2004年ごろに Google の猫で深層学習が一躍脚光を浴びたとき、画像認識は特徴抽出が難しいので深層学習で良い結果が出るが、自然言語処理は特徴量*1がリッチなので、深層学習を適用するのは難しいだろうと思っていた。
特徴量がリッチとは、例えば「ホームラン」のたった1語でその文はスポーツ、特に野球の話題である可能性が高くなる、みたいな話である。一方、ピクセルの1つが緑であることから何の画像か当てるのは不可能だ。
その後、自然言語処理でも深層学習が当たり前になったのは誰もがご存知のとおりであり、自身の不明を恥じるばかりだ。ただ言い訳をさせてもらえるなら、自然言語処理のえらい先生方も同じように言っていたのだ。
どれほど難しいと言われていたタスクでも、一度でも解けることを誰かに示されれば、次からは他の人も同じレベル以上でそのタスクを解き始めるものである(場合によっては他の方法を使って)。つい最近も、テキストからの画像生成でそれを見たばかりだ。
つまり ChatGPT レベルの AI が今後続々と登場することが予想できる。今は汎用の ChatGPT(とその眷属)しかないが、いろんな特徴を持った AI や、専門分野に特化した AI が登場するわけだ。今は遅かったり不安定だったりする AI のレスポンスも、きっと日常使いに耐えるレベルに向上するだろう。
Large Language Model は世界の知識を獲得できることが示され共通認識となりつつあるが、同様に「知能のエミュレーション」も獲得できることが ChatGPT によって示された。そしてサールの中国語の部屋は、知能と「知能のエミュレーション」を区別できないことを表している(サールの言いたかったことは逆だが*2 )。
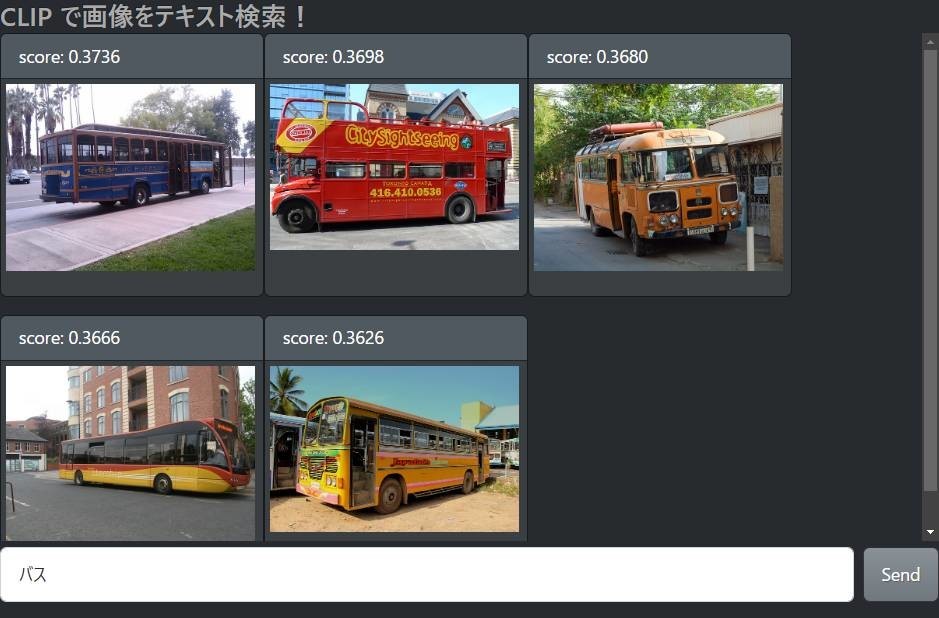
これくらいなら Google Photos の画像検索でもできそうですが、実際やってみると「確かにバスも写ってはいるけど……」みたいな写真がヒットすることも多いです。
物体検出ベースの検索の困るところ(VRC-LT の発表資料より)
