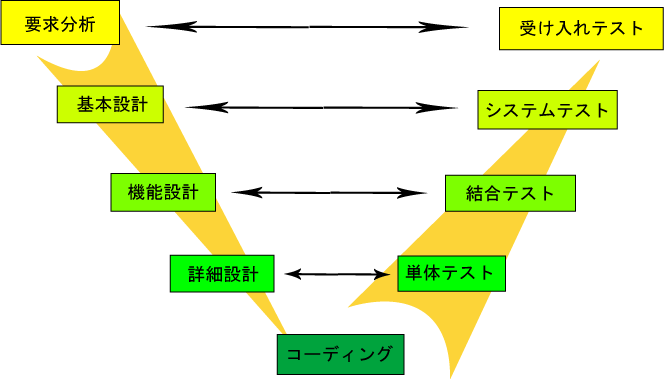
CC 表示-継承 3.0, https://ja.wikipedia.org/w/index.php?curid=894431
このV字モデルと、いわゆるウォーターフォール開発(定義や本来の意味は?といったことに踏み込むと難しいのでここでは触れない)において、自動テストの導入のネックとなるのはなんであろうか?
自動テストとは?
自動テストとはこの文脈ではコンピュータ・プログラムが想定通りに動くかテストする工程を自動化するものだが、自動化といってもピンとこないかもしれないので簡単に触れておこう。全自動のコンピュータが何とかしてくれるという話ではない。
例えば、ふたつの数字を渡すとその和を返す機能を考えてみよう。
public int add(int x, int y) { … }
これを試験する場合、ふたつの数字x, y にさまざまな値を渡して、得られる答えが期待通りかを確認することになるだろう。
- 1, 2 を与えれば 3
- -1, 1 なら 0
- -2, -3 なら -5
といった具合に。とはいえ、ひたすら並べていってもバグ検出の効果が薄いので、特徴のあるテストケースを用意するなどの工夫は必要だ。まあ、その辺の話も割愛。
ともかく、こうした入力と出力があって、それが予見可能であれば、プログラムを呼び出してそういう値になるよな? ということを確認するプログラムが書ける。
assertEquals(3, add(1,2)); assertEquals(0, add(-1,1)); assertEquals(-5, add(-2,-3));
こうした検証のためのプログラムが2021年時点のIT界隈で「自動テスト」と呼ばれるものの本体であって、「自動テストの導入」というのはこうした検証用のプログラムを書くことに他ならない。
つまり、本来のプログラムのほかに、その検証用のプログラムを別途用意するというわけである。
この検証用プログラムがうまく作れれば
- 以後のテストは検証用プログラムを実行するだけで済む
- 人力で膨大なテストを行うのに比べればコストダウンできるだろう
- テストフェーズのリードタイムが短くなるだろう
- 人力に比べヒューマンエラーが抑えれるだろう
- 上記の総合的な作用により品質が向上するだろう
ということを夢見ていくつものプロジェクトが玉砕してきたというわけだ。
テスタビリティ
先の自動テストのための検証用プログラムは非常に簡単な例だった。
しかし、世の中にはテストしにくいプログラムというものがあって、検証用プログラムを書くことが非常に難儀することがある。ここでテストしやすさ、テスタビリティ(testability)という概念が出てくる。
テストしにくいとはどういうことか? いろんなケースがあるが、テストしにくいモノのひとつには「状態を持つ」プログラムが挙げられる。
工学系の学部などで科学の学生実験とかやらされた人は身に染みていると思うが、「同じようにやって同じようになる」ためには、前提が揃っていることが大事である。
状態を持たないプログラムを対象にして自動テストのための検証用プログラムを書くことは簡単である。同じ値をつっこめば、いつも同じ値を出力する。 1 + 2 = 3 であり、冪等(べきとう、何度繰り返しても同じ性質)である。
しかし、内部で状態を持つプログラムは同じように操作したつもりでも突然違う挙動を示す。電卓でボタンを順に 1, +, 2, = と押した場合、3と表示されるだろうか? そのテストを始める前に誰かが 5, + と入力した状態から始めたらどうなるだろう? 期待される答えである 3 ではなく、8 が表示されてしまう。
状態をもつプログラムのテストしにくさはこういうところで出てくる。まあ電卓の場合はCボタンを押してクリアしてからスタートすればいいわけだけども、じゃぁデータベースはどうしたら良い? データベースにリセットボタンが必要になってくる。データベースにテスト用のリセットボタン、用意してありますか?
これは一例でしかないが、テスタビリティというのはなんとなくで上がる話ではなくて、テスタビリティを上げるための技法を駆使しなくては上がらないということの一端が分かっていただけただろうか。V字モデルでいえば基本設計、機能設計、詳細設計といった設計の工程で、あらかじめテスタビリティを上げるための配慮した設計をしておかねばならない。
自動テストはいつ作られるのか?
冒頭に挙げたV字モデルの概念図では、要求分析に始まり、基本設計、機能設計、詳細設計と細分化してからコーディングを行い、単体テスト、結合テスト、システムテスト、受け入れテストと進んでいくように描かれている。
オーダーメイドでシステムを作ろうとした際、こうした工程を経てシステムを作りましょうという提案がされることが多いことだろう。
では、「自動テスト」を導入するとした場合、自動テストはこのV字のどこで作られるのだろう?
単純に手動での単体テストを置き換えるものと位置付けるのであれば、V字モデルの「単体テスト」のフェーズで自動テストを作成するということだろうか? プログラムを一通り作り終えて、単体テストフェーズに移りましょう!というタイミング?
😩😩😩
この案、聞いただけでうんざりした顔をした人も多いのではないだろうか。
「導入を試みたけどもみんな上手くいかなかったって」
そりゃそうだろう。うまく行くわけがない。
いわゆるウォーターフォール開発の手法によって、書類で工程を分離して記録を残すやり方だと、設計フェーズと、コーディングと、テストフェーズは明確に分かれている。「分離することで上手くやってきた」と語る人もいることだろう。
そうか、これが大きな阻害要因だったか。
自動テストが破壊するもの
自動テストにはプログラムを「部分的に実行する」という意味合いもある。プログラムを書いて、動かしながら、その動きが狙い通りか確認しながら仕上げていく。この「動かしながら」のためには巨大システムの一部のパーツを、その一部分だけで動かす技法が必要で、自動テストのためのテスティングフレームワークがその答えの一つだ。
プログラムを書きながら、自動テストのための検証用プログラムもまた並行して書いて、自動テストを用いることでプログラムを実行しながら進めていくというスタイル。その究極はTDD(テスト駆動開発)だけども、そうでなくともコーディング中から自動テストを書くのが良いやり方だ。
早めに動かして、早めにバグを検出できるならそれに越したことはない。
しかし、これはV字モデルにおけるコーディングフェーズと、単体テストフェーズを曖昧にする。従来のV字モデルのやり方で、明確に分離された単体テストフェーズに自動テスト作成を試みるようでは、自動テストの効能が十全には発揮されない。自動車を買って馬につないで牽かせるような話だ。
また自動テストは、いかようなプログラムにも後付けで用意できるわけではない。これは先にテスタビリティの部分で解説した。自動テストをやるには自動テストしやすい設計である必要がある。極力ステートレスにするとか、モックに差し替えが可能なようにDIコンテナを駆使するとか。そこにはいろんな技法があって、そうした技法を凝らすことでシステムを自動テスト可能となるよう、先人たちが工夫を重ねてきた。
それでも、より具体的なプログラミングを行っていると、後になってから「これはあっちに持って行ったほうがいいな」ということは多発するし、自動テストのために設計変更したくなることも生じてくる。これはV字モデル的にはコーディングフェーズから詳細設計フェーズへの手戻りだ。
また、自動テストの効能のひとつに「リファクタリングを可能にする」という大きなポイントがある。詳細設計フェーズとコーディングフェーズの分離はこの開発時のリファクタリングを大きく阻害する。
自動テストを活かすには、詳細設計フェーズとコーディングフェーズが分離されていてはいけない。コーディングフェーズと単体テストフェーズが分離されていてもいけない。
自動テストの導入のためには
本稿の主張は、V字モデルこそが自動テストの阻害要因であるというものである。であるから、V字モデルに拘泥する限り、自動テストの導入は成功率が低いし、よしんば導入できたとしても効果が低く成果が上がらないものとなるだろう。
おそらく、V字モデルでいうところの詳細設計~コーディング~単体テストのフェーズを再考する必要がある。この部分を大きく改革しないと自動テストの恩恵を得ることは難しいだろう。
ある程度のスキルレベルにあるメンバーで行われるプロジェクトであれば、この詳細設計~コーディング~単体テストの一連の工程を、プロジェクトメンバーがうまいことやってくれていた。しかしこれは、そういう練度のプログラマで構成されたプロジェクトであればこそだろう。
となれば。より低スキルの寄せ集めメンバーでベルトコンベアの流れ作業のようにシステムを作ろう! という思想でやるのであれば。少なくとも旧来のV字モデルの詳細設計~コーディング~単体テストに変わる新しい分業モデルを検討しなくてはならないはずだ。