Google Photos のような物体検出による画像検索は、基本的にその物体が画像に入っているかいないかだけを情報として取得して、それをもとにしたインデックスを検索しているので、こうした問題が生じます。つまり「バスの写真」ではなく「バスが写っている写真」を検索しているわけですね。
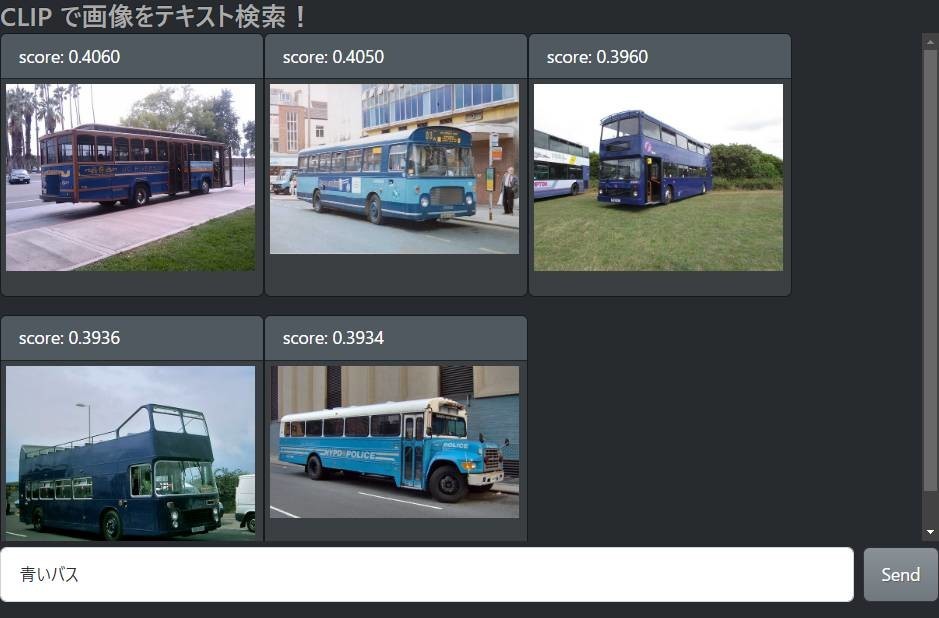
他にも、物体検出があらかじめ想定しているキーワード以外や、「青いバス」「寝ている猫」では検索できません。
さて、CLIP を使った潜在ベクトル検索はどうでしょう。
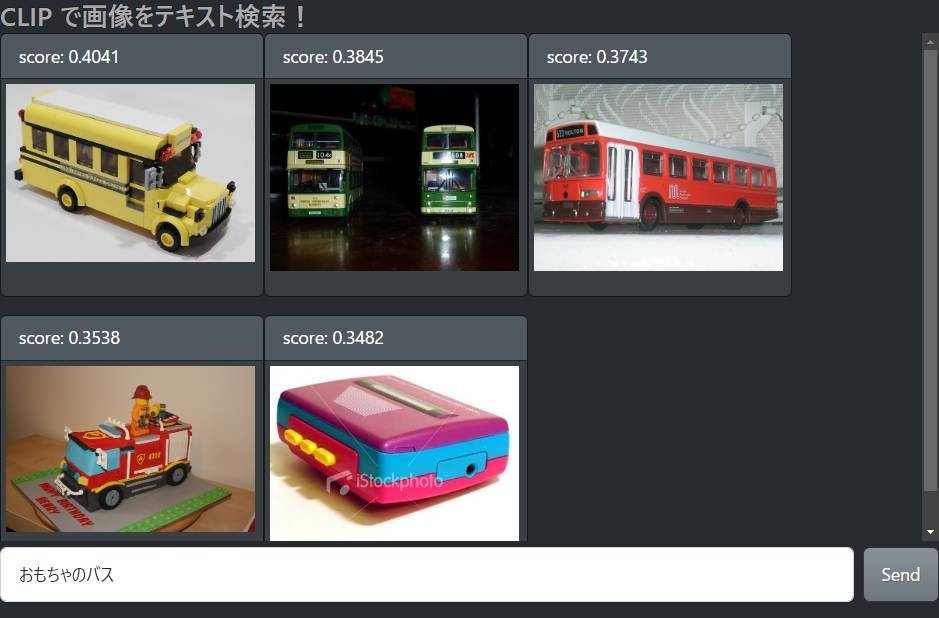
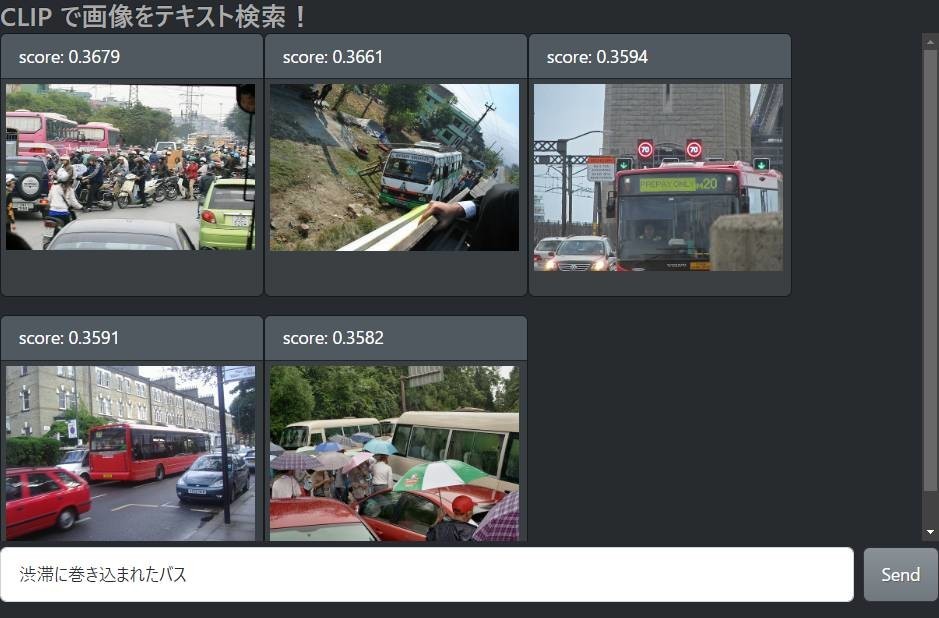
「青いバス」の検索結果「おもちゃのバス」の検索結果「渋滞に巻き込まれたバス」の検索結果
期待以上にいい結果が得られてホクホクしてしまいます。
他の検索結果例については、冒頭の資料 or 録画をごらんください。
深層学習の実験をするには、十分な性能の GPU を積んだ PC が必要です。
今どきの機械学習関連の研究室では、院生有志がメンテナンスしている GPU のクラスタがあって、それを使わせてもらえることが期待できます。自分用の PC を手配する場合も、研究テーマに適したマシンの選択について教授や先輩が相談に乗ってくれるでしょうし、環境構築&運用のノウハウもバッチリです。
しかし非情報系だと、そんな環境も相談相手もおそらくないでしょう。予算だけ出すから自分でマシンを選定するように、ってところでしょうか。環境構築も自分でググって手探りでやってみるしか。
ということで、前回の記事と同じくあくまで私見ですが、あまり後悔しなくて済むだろう深層学習用の PC 選びと環境構築の第一歩を書いてみます。
OS は Linux を割と強めにおすすめします。
tensorflow や pytorch といった深層学習のライブラリ自体は Windows や Mac にも対応していますが、配布されているモデルを動かすには、それ以外のプログラムをビルド(プログラムのソースファイルから実行ファイルを作成する作業)する必要があって、それが Linux にしか対応していない(あるいは Windows/Mac で動かすのが面倒)ということが少なくありません。