修正履歴
- 2021/04/29 自動テストのコードの値の誤りを修正
Javaのリテラル
コーディング規約「リテラル禁止」
— なぎせ ゆうき (@nagise) April 16, 2021
「null書くなって事ですかねw」
「えっ?」
「えっ?」
Q. リテラル(literal)とは何か?
A. 言語による
なんでこんな記事を書いているかというと、リテラル禁止FizzBuzz大会がいまいち盛り上がらなかったので、ルール解説をして参加者を増やそうという目論見である。
リテラル禁止FizzBuzz大会、開幕!(待て https://t.co/zpIirtNpmO
— nishio hirokazu (@nishio) April 16, 2021
Java言語におけるリテラル
コンピュータプログラミング言語においてリテラルは、ソースコード内に値を直接表記したものをいう。言語によってリテラルとして表記できる型の種類や表記方法は異なる。
という感じで、 42 とか "hoge" とかそういう値を直書きしたものを言う。このあたりは雰囲気で把握している人も多いだろう。ではその明確な範囲としてどこまでがリテラルか?となると、言語ごとのルールブック、つまるところ言語仕様に当たらなければならない。
Java言語仕様は怖くない。インターネットでオープンにされており、非常にアクセスしやすい。 Java SE Specifications のページに各バージョンの言語仕様へのリンクがまとめられている。
2021年9月には次期LTS(長期サポート)版のJava17がリリースされるが、本稿執筆時点でのLTSはJava11なのでJava11の言語仕様を元に調べてみよう。
物事を調べるには原典にあたることが大事である。原典をみて誰かが本を書いたりblogを書いたりする。それを見て書かれたblogは原典を見たものより信頼度が落ちる。孫引きして書かれた引用元も示されてないような記事を信頼してはしてはいけない。
"The Java Language Specification, Java SE 11 Edition" の "HTML"のリンクを辿ると The Java® Language Specification Java SE 11 Edition の目次に辿り着ける。
リテラルについて書かれているのは 3.10. Literals の部分だ。Java言語仕様は英語で書かれているが、現代は機械翻訳が優秀なので、機械翻訳でもある程度概要をつかむことができるのではないだろうか。また過去には公式に日本語訳がされたものが出版されたこともあるが、Java5の内容の
Java言語仕様-第3版 (2006年)が出たのが最後となっている。
Literal:
IntegerLiteral
FloatingPointLiteral
BooleanLiteral
CharacterLiteral
StringLiteral
NullLiteral
と列挙されていて、各項目の説明が以下に続く。
各リテラルの詳細な定義まではここでは立ち入らないが、ざっくりと表にすると
| 種類 | 概要 | 例 |
|---|---|---|
| IntegerLiteral | 整数の数値 | 42 0xCAFEBABE 0b0010_1111 |
| FloatingPointLiteral | 浮動小数の数値 | 1.234 |
| BooleanLiteral | boolean型の値 | true false |
| CharacterLiteral | charの値 | 'A' |
| StringLiteral | 文字列 | "hoge" "" |
| NullLiteral | null | null |
といった感じ。
また、 3.10. Literals に記載されていないが 15.8.2. Class Literals という項目があって、classリテラルについて記載がある。これも Java言語における「リテラル」に含めそうだ。
これは Hoge.class などといったように、クラス名に .class とつけることで java.lang.Class オブジェクトをリテラルとして表す記法。
リテラルを使わないでFizzBuzzをしてみよう!
さて、以上でJavaにおける「リテラルの禁止」の指す範囲が明確になったと思う。
プログラミングパズルが好きな人は是非、リテラルを用いないFizzBuzzに挑戦してみて欲しい。たぶん、セミコロンを使わないFizzBuzzよりは簡単じゃないかな。(参考: セミコロンレスJava はチューリング完全か? - プログラマーの脳みそ )
セミコロンレスJavaもそうだが、この手のプログラミングパズルは標準APIの範囲で行うことが暗黙の了解となっている。
僕も書いてみたけども芸術点がイマイチなのでまだ満足できていない。
空気を読んだ話
一般に「リテラルを使うな」というのはプログラムコード中にマジックナンバーなどを直接記載しないということを意図したものである。なんらかの意味のあるフラグの値などは定数定義(Javaの場合はstatic finalフィールドにするかenumにすることが多いかな)して間接的に用いることを指す。
言語仕様上のリテラルを一切用いないというのは揚げ足取り的な話で、しかしここではネタとしてその制限でプログラミングを書けるか?という設問がおもしろいので取り上げている。
訂正
2021.04.19 BuzzをBullと誤っていた箇所があったので修正