また深層学習を使った研究における第一級の必需品と断言したい nvidia-docker2(後で説明) を動かすのは Linux が一番楽です。 Linux のディストリビューションは、CUDA が対応しているものならどれでもいいです。困ったときにググると情報が多く見つかるのは Ubuntu か CentOS*7 でしょう。
どうしても Windows がいいという場合、nvidia-docker2 を Windows で動かすのは大変なので、docker を使わずに深層学習するほうが楽でしょう。逆に言えば、docker を使わないなら Windows でもなんとかなります。nvidia-docker2 を使わないのはまあまあ大きなハンデになりますが。
どうしても Mac がいいという場合、以前なら Intel Mac + NVIDIAGPU という選択肢もありました。でも NVIDIA は Mac OS での CUDA サポートを 2021年に終了してしまいました……。「Mac でする苦労は大歓迎」という人以外は、M1 や M2 で安心して深層学習ができると定評が得られるまで待ったほうがいいでしょう。
見えている範囲からの勝手な推測なので間違っているかもしれませんが、非情報系の研究室の方々も深層学習は大きな鍵になる予感を持っていて、でもノウハウが無いから自発的に声を上げた学生さんに期待を寄せているという雰囲気を感じます。
その期待の表れでしょうか、深層学習研究用の PC を購入する予算が、論文執筆用のノート PC レベルではなく、それなりの GPU を積んだゲーミング PC レベルでちゃんと支給されている、という認識。
つまり、PC を買うか買わないかという問題はすでにクリアして、何を買うかという問題に移っているわけです。
Linux や docker は身につけたことが他でも役立つ、いわゆる「つぶしがきく」ので、そこでの苦労は報われるチャンスが多いです。
一方 Google Colab をホームグラウンドとして真面目に深層学習研究しようと思ったら、セッション切れ対策など Google Colab 固有のノウハウが必要になり、これは他の場所では基本的に役立ちません。 Google Colab は共有には手軽で便利ですが、初手の選択肢としては難点も多いかなあ、というのが個人的な感想。
……と書くと完全に身もふたもないですが、まあ考えてみてください。
例えば、自分のデータを機械学習のモデルに食わせた実験結果を見て、「training loss が中途半端に下げ止まっているから、実装が間違っているか、モデルの表現力が足りないか、途中の層で特徴が潰れているか、訓練データにゴミが入っているか」と機械学習の立場から分析した上で、それらの切り分け方法を一緒に考えてくれる人がいるときと、いないときを想像して、いなかったときにそれを補う方法が果たしてあるだろうか、と。
今回ラボユースで、天文学の学生さんの研究をメンタリングして、domain specific なデータそのもののおもしろさ、そのデータを機械学習のモデルと突き合わせて、お互いを調整するおもしろさにとても刺激的でした。 天文学に限らず、機械学習から遠い分野の研究からの応募をお待ちしています。もちろん普通の自然言語処理や画像処理もね!
一番明確なところを例に上げると、注意12(p36-37)には、分子分母にパラメータ集合 W 上で定義された関数を含む数式を受けて「本書では W としてコンパクト集合を考えていくので、その場合にはこの式は分母、分子ともに有限の値を取る」*1とある。この記述からその関数はおそらく連続なのだろうと推測できるが、この本では関数が連続かどうか全く触れられておらず、暗黙の仮定となっている。
まあこのくらいわかりやすかったら書いてなくても忖度できるのでなんとかなるんだが*2、2章の補題4(2)はそれがわからなくて困っている。
本では にも にも何の仮定もない。
W にもなにもないが、実は先の注意12はこの補題4(2)の証明を の近傍で考えればよいということを言っていた。よって、命題には書かれていないものの W にはコンパクト性が仮定されていると思われる。
この状態で本に書かれている補題4(2) の証明のアウトラインを追いかけて、「ここ何の仮定もないと成り立たないよね」という部分を拾っていくと次のような反例が構成できてしまった